ModernBERT
- Warner, B., Chaffin, A., Clavié, B., Weller, O., Hallström, O., Taghadouini, S., … & Poli, I. (2024). Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference. arXiv preprint arXiv:2412.13663.
- 2024-12-19 Hugging Face Finally, a Replacement for BERT
如同字面意思, 更现代的 BERT, 更快更强而且 context length 拓展到 8k tokens, 也是首个在训练数据中加入大量代码数据的 encoder-only 模型. BERT 系模型对比 LLM 的优势是快, 便宜, 而且很多任务适用 encoder-only 结构.
性能
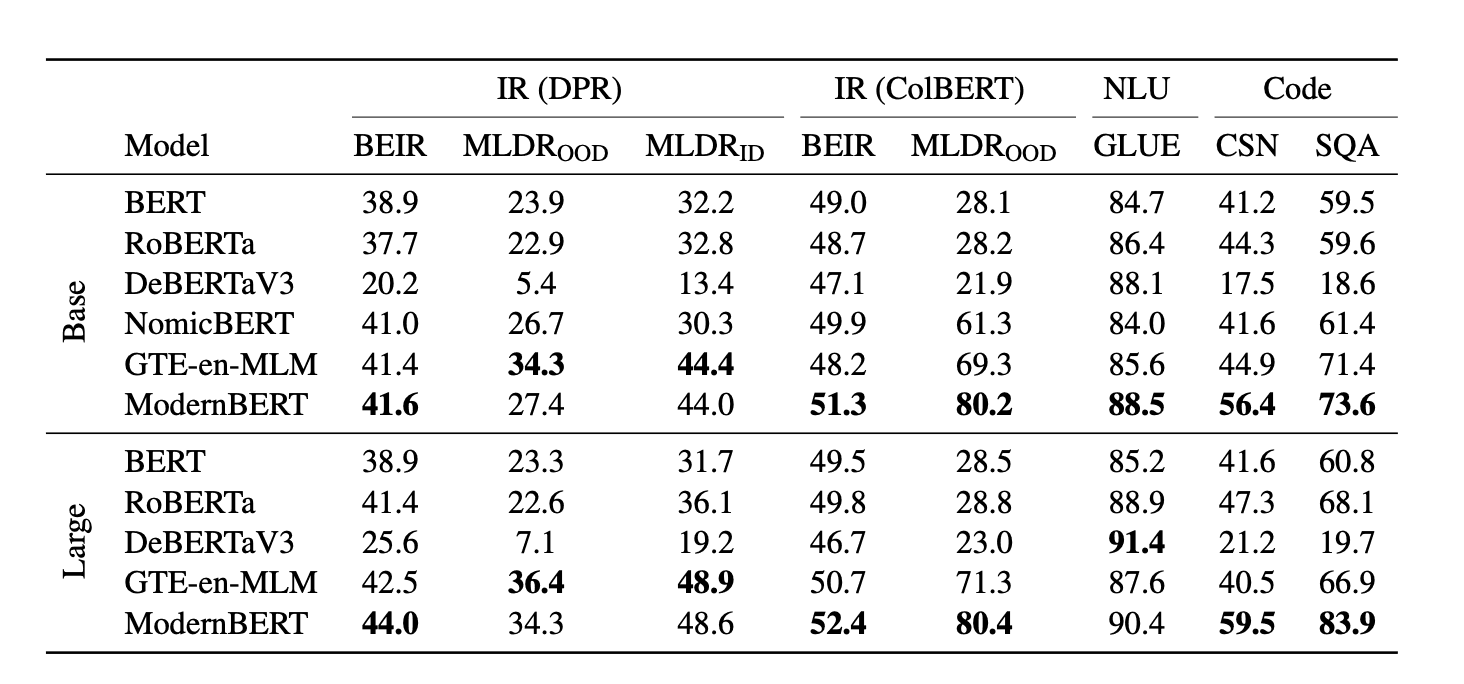
ModernBERT 不仅是首个在 GLUE 中打败 DeBERTaV3 的 base-size 模型, 而且其内存使用量不到 DeBERTa 的五分之一. 速度也是 DeBERTa 两倍, 输入混合长度序列时最高可达到四倍.
Here’s the memory (max batch size, BS) and Inference (in thousands of tokens per second) efficiency results on an NVIDIA RTX 4090 (在消费级显卡上考虑性能) for ModernBERT and other decoder models:
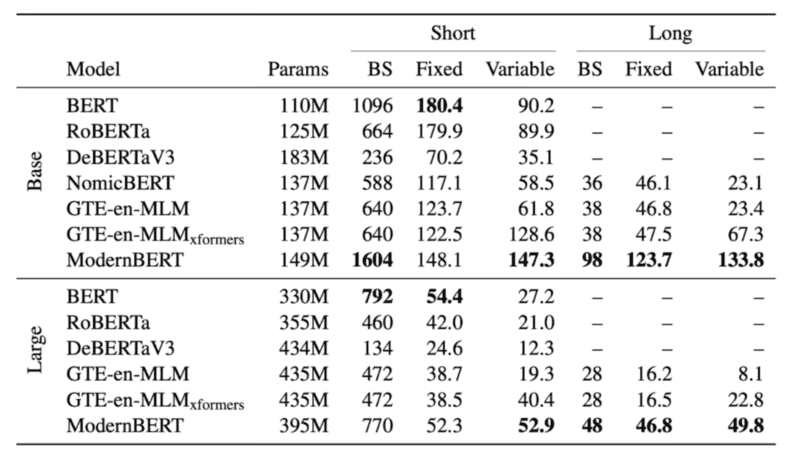
On short context, it processes fixed-length 512 token inputs faster than all other recent encoders, although slower than the original BERT and RoBERTa models. On long context, ModernBERT is faster than all competing encoders, processing documents 2.65 and 3 times faster than the next-fastest encoder at the BASE and LARGE sizes, respectively. On variable-length inputs, both GTE-en-MLM and ModernBERT models are considerably faster than all other models, largely due to unpadding.
Why modern?
Even more surprising: since RoBERTa, there has been no encoder providing overall improvements without...
剩余内容已隐藏