InnoDB的锁
什么是锁?
锁是数据库系统区别于文件系统的一个关键特性,锁机制用于管理对共享资源的并发访问。
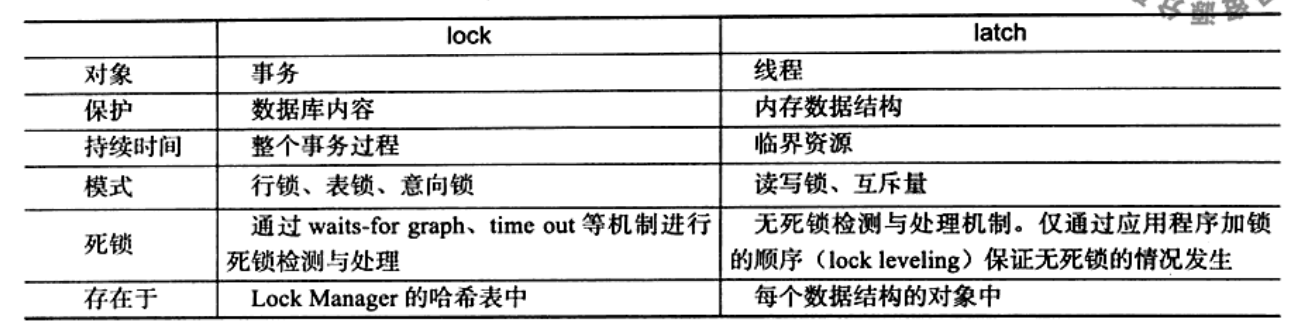
lock和latch
latch一般称为闩锁,因为其要求锁定的时间必须非常短,则应用的性能会非常的差。在InnoDB存储引擎中,latch由可以分为matuex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检查机制。
lock的对象是事务,用来锁定的是数据库中的对象,如表、页、行。并且一般lock的对象仅在事务commit或rollback后进行释放。此外lock是有死锁检查机制的。
InnoDB存储引擎中的锁
锁的类型
InnoDB存储引擎实现了两种标准的行级锁:
- 共享锁(S Lock),允许事务读一行数据
- 排他锁(X Lock),允许事务删除或更新一行数据

InnoDB存储引擎支持多粒度锁定,这种锁定允许事务在行级锁和标记锁上的锁定同时存在。为了支持不同粒度上进行加锁操作,InnoDB存储引擎支持一个额外的锁方式,称为意向锁。意向锁是将锁定的对象分为多个层次,意向锁意味着事务希望在更细粒度上进行加锁。
InnoDB存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。设计目的主要是为了在一个事务中揭示下一行将被请求的锁类型。其支持两种意向锁:
- 意向共享锁(IS Lock),事务想要获得一张表中某几行的共享锁。
- 意向排他锁(IX Lock),事务想要获得一张表中某几行的排他锁。
一致性非锁定读
一致性非锁定读是指InnoDB存储引擎通过多版本控制的方式来读取当前执行时间数据库中行的数据。如果读取的行正在执行DELETE或UPDATE操作,这式读取操作不会因此区等待行上锁的释放。相反的,InnoDB存储引擎会区读取行的一个快照数据。快照数据是只该行的之前版本的数据,该实现是通过indo断来完成,而undo用来在事务中回滚数据,因此快照数据本身是没有额外的开销。此外,读取快照数据是不需要上锁的,因为没有事务需要对历史的数据进行修改操作。这种并发控制,其实就是多版本并发控制MVCC。
一致性锁定读
在默认的配置下,事务的隔离级别为可重复读,innoDB存储引擎的select操作使用一致性非锁定读,但是在某些情况下,用户需要显示地对数据库读取操作进行加锁一保证数据逻辑地一致性。而这个时候就需要数据库支持加锁语句。InnoDB存储引擎对于select语句支持两种一致性地锁定读操作。
select … for update(对读取地行加一个X锁)
select …lock in share mode(对读取地行加一个S锁)
自增长与锁
在InnoDB存储引擎地内存结构中,对每个含有自镇长只地表都有一个自增长计数器。档含有自增长计数器地表进行插入操作时,这个计数器会被初始化。插入操作会根据这个自增长地计数器加一赋予自增长列。这个实现方式叫 AUTO-INC Locking.这种锁其实是采用一种特殊地表锁机制,为了提高插入地性能,锁不是在一个事务完成后才释放,而是在完成对自增长值插入地SQL语句后立即释放。
外键和锁
外键的主要用于引用完整性的约束检查,在InnoDB存储引擎中,对于一个外键列,如果没有显示地对这个列加索引,InnoDB存储引擎自动对其加一个索引,因为这样可以避免表锁。
对于外键值地插入或更新,首先要查询父表中地记录,即select父表,但是对于父表的select操作,不是使用一致性非锁定读的方式,因为这样会发生数据不一致的问题,因此这时使用的时select … lock in share mode方式,即主动对父表加一个s锁。如果这时父表上已经加了x锁,子表上的操作会被阻塞。
锁的算法
行锁的三种算法
InnoDB存储引擎有三种行锁的算法,其分别是:
- Record Lock:单个行记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- Next-Key Lock:Gap Lock+record Lock,锁定一个范围,并且锁定记录本身。
record lock总是会区锁定索引记录,如果innodb存储引擎表在建立的时候没有设置任何一个索引,那么这时InnoDB存储引擎会使用隐式的主键来进行锁定。
解决幻读问题
幻读问题是指在同一事务中,连续两次同样的sql语句可能导致不同的结果,第二次的sql语句可能会返回之前不存在的行。InnoDB存储引擎采用Next-Key Locking的算法来避免幻读问题。
死锁
死锁的概念
死锁是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。
解决方案
解决死锁的一种方案是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务进行回滚,另一个继续进行。
这种超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其时根据FIFO的顺序选择回滚对象。当若超时的事务所占的权重较大,如果事务操作更新了很多行,占用了较多的undo log,这时FIFO的方式,就显得不合适了,因为回滚这个事务的时间相对于另一个事务所占用的时间可能会很多。
因此除了超时机制之外,当前数据库还普遍采用了等待图的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用这种方式。等待图要求数据库保存以下两种信息。
- 锁的信息链表
- 事务等待链表
通过上述信息可以够着出一张图,而在这个图种若存在回路,就代表存在死锁,因此资源间互相发生等待。
锁升级
锁升级时至当前锁粒度降低,举例来说,数据库可以把一个表的1000个行锁升级未页锁,或者间页锁升级未表锁。如果在数据库的设计中,认为锁是一种稀有资源,而且想要避免锁的开销,那数据库中会频繁出现锁升级现象。
InnoDB存储引擎不存在锁升级这个问题,因为其不是根据每个记录来产生行锁的,相反,其根据每个事务访问的每个页对锁进行管理的,采用的是位图的方式,因此不管一个事务锁住页中一个记录还是多个记录,其开销都是一致的。