粗略的cs231n学习笔记
1
1.1 概述
助教老师讲了讲课程的重要性和整体内容。
1.2 历史背景
1.2.1 history of cv
5.4亿年前化石表明动物已经具备眼睛,物种大爆炸。
现在的视觉称为了最重要的感知能力。大脑中50%的神经细胞在处理视觉信息。
16世纪,第一台针孔理论相机。目前相机是最受欢迎的传感器之一。
人类开始研究动物视觉:电生理学研究,猫实验,看看是啥能刺激视觉中枢。
1966,麻省理工学院,视觉论文《THE SUMMER VISION PROJECT》,视觉信息被简化成简单的形状。
70年代,David Marr的书《VISION》,原始草图重建。
70年代,出现了广义圆柱体和图形结构,将复杂的视觉信息简单化。
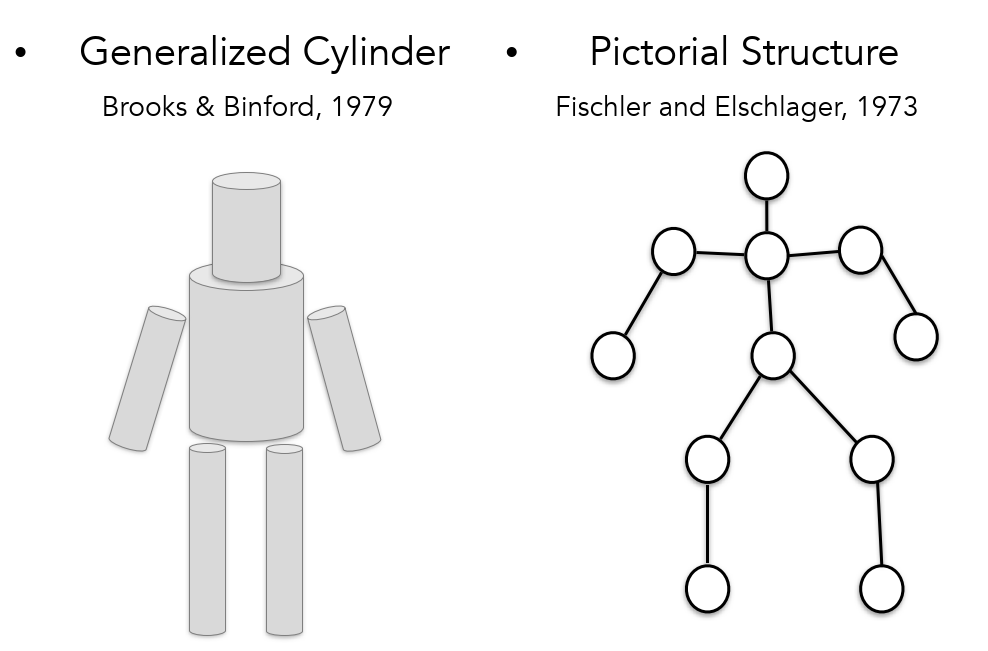
80年代,基于简单图形进行识别和重建任务。
直接识别任务太难,先做分割任务。
2006,富士相机实时面部检测。
新世纪初,SIFT被提出。

机器学习出现,暴露问题:过拟合、模型维度高,不好泛化。建立大型数据集ImageNet。2009开始ImageNet组织目标检测竞赛,统一量化基准。2012卷积神经网络出现,获得冠军。
1.3 课程介绍
聚焦于图像分类问题,基于ImageNet挑战赛。拓展到目标检测、图片摘要
卷积神经网络CNN已经成为大赛的主流。2012年AlexNet出现,是一个7层的网络。2014VGG、GoogleNet。实际上CNN的雏形1998年就已经出现,LeCun大佬。后来用的多了,取决于:
- 算力提升
- 数据多了
现在视觉任务貌似偏向了目标检测,这并不只是视觉的主要内容,实际上还有分割、分类、3D理解等。举例:
- feifei博士期间,实验:人看图半秒即可描述一段话;
- 人看到图像上的东西会有笑的反应。
实际上是借助了已有知识去理解了图像。说明到这种程度cv还有很长路要走。
老师说他相信:CV Can Better Our Lives.
本课的老师:feifei, Justin, Serena, &so on
2 图像分类
2.1 数据驱动方法
需要的知识:Python+NumPy, Google Cloud
问题与挑战
图像分类是cv的core task,计算机给图像分配一个标签。但是计算机只能看到一堆像素数值,面临的问题就是“语义鸿沟”。比如给目标换一个角度拍摄、换一个同类的目不同的背景信息……像素数值会发生巨大变化,人眼识别是鲁棒的,机器也要做到这样。
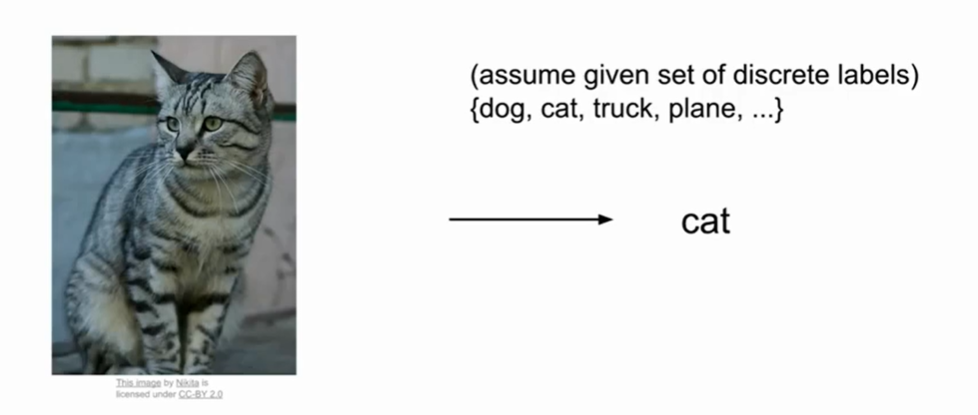
我们的任务
希望训练时间长,检测时间短
传统方法
比如边缘检测
数据驱动的方法
- 收集数据与标签
- 训练(机器学习的过程) train
- 在新的图上评估/预测 predict
数据集举例
CIFAR10
10类别,5w训练图像,1w测试图像。32x32 px图像
用于比较图像相似性的损失函数
L1:曼哈顿距离

L2:欧氏距离

最近邻的问题
不好处理数据中的噪音,所以出现了K近邻,使用多数投票,分类边界变得平滑
2.2 KNN
KNN原理:KNN算法(一) KNN算法原理
通过重构距离函数可以把KNN泛化到不同的数据类型上
L1依赖于坐标,向量的每个值有确定意义时,适合使用L1。否则可以两种都尝试一下,找到最好的。
超参设置
- idea1:所有数据选择同一个参数,K越小在训练集上性能越好,但是到测试集上需要调大K。这样就会出现过拟合,过分的贴合训练数据,降低了泛化能力。
- idea2:split data into train and test,选择不同参数,导致测试集很好,训练集不行了。
- idea3:split data into train, val and test,train用一个超参,val和test用一个超参,选择val上最好的参数用于test
- idea4:交叉验证,传统机器学习常见,DL不咋用
学生提问1:val和test区别?
答:val是有标签的,通过在val上测试,与标签比较,修正算法的正确率,而test是没有标签的,用于观察预测结果或者实际应用。
提问2:test不能代表现实中的样本,咋办?
答:数据集是独立同分布的,现实不是,所以创建数据集的时候应该考虑随机性。
所以,KNN在图像分类上很少使用,原因:
- test时间长
- 距离很难判断像素差异(不好找损失函数)
- 维度灾难,难度指数增长
提问:绿点和蓝点表示啥?
答:代表不同类数据。维度越高,需要越多的数据点来填满空间,所以是指数倍增长。
2.3 线性分类
比如:输入图像经过模块f,输出十个数中的一个,代表十个类别中的一个。
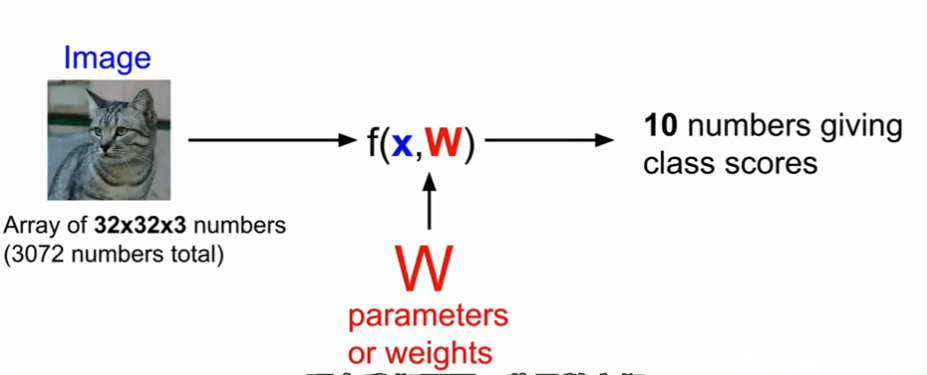
深度学习的主要工作就是构建高性能的f。
线性分类器:
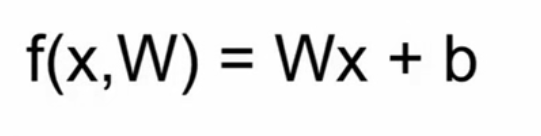
线性分类的模型简单,但是泛化能力差,只允许学习一个类型的一个模板。比如分类任务中,学习车的前脸,无法从车的侧面图判断是否是一辆车。
一个二维图像,经过特征提取后映射为高维空间中的一个点,只需在高维空间将点线性分类。而在低维空间中,两类是无法线性分开的。
3 损失函数和优化器
损失函数
来衡量我们对结果的不满意程度,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
我们对于预测训练集数据分类标签的情况总有一些不满意的,而损失函数就能将这些不满意的程度量化。
多类SVM
SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值Δ。

多类SVM“想要”正确类别的分类分数比其他不正确分类类别的分数要高,而且至少高出delta的边界值。如果其他分类分数进入了红色的区域,甚至更高,那么就开始计算损失。如果没有这些情况,损失值为0。我们的目标是找到一些权重,它们既能够让训练集中的数据样例满足这些限制,也能让总的损失值尽可能地低。
正则化
我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。这一点是能够实现的,方法是向损失函数增加一个正则化惩罚(regularization penalty)R(W)部分。
减轻模型复杂度,防止过拟合(over-fitting)。
Softmax
在Softmax分类器中,函数映射$f(x_i;W)=Wx_i$保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。公式如下:
$$
L_i=−f{y_i}+log(∑je^{f_j})
$$
SVM和Softmax的比较
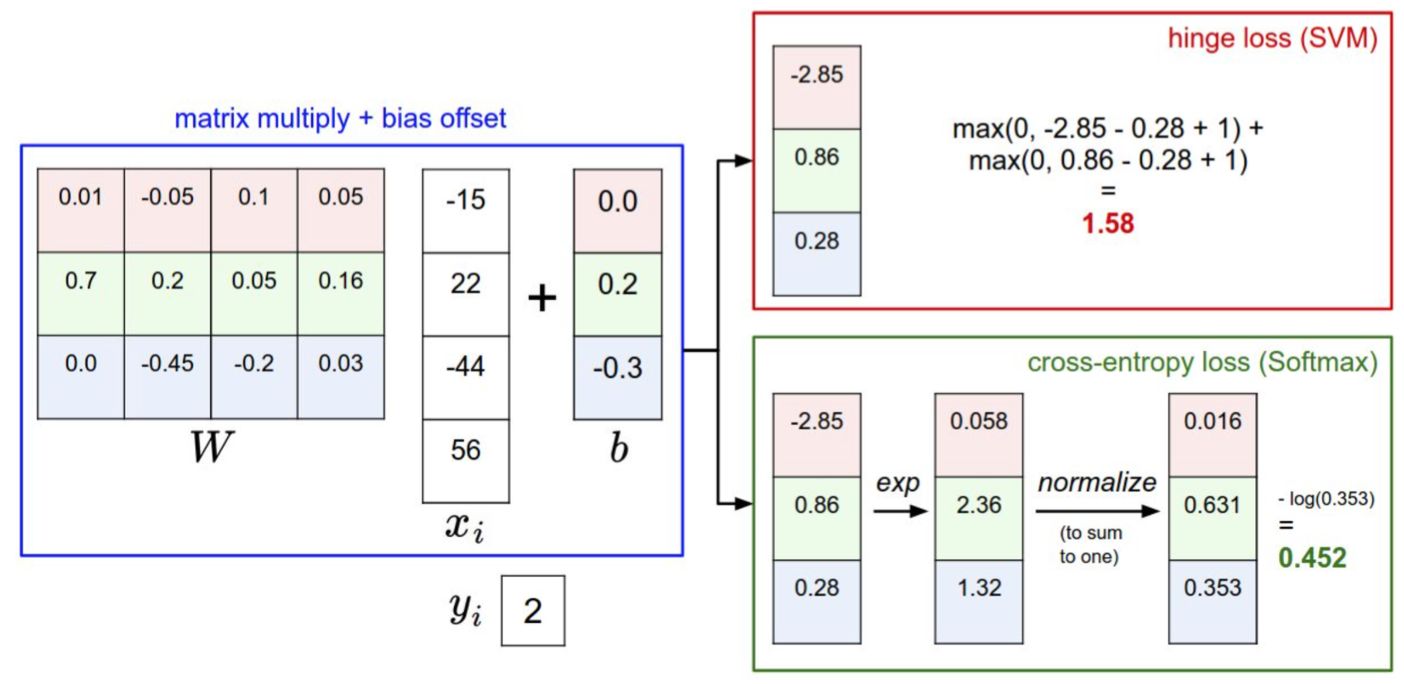
Softmax分类器为每个分类提供了“可能性”:SVM的计算是无标定的,而且难以针对所有分类的评分值给出直观解释。Softmax分类器则不同,它允许我们计算出对于所有分类标签的可能性。举个例子,针对给出的图像,SVM分类器可能给你的是一个[12.5, 0.6, -23.0]对应分类“猫”,“狗”,“船”。而softmax分类器可以计算出这三个标签的”可能性“是[0.9, 0.09, 0.01],这就让你能看出对于不同分类准确性的把握。
优化器
最优化
损失函数可以量化某个具体权重集W的质量。而最优化的目标就是找到能够最小化损失函数值的W的过程 。
参数更新需要有技巧地设置步长。也叫学习率。如果步长太小,进度稳定但是缓慢,如果步长太大,进度快但是可能有风险。
随机搜索:Acc=15.5%
随机尝试很多不同的权重,然后看其中哪个最好。每走一步都尝试几个随机方向,如果某个方向是向山下的,就向该方向走一步。
1
2
3
4
5
6
7
8
9
10
11
12# 假设X_train的每一列都是一个数据样本(比如3073 x 50000)
# 假设Y_train是数据样本的类别标签(比如一个长50000的一维数组)
# 假设函数L对损失函数进行评价
bestloss = float("inf") # Python assigns the highest possible float value...剩余内容已隐藏
查看完整文章以阅读更多粗略的cs231n学习笔记
2022年8月16日 19:581
1.1 概述
助教老师讲了讲课程的重要性和整体内容。
1.2 历史背景
1.2.1 history of cv
5.4亿年前化石表明动物已经具备眼睛,物种大爆炸。
现在的视觉称为了最重要的感知能力。大脑中50%的神经细胞在处理视觉信息。
16世纪,第一台针孔理论相机。目前相机是最受欢迎的传感器之一。
人类开始研究动物视觉:电生理学研究,猫实验,看看是啥能刺激视觉中枢。
1966,麻省理工学院,视觉论文《THE SUMMER VISION PROJECT》,视觉信息被简化成简单的形状。
70年代,David Marr的书《VISION》,原始草图重建。
70年代,出现了广义圆柱体和图形结构,将复杂的视觉信息简单化。
80年代,基于简单图形进行识别和重建任务。
直接识别任务太难,先做分割任务。
2006,富士相机实时面部检测。
新世纪初,SIFT被提出。
机器学习出现,暴露问题:过拟合、模型维度高,不好泛化。建立大型数据集ImageNet。2009开始ImageNet组织目标检测竞赛,统一量化基准。2012卷积神经网络出现,获得冠军。
1.3 课程介绍
聚焦于图像分类问题,基于ImageNet挑战赛。拓展到目标检测、图片摘要
卷积神经网络CNN已经成为大赛的主流。2012年AlexNet出现,是一个7层的网络。2014VGG、GoogleNet。实际上CNN的雏形1998年就已经出现,LeCun大佬。后来用的多了,取决于:
- 算力提升
- 数据多了
现在视觉任务貌似偏向了目标检测,这并不只是视觉的主要内容,实际上还有分割、分类、3D理解等。举例:
- feifei博士期间,实验:人看图半秒即可描述一段话;
- 人看到图像上的东西会有笑的反应。
实际上是借助了已有知识去理解了图像。说明到这种程度cv还有很长路要走。
老师说他相信:CV Can Better Our Lives.
本课的老师:feifei, Justin, Serena, &so on
2 图像分类
2.1 数据驱动方法
需要的知识:Python+NumPy, Google Cloud
问题与挑战
图像分类是cv的core task,计算机给图像分配一个标签。但是计算机只能看到一堆像素数值,面临的问题就是“语义鸿沟”。比如给目标换一个角度拍摄、换一个同类的目不同的背景信息……像素数值会发生巨大变化,人眼识别是鲁棒的,机器也要做到这样。
我们的任务
希望训练时间长,检测时间短
传统方法
比如边缘检测
数据驱动的方法
- 收集数据与标签
- 训练(机器学习的过程) train
- 在新的图上评估/预测 predict
数据集举例
CIFAR10
10类别,5w训练图像,1w测试图像。32x32 px图像
用于比较图像相似性的损失函数
L1:曼哈顿距离
L2:欧氏距离
最近邻的问题
不好处理数据中的噪音,所以出现了K近邻,使用多数投票,分类边界变得平滑
2.2 KNN
KNN原理:KNN算法(一) KNN算法原理
通过重构距离函数可以把KNN泛化到不同的数据类型上
L1依赖于坐标,向量的每个值有确定意义时,适合使用L1。否则可以两种都尝试一下,找到最好的。
超参设置
- idea1:所有数据选择同一个参数,K越小在训练集上性能越好,但是到测试集上需要调大K。这样就会出现过拟合,过分的贴合训练数据,降低了泛化能力。
- idea2:split data into train and test,选择不同参数,导致测试集很好,训练集不行了。
- idea3:split data into train, val and test,train用一个超参,val和test用一个超参,选择val上最好的参数用于test
- idea4:交叉验证,传统机器学习常见,DL不咋用
学生提问1:val和test区别?
答:val是有标签的,通过在val上测试,与标签比较,修正算法的正确率,而test是没有标签的,用于观察预测结果或者实际应用。
提问2:test不能代表现实中的样本,咋办?
答:数据集是独立同分布的,现实不是,所以创建数据集的时候应该考虑随机性。
所以,KNN在图像分类上很少使用,原因:
- test时间长
- 距离很难判断像素差异(不好找损失函数)
- 维度灾难,难度指数增长
提问:绿点和蓝点表示啥?

答:代表不同类数据。维度越高,需要越多的数据点来填满空间,所以是指数倍增长。
2.3 线性分类
比如:输入图像经过模块f,输出十个数中的一个,代表十个类别中的一个。
深度学习的主要工作就是构建高性能的f。
线性分类器:
线性分类的模型简单,但是泛化能力差,只允许学习一个类型的一个模板。比如分类任务中,学习车的前脸,无法从车的侧面图判断是否是一辆车。
一个二维图像,经过特征提取后映射为高维空间中的一个点,只需在高维空间将点线性分类。而在低维空间中,两类是无法线性分开的。
3 损失函数和优化器
损失函数
来衡量我们对结果的不满意程度,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
我们对于预测训练集数据分类标签的情况总有一些不满意的,而损失函数就能将这些不满意的程度量化。
多类SVM
SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值Δ。
多类SVM“想要”正确类别的分类分数比其他不正确分类类别的分数要高,而且至少高出delta的边界值。如果其他分类分数进入了红色的区域,甚至更高,那么就开始计算损失。如果没有这些情况,损失值为0。我们的目标是找到一些权重,它们既能够让训练集中的数据样例满足这些限制,也能让总的损失值尽可能地低。
正则化
我们希望能向某些特定的权重W添加一些偏好,对其他权重则不添加,以此来消除模糊性。这一点是能够实现的,方法是向损失函数增加一个正则化惩罚(regularization penalty)R(W)部分。
减轻模型复杂度,防止过拟合(over-fitting)。
Softmax
在Softmax分类器中,函数映射$f(x_i;W)=Wx_i$保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。公式如下:
$$
L_i=−f{y_i}+log(∑je^{f_j})
$$SVM和Softmax的比较
Softmax分类器为每个分类提供了“可能性”:SVM的计算是无标定的,而且难以针对所有分类的评分值给出直观解释。Softmax分类器则不同,它允许我们计算出对于所有分类标签的可能性。举个例子,针对给出的图像,SVM分类器可能给你的是一个[12.5, 0.6, -23.0]对应分类“猫”,“狗”,“船”。而softmax分类器可以计算出这三个标签的”可能性“是[0.9, 0.09, 0.01],这就让你能看出对于不同分类准确性的把握。
优化器
最优化
损失函数可以量化某个具体权重集W的质量。而最优化的目标就是找到能够最小化损失函数值的W的过程 。
参数更新需要有技巧地设置步长。也叫学习率。如果步长太小,进度稳定但是缓慢,如果步长太大,进度快但是可能有风险。
随机搜索:Acc=15.5%
随机尝试很多不同的权重,然后看其中哪个最好。每走一步都尝试几个随机方向,如果某个方向是向山下的,就向该方向走一步。
1
2
3
4
5
6
7
8
9
10
11
12# 假设X_train的每一列都是一个数据样本(比如3073 x 50000)
# 假设Y_train是数据样本的类别标签(比如一个长50000的一维数组)
# 假设函数L对损失函数进行评价
bestloss = float("inf") # Python assigns the highest possible float value...剩余内容已隐藏
查看完整文章以阅读更多