实现一个类型安全的 (f1, f2) -> f2(f1()) 函数
def compose(first, second):
return lambda: second(first())有了这个函数,当你需要 串联 两个函数的时候,就可以很方便了,下面我举例一个使用场景
例子:序列化并用 bzip2 压缩
大家都知道 python 对象的序列化用pickle.dumps,压缩用***.compress(***替换成各种库,比如标准库的 gzip,bz2,lzma 都是这样)
前者是(Any)->bytes,后者是bytes->bytes,如果你要封装一个“序列化并压缩”的函数,你得这么写:
def dumps(object: Any):
serialized = pickle.dumps(object)
compressed = bz2.compress(serialized)
return compressed当然这种一次性的代码一般会缩写成一行:
def dumps(object: Any):
return bz2.compress(pickle.dumps(object))再加上反序列化的代码:
def loads(data: bytes):
return pickle.loads(bz2.decompress(data))这样,再加上空行,相当于你代码加了8行。不能忍吧
用我们刚刚的compose函数,只要这样就行了:
dumps = compose(pickle.dumps, bz2.compress)
loads = compose(bz2.decompress, pickle.loads)只要两行,而且清清楚楚。
但是类型呢?
我们刚刚的compress函数,没有类型注解,你可能觉得这很简单,这样就行了:
def compose(first: Callable, second: Callable):
return lambda: second(first())
这样只能确保输入compose的两个参数都是可调用对象,但是并没有保证:
- 第二个函数可以接受第一个函数的返回值为参数
compose后的函数的返回值与second的返回值相同

我们希望h()的类型推断是Literal[42]或者int对吧
泛型
Python 有勉强够用的泛型支持,而且早在 Python 3.12 就开始支持 typescript 式的更方便的声明泛型的方式:
PEP 695: Type Parameter Syntax —— What's New In Python 3.12
这么写就可以了:
def compose[T1, T2](first: Callable[[], T1], second: Callable[[T1], T2]):
return lambda: second(first())你看我甚至返回值都不用标,pyright能推算出来返回的是Callable[[], T2]
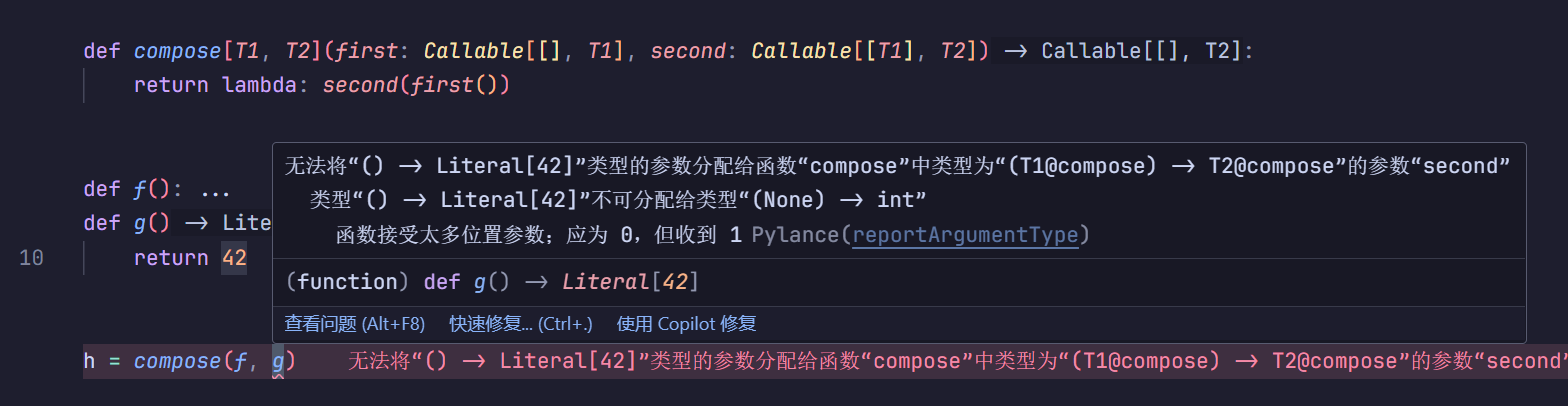
你看,这样错误就能检查出来啦☀️
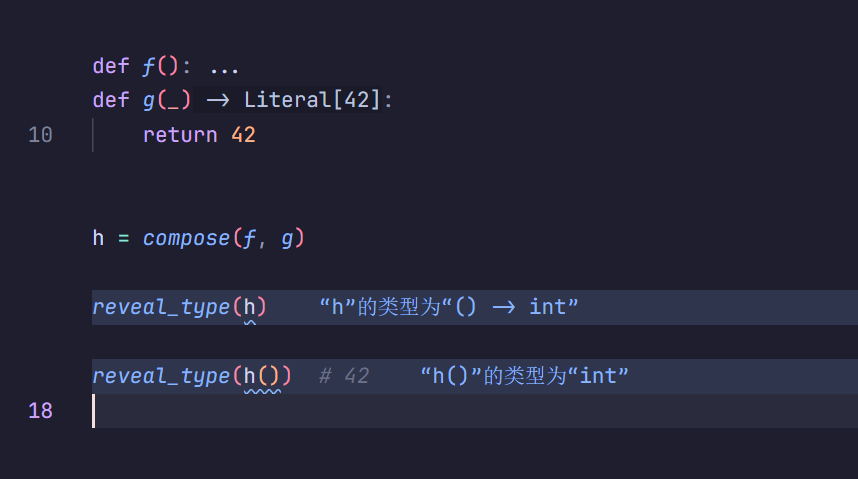
修复了g之后,类型也正确推断啦:
如果 first()有参数呢
上面的这个例子用途不够广泛,因为它用于无参调用。而有时候我很需要这个 compose 出来的函数,仍然有着原来的 first 函数的参数定义
其实我们需要的就是一个“输入 first 的参数,返回 second 的返回值”这么一个函数对吧,那就简单了:
def compose[T1, T2, **P](first: Callable[P, T1], second: Callable[[T1], T2]) -> Callable[P, T2]:
return lambda *args, **kwargs: second(first(*args, **kwargs))我只是把Callable[[], T1]改成了Callable[P, T1],加上明确最后返回Callable[P, T2]就完事儿啦。
当然,如果你不喜欢 lambda,你可以这样写一个函数,这样甚至能少写-> Callable[P, T2]这个返回值声明
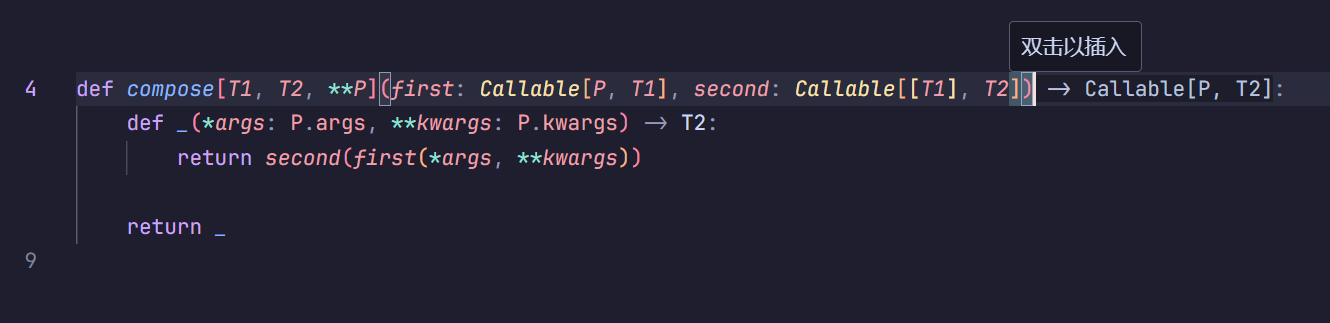
右边的返回值声明是它自己生成的,这个显示是 IDE 的 inlay hint,不是我打上去的
这样你就可以让这个 compose 出的函数具有和first一样的入参签名啦:
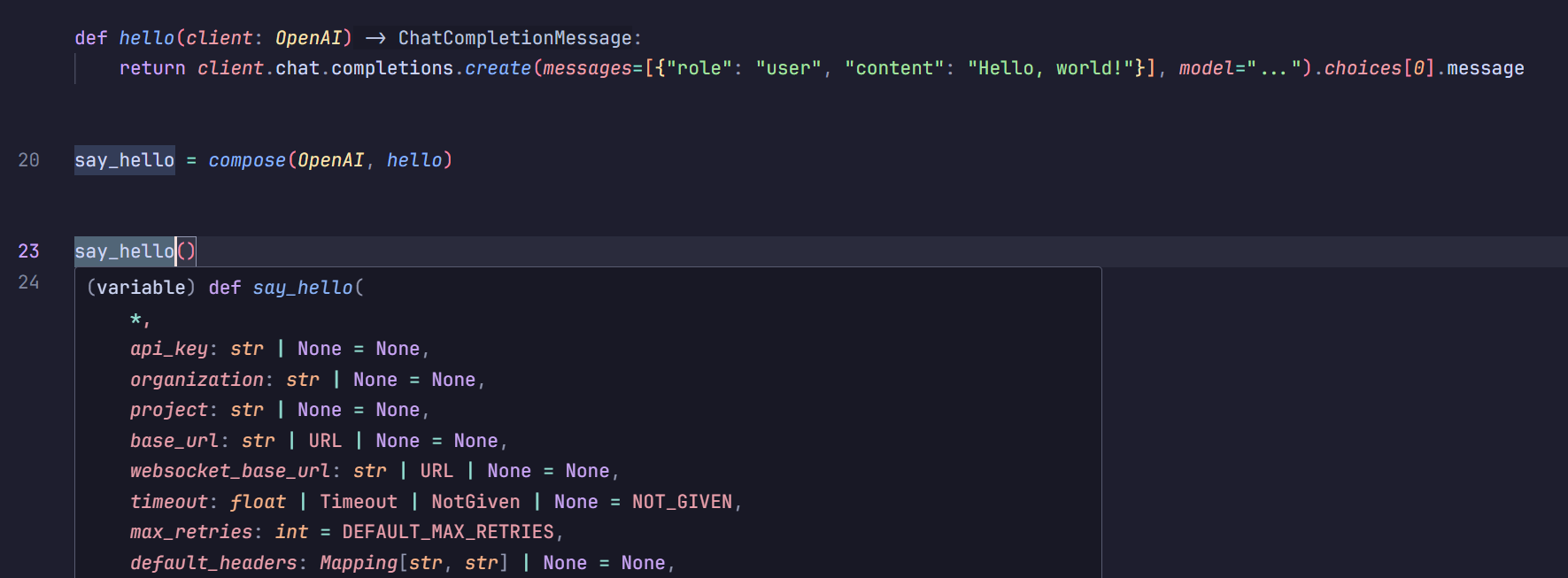
这个例子其实挺没用的,但是我一时间想不到好例子。总之使用场景就是,可能前面那个函数有很多参数,而且你是会用到这些参数的。
后话:为什么做这个
因为我想要一个类型安全的json.dumps和json.loads...
剩余内容已隐藏
实现一个类型安全的 (f1, f2) -> f2(f1()) 函数
def compose(first, second):
return lambda: second(first())有了这个函数,当你需要 串联 两个函数的时候,就可以很方便了,下面我举例一个使用场景
例子:序列化并用 bzip2 压缩
大家都知道 python 对象的序列化用pickle.dumps,压缩用***.compress(***替换成各种库,比如标准库的 gzip,bz2,lzma 都是这样)
前者是(Any)->bytes,后者是bytes->bytes,如果你要封装一个“序列化并压缩”的函数,你得这么写:
def dumps(object: Any):
serialized = pickle.dumps(object)
compressed = bz2.compress(serialized)
return compressed当然这种一次性的代码一般会缩写成一行:
def dumps(object: Any):
return bz2.compress(pickle.dumps(object))再加上反序列化的代码:
def loads(data: bytes):
return pickle.loads(bz2.decompress(data))这样,再加上空行,相当于你代码加了8行。不能忍吧
用我们刚刚的compose函数,只要这样就行了:
dumps = compose(pickle.dumps, bz2.compress)
loads = compose(bz2.decompress, pickle.loads)只要两行,而且清清楚楚。
但是类型呢?
我们刚刚的compress函数,没有类型注解,你可能觉得这很简单,这样就行了:
def compose(first: Callable, second: Callable):
return lambda: second(first())
这样只能确保输入compose的两个参数都是可调用对象,但是并没有保证:
- 第二个函数可以接受第一个函数的返回值为参数
compose后的函数的返回值与second的返回值相同
我们希望h()的类型推断是Literal[42]或者int对吧
泛型
Python 有勉强够用的泛型支持,而且早在 Python 3.12 就开始支持 typescript 式的更方便的声明泛型的方式:
PEP 695: Type Parameter Syntax —— What's New In Python 3.12
这么写就可以了:
def compose[T1, T2](first: Callable[[], T1], second: Callable[[T1], T2]):
return lambda: second(first())你看我甚至返回值都不用标,pyright能推算出来返回的是Callable[[], T2]
你看,这样错误就能检查出来啦☀️
修复了g之后,类型也正确推断啦:
如果 first()有参数呢
上面的这个例子用途不够广泛,因为它用于无参调用。而有时候我很需要这个 compose 出来的函数,仍然有着原来的 first 函数的参数定义
其实我们需要的就是一个“输入 first 的参数,返回 second 的返回值”这么一个函数对吧,那就简单了:
def compose[T1, T2, **P](first: Callable[P, T1], second: Callable[[T1], T2]) -> Callable[P, T2]:
return lambda *args, **kwargs: second(first(*args, **kwargs))我只是把Callable[[], T1]改成了Callable[P, T1],加上明确最后返回Callable[P, T2]就完事儿啦。
当然,如果你不喜欢 lambda,你可以这样写一个函数,这样甚至能少写-> Callable[P, T2]这个返回值声明
右边的返回值声明是它自己生成的,这个显示是 IDE 的 inlay hint,不是我打上去的
这样你就可以让这个 compose 出的函数具有和first一样的入参签名啦:
这个例子其实挺没用的,但是我一时间想不到好例子。总之使用场景就是,可能前面那个函数有很多参数,而且你是会用到这些参数的。
后话:为什么做这个
因为我想要一个类型安全的json.dumps和json.loads...
剩余内容已隐藏