LoRA 变体
LoRA
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., … & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
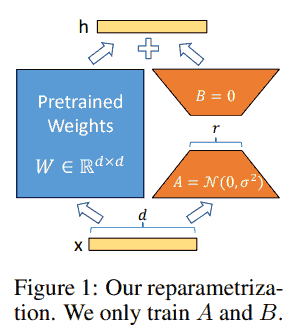
众所周知了, 略 (可以参考 这里).
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”.
We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules
QLoRA paper: “We find that the most critical LoRA hyperparameter is how many LoRA adapters are used in total and that LoRA on all linear transformer block layers is required to match full finetuning performance.”
初始化时 A 或 B 其中一个为零保证加了 AB 之后一开始的输出和原输出相同, 另一个非零保证优化过程中梯度不会恒为零.
注意 LoRA 并不省计算量, 只是大幅度节省了优化器需要存的参数, 可参考 这里 和 这里.
GaLore
- Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., & Tian, Y. (2024). Galore: Memory-efficient llm training by gradient low-rank projection. arXiv preprint arXiv:2403.03507.
Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory efficient than common low-rank adaptation methods such as LoRA.
Our key idea is to leverage the slow changing low-rank structure of the gradient of the weight matrix...
剩余内容已隐藏