ipfans's Blog
Recent content on ipfans's Blog
马上订阅 ipfans's Blog RSS 更新: https://www.4async.com/atom.xml
从零学习 Hypothetical Document Embeddings (HyDE) - 1
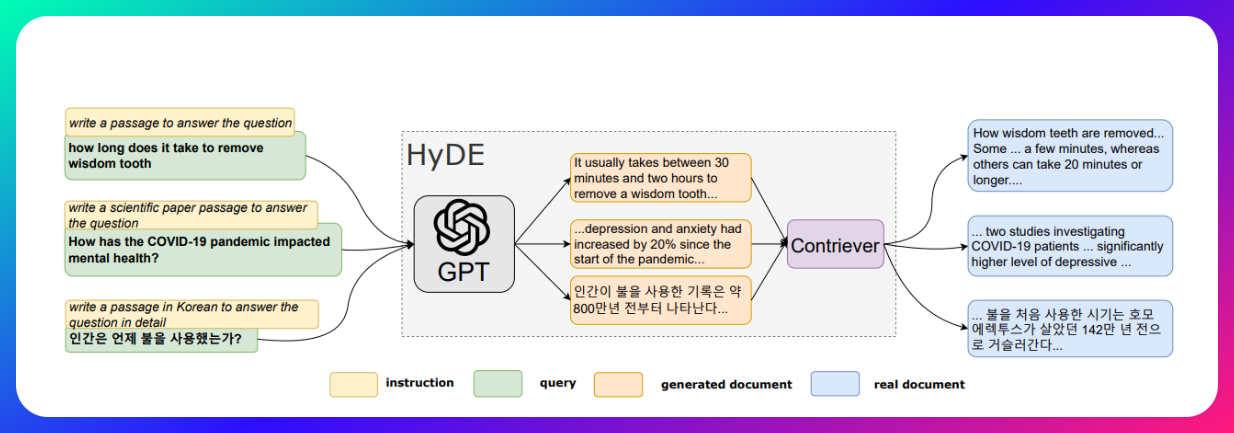
最近看到了一篇新的论文,关于评估 RAG 中的各种技术的评估。这篇《ARAGOG: Advanced RAG Output Grading》提供了一个对比多种 RAG 技术的评估。其中提到 HyDE 和 LLM re-rank 能够很好的提高检索精度。不过似乎 HyDE 其实讨论并不是很多,那么咱就对这块内容添砖加瓦一下,让我们从零开始进行一段 HyDE 的冒险。
什么是 RAG?
大语言模型(LLM)虽然在过去的一段时间中成为大家眼中的香馍馍,但它们也存在一些关键的局限性:
- 知识局限性: LLM 的知识范围主要局限于其训练数据,难以涵盖所有知识领域,在一些专业或冷门话题上表现不佳。尤其是现在 AI 应用场景需要使用来自于企业内部知识库或者外部知识库中的相关信息,而这些内部知识库往往是不在外部公开的。
- 可靠性问题: LLM 依赖于概率模型生成文本,结果难免存在事实性错误或缺乏可靠性,在某些关键应用中存在风险。比如之前的加拿大航空赔偿事件,尤其是对敏感的需要正确信息的场景,一旦出现错误的信息往往意味着潜在的损失。
要解决这些问题,那么就需要是用 RAG 来帮助解决。那么,什么是 RAG 呢?
Retrieval-Augmented Generation (RAG) 是一种基于检索的生成式模型,它结合了检索式和生成式的优点,可以在生成式模型(Generative Model)中引入外部知识。RAG 模型由两部分组成:一个是检索器,另一个是生成器。检索器负责从知识库中检索相关信息,生成器则负责生成答案。与传统的大语言模型(LLM)仅依靠自身有限的知识进行文本生成不同,RAG 模型能够动态地从海量的外部知识库中检索相关信息,并将这些信息融入到生成过程中,产生更加准确、连贯的输出内容。
换句话说,当用户提出一个查询或者需要生成某种类型的文本时,RAG 模型首先会利用一个信息检索子模块,从知识库中检索出与查询相关的信息。然后,RAG 的生成子模块会结合这些检索到的相关信息,生成最终的输出文本。这种结合检索和生成的方式,使 RAG 模型能够弥补传统 LLM 的局限性,提高生成内容的准确性和可靠性。
简单点来说,RAG 的基本流程如下:

什么是 HyDE?
但是在是用 RAG 的时候,你往往也会遇到一些问题。
让我们设想一个场景:我们有一个知识库,里面存储了大量的文档,我们希望使用 RAG 模型来回答用户的问题。但是,原始的 RAG 只能处理知识库中包含的数据,但是对于知识库中不存在的数据,RAG 无法处理。比较常见的场景包含用户的问答系统,帮助中心,对话系统等。用户通常对你的系统或者专有名词并不了解,他们通常会提出一些根据自己理解或者自己熟悉概念中的名词问题,这些表达方式可能并不在你的知识库中。这时候 RAG 就无法从知识库中检索到相关信息。