一日一技:如何使用大模型提取结构化数据
经常有同学在微信群里面咨询,如何使用大模型从非结构化的信息里面提取出结构化的内容。最常见的就是从网页源代码或者长报告中提取各种字段和数据。
最直接,最常规的方法,肯定就是直接写Prompt,然后把非结构化的长文本放到Prompt里面,类似于下面这段代码:
1 | from zhipuai import ZhipuAI |
如果你每次只需要提取一两个数据,用这种方式确实没什么问题。不过正如我之前一篇文章《一日一技:超简单方法显著提高大模型答案质量》中所说,返回的JSON不一定是标准格式,你需要通过多种方式来强迫大模型以标准JSON返回。并且要使用一些Prompt技巧,来让大模型返回你需要的字段,不要随意乱编字段名。
当你需要提取的数据非常多时,使用上面这种方法就非常麻烦了。例如我们打开某个二手房网站,它上面某个楼盘的信息如下图所示:
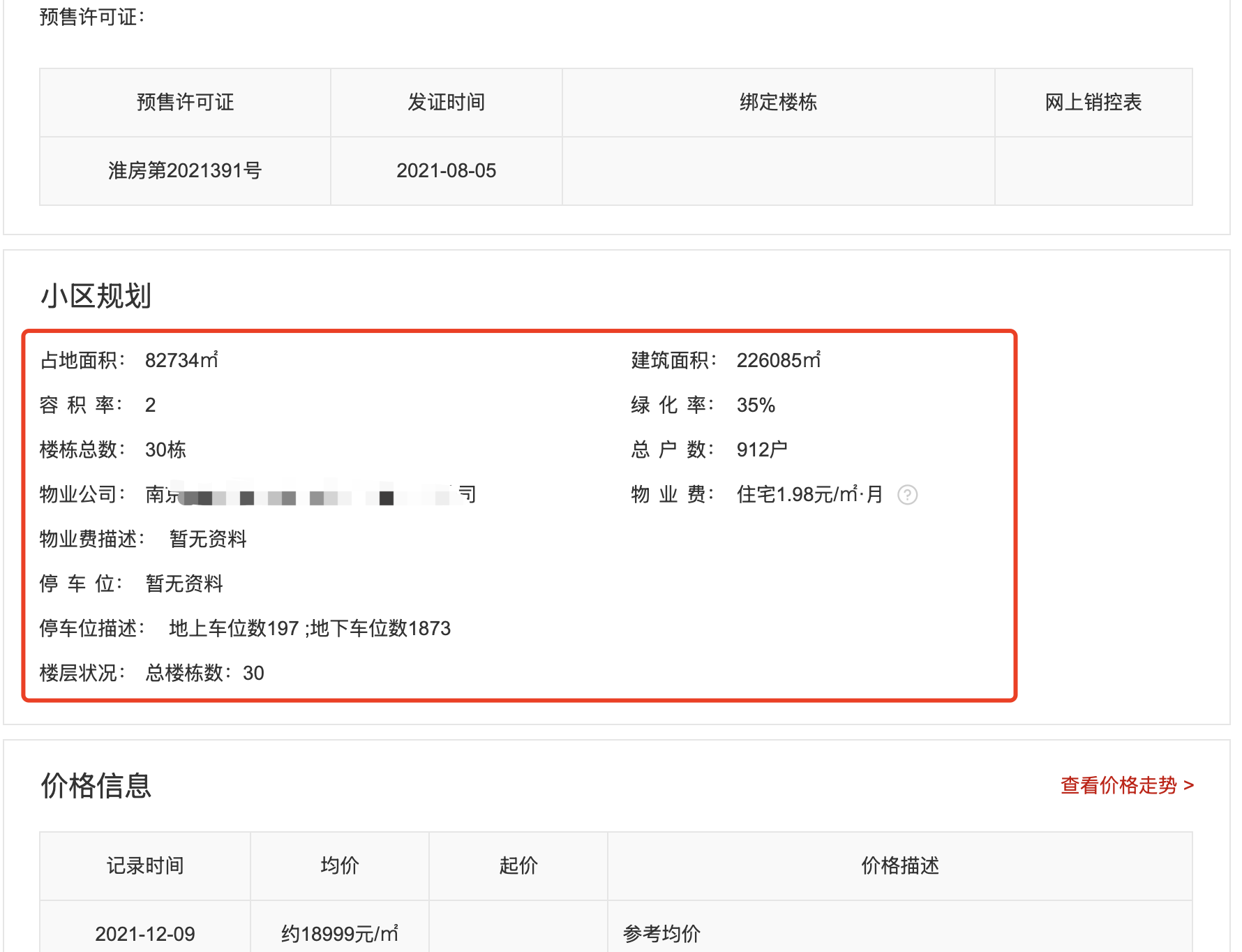
一方面是因为字段比较多,你使用纯文本的Prompt并不好描述字段。另一方面是HTML原文很长,这种情况基于纯Prompt的提取,字段名会不稳定,例如占地面积,有时候它给你返回floor_area有时候返回floorArea有时候又是其他词。但如果你直接在Prompt给出一个字段示例,例如:
1 | ……上面是一大堆描述…… |
有时候你会发现,对于多个不同的楼盘,大模型返回给里的floor_area的值都是100,因为它直接把你的例子中的示例数据给返回了。
如果你只是写个Demo,你可能会觉得大模型真是天然适合做结构化数据的提取,又方便又准确。但当你真的尝试过几百次,几千次不同文本中的结构化数据提取后,你会发现里面太多的坑。
好在,Python有一个专门的第三方库,用来从非结构化的数据中提取结构化的信息,并且已经经过了深度的优化,大量常见的坑都已经被解决掉了。配合Python专门的结构化数据校验模块Pydantic,能够让提取出来的数据直接以类的形式储存,方便后续的使用。
这个模块叫做Instructor。使用这个模块,我们只需要先在Pydantic中定义好结果的数据结构,就能从长文本中提取数据。并且代码非常简单:
1 | import instructor |