Random Thoughts
Recent content on Random Thoughts
马上订阅 Random Thoughts RSS 更新: https://blog.joway.io/index.xml
分布式文件系统的演化
2020年6月14日 08:00
文件系统是操作系统 IO 栈里非常重要的一个中间层,其存在的意义是为了让上层应用程序有一层更加符合人类直觉的抽象来进行文档的读写,而无需考虑底层存储上的细节。
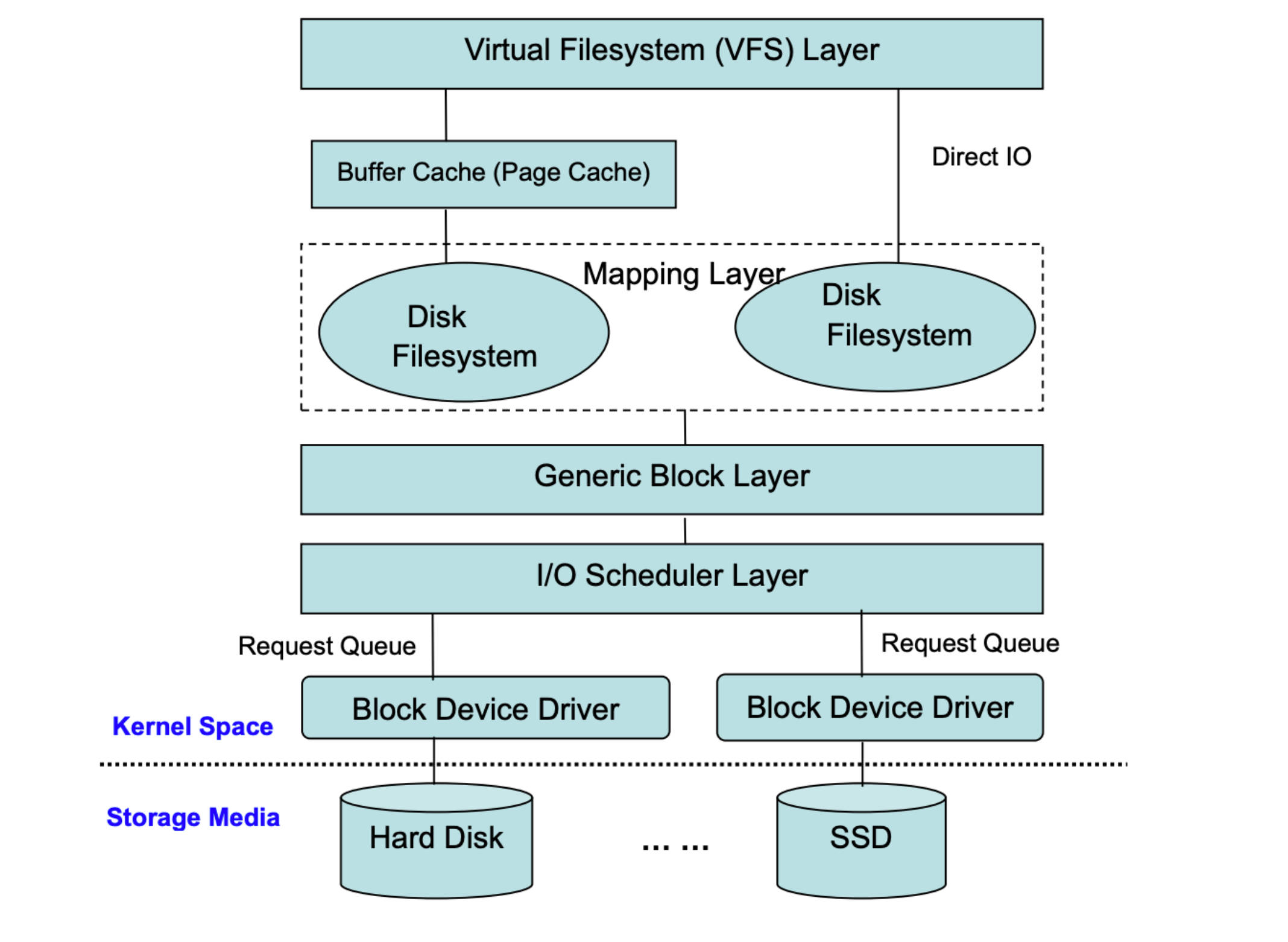
本地文件系统
在讨论分布式文件系统前,我们先来回顾下本地文件系统的组成。
存储结构
在前面一张图里,我们能够看到文件系统直接和通用块层进行交互,无论底层存储介质是磁盘还是 SSD,都被该层抽象为 Block 的概念。文件系统在初始化时,会先在挂载的块存储上的第一个位置创建一个 Super Block:
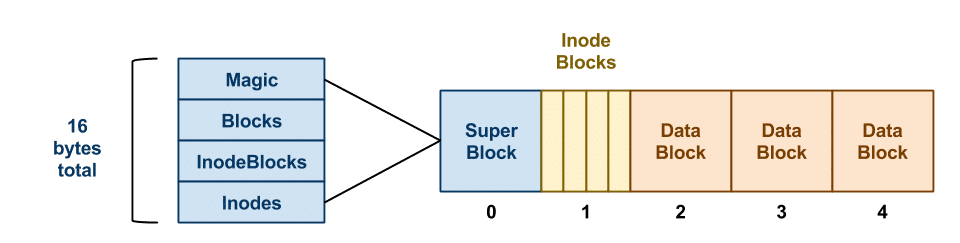
上图右边部分就是一块完整的存储,可以将其想象成一个数组。
Super Block 中存储了该文件系统的信息,其组成部分如下:
- Magic:
MAGIC_NUMBERor0xf0f03410,用来告诉操作系统该磁盘是否已经拥有了一个有效的文件系统。 - Blocks: blocks 总数
- InodeBlocks: 其中属于 inode 的 block 数
- Inodes: 在 InodeBlocks 中存在多少个 inodes
由于这里的 Blocks 总数、InodeBlocks 总数、每个 Block 的大小在文件系统创建时就已经固定,所以一般来说一个文件系统能够创建的文件数量在一开始就已经固定了。
Linux 中每个文件都拥有一个唯一的 Inode,其结构如下:
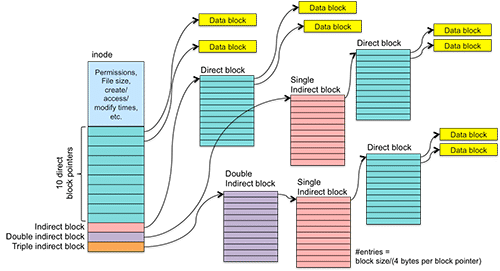
inode 上半部分的 meta data 很容易理解,下半部分的 block 指针的含义分别为:
- direct block pointer: 直接指向 data block 的地址
- indirect block: 指向 direct block
- double indirect block: 指向 indirect block
- triple indirect block: 指向 double indirect block
由于一个 inode 大小固定,所以这里的 block pointers 数量也是固定的,进而单个文件能够占用的 data block 大小也是固定的,所以一般文件系统都会存在最大支持的文件大小。