博客的发展一:RSS,国内托管……
前言
不知不觉,Gatsby博客已经上线了一年多。在这一年中,虽然从表面看起来博客变化不大,但是我一直在对博客做一些更新工作。特别是最近一个月,我对博客一些耽搁已久的问题进行了解决,使整个博客更加的完善了。这篇简单的文章就简地列举一下最近博客一些特别值得提到的更新,目前存在的问题,以及对博客的未来发展做一些展望和规划。
更新
RSS恢复支持
博客的RSS源地址是:https://ddadaal.me/rss.xml。欢迎订阅!
其实博客从很早开始(具体来说,从去年10月的e2e469开始)就已经加入了RSS支持,但是那时候的代码就是随便从网上抄了一段,没有对博客比较特殊的地方(例如说多语言的支持,存在不能显示在列表中的文章等)进行定制,后面对博客一些更新的时候也都直接放弃了RSS。这几天,我针对博客的RSS的功能进行了一些修复,包括:修复文章中不合法的日期串、RSS项中的原文链接变成绝对地址而不是相对地址,重新修改序列化方法等,使得博客的RSS功能基本上可以正常使用了。博客的RSS源地址也在W3C的Feed Validation Service中成功认证,对于大多数RSS阅读器来说已经可以正常使用了。
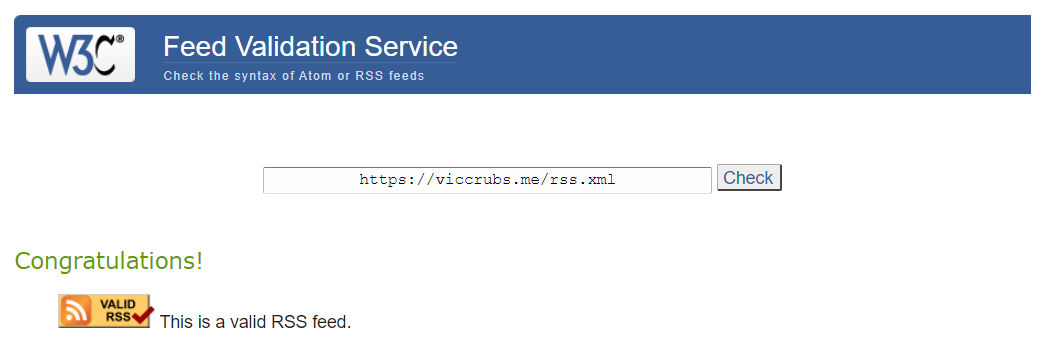
当然,根据认证服务的结果可以发现,博客的RSS还有一些问题,其中比较严重是文章内容的图片地址是相对地址,而不是绝对地址,这造成了包括Read(一个Android RSS应用,Google Play)等一些工具不能正确显示图片。但是这些问题可能在短时间内无法被解决,因为我目前暂时没有找到有效的、可扩展的方法hook进入Gatsby构建时markdown的渲染流程,并根据我的需求进行修改。
详细地说,目前,将MD编译成HTML是由remark,以及很多周边插件(例如Gatsby-transformer-remark)共同完成的。这些插件都有一些默认行为(例如图片地址是相对地址)等。
这些默认行为在大多数情况下都是合理的,让开发者能够开箱即用。但是,约定大于配置的反面就是配置常常不够完善,在遇到少见的需求的时候让开发者感到束手束脚。
之前,为了一些特殊需求(例如在markdown里插入React组件(我使用过MDX个人不太好用),给code元素加入一些特殊元素(例如显示语言、行号、复制按钮等)),我多次尝试过hook进remark的编译过程,在remark进行渲染的时候修改AST,使得进入Gatsby数据源中的htmlAst和html就是经过定制的,但是一直没能找到合适的方法。
后来,这些功能都实现了,但是不够优雅:在代码中,从Gatsby数据源中获取remark渲染后的AST,修改AST后再重新使用rehype-react渲染(对这里感兴趣的同学可以查看代码的ArticleContentDisplay组件)。
这样做虽然能够实现需求,但由于在Gatsby的数据源中,其htmlAst和html并没有经过定制(定制是在页面渲染的时候执行的),这也造成目前各个方法获得的HTML并不统一。
没有一个可靠的hook渲染过程的方法,也造成了我没有办法修改remark的默认行为,其中就包含图片地址为相对地址而不是绝对地址这个问题。
我正在努力想办法解决这个问题,但是看情况短时间内解决希望不大。
使用国内托管(腾讯云的CODING个人版)
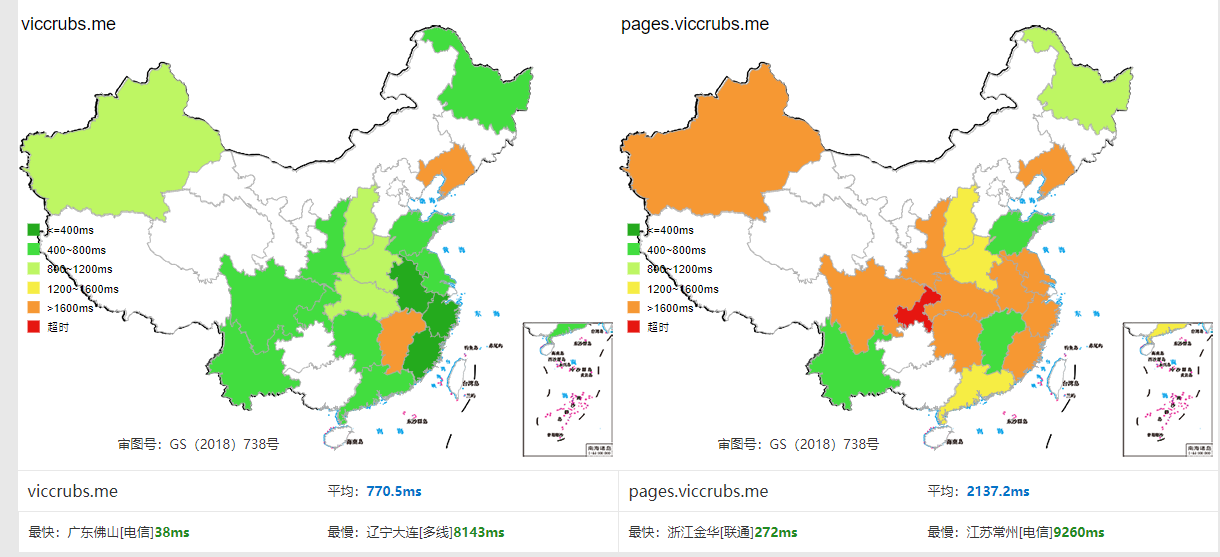
博客一直是托管在GitHub Pages上的。GitHub Pages很方便,零开销,在国外用的很广,网络上的教程也到处都是。但是它的问题是在国内速度非常慢,且非常不稳定。即使我的博客的相关文件已经比较小了,但是GitHub Pages在国内的速度也极大地影响了网站的用户体验。要是当某篇文章有图片,那体验就更糟了。
多亏了我的博客是静态博客,解决这个问题,本质上只需要把文件托管到某个国内访问速度快的类Pages服务上即可解决问题(点关于博客查看博客工作原理介绍)。我把目标投向了17年参加南京四校Hack.Christmas时赞助商提供的CODING.NET一年免费VIP账号。虽然那时候VIP基本已经过期,但是当时体验还行,并且也发现了它也提供类似GitHub Pages的功能(也叫Pages服务)。于是,我进行了以下操作:
- 在CODING.NET上开启一个repo,存放博客的文件
- 给这个repo开启Pages服务
- 修改CI脚本,构建后向GitHub和CODING.NET的repo都推送一次
经过测试,CODING.NET的体验还是非常良好的,在国内的速度也非常不错,于是:
- 修改DNS,将根记录(ddadaal.me)指向了CODING.NET,二级域名(pages.ddadaal.me)指向原有GitHub Pages repo
- 在GitHub和CODING.NET平台上修改域名设置
这样,我的根域名就被解析到CODING.NET提供的Pages服务上。经过测试,网站的速度提高了非常多,国内用户的体验得到了很大的提高。
多语言环境下文章地址改进
之前,为了支持多语言,本网站的所有文章的地址末尾都增加了语言(cn/en)为了表示这个文章的语言是什么,例如关于我就有两个版本,/about/me/cn(中文)和/about/me/en(英文),另外对/about/me这种根路径增加了客户端的跳转(即在浏览器执行了JS进行跳转,而不是通过服务器发送301(Moved Permanently)的响应。对于静态博客,服务器发送301是不可能的,因为服务器端不能执行这么“复杂”的逻辑)到本文章的所有版本的第一种语言版本(知道你对第一种语言版本感到疑惑,继续往下看)。
这样做有2个问题:
- 对于所有文章,包括占大多数的只有一种语言版本的文章,其地址栏最后都有语言字符串,造成路径不必要的太长;
- 这个“第一种语言版本”的结果每次执行可能是不相同的,有可能造成根路径在每次更新后都出现变化(没有验证过,只是存在这种可能)。
我在最近也重新设计了路径的计算方法,较好的解决了这个问题。以id为an-article的、有两种语言版本(cn和en)文章来举例子:
- 首先,对一篇文章的所有语言版本,根据lang的字典序进行排序,使得每次所有版本的顺序都是相同的,解决了第二个问题
- 例子中,顺序为
[cn, en];
- 例子中,顺序为
- 选取中文版本(
cn)的文章,或者如果中文版本不存在的话,选择第一个版本(由于所有版本的顺序是相同的,第一个版本也总是相同的),生成根路径/articles/${articleId}的页面- 例子中,选择了中文(
cn)版本生成/article/an-article的页面;
- 例子中,选择了中文(
- 生成
/articles/${articleId}/${上一步生成的版本的语言}到/articles/${articleId}的客户端跳转- 例子中,生成了
/articles/an-article/cn到/articles/an-article的跳转
- 例子中,生成了
- 对其他所有语言,生成
/articles/${articleId}/${语言}的页面。
通过这样,可以保证博客中大多数单语言的文章都生成在根路径,不再有碍眼的多余的语言字符串,同时也保证了多语言功能和向前兼容性。
举几个例子:
| 文章 | 语言 | 之前的路径 | 现在的路径 |
|---|---|---|---|
| 关于我 | cn | /about/me/cn | /about/me |
| 关于我 | en | /about/me/en | /about/me/en |
| 2018年总结 | cn | /articles/summary-for-2018/cn | /articles/summary-for-2018 |
| Simstate and Why | en | /articles/simstate-and-why/en | /articles/simstate-and-why |
最后提一下,一般来说,网站要支持多种语言,目前大家通常使用以下的两种方法实现,但是由于他们都需要特别的处理,也为了能够热切换语言,最后采用了以上这个比较简单的方法(即在路径最后增加语言表示)实现:
| 方法 | 解释 | 例子 | 问题 |
|---|---|---|---|
| 二级域名 | 每个语言的子网站都有自己的二级域名 | 淘宝 | 本质上是两个网站,当一种语言的页面不存在时,需要做跳转,懒得维护 |
| 子页面 | 每个语言采用类似https://domain.com/{zh-CN, en-US}/path/to/page的方法,通过路径的第一个部分区分不同语言 | 微软官网(切换语言的页面) | 处理路径时(例如导航栏高亮),需要单独切分掉pathname的第一部分;当一种语言的页面不存在时,需要做跳转 |
使用自己开发的simstate进行状态管理
博客一开始是使用unstated进行状态管理的。这个库非常的简单易用,很符合react的理念,于是当时我非常喜爱这个库。但是随着后来hooks的推广和unstated迟迟没有跟进hooks等原因(其实已经跟进了只是当时我的不知道……),我认为是时候写一个自己的状态管理库了。这之后故事可以查看Simstate and Why文章,这里就不说了。
在v3.0时,我重构了simstate,完全抛弃了class的概念,完全使用React原生的hook就可以完成状态管理。而博客就是第一个完全采用simstate v3.0的项目。
在使用新版本的时候,我也积累了一些在项目中正确使用此项目的经验,例如说:
- Store取名最好是大写字母开头,因为在使用的时候经常出现
const aStore = useStore(AStore);的代码,若使用小写字母开头,这代码会编译失败。这也可以帮助同时使用多个Store的情况时,区分不同的Store实例;...
剩余内容已隐藏