注:本文已发布超过一年,请注意您所使用工具的相关版本是否适用
本系列为 Go 进阶训练营 笔记,访问 博客: Go进阶训练营, 即可查看当前更新进度,部分文章篇幅较长,使用 PC 大屏浏览体验更佳。
序
3 月进度: 09/15
隔离设计源于船舶行业,一般而言无论大船还是小船,都会有一些隔板,将船分为不同的空间,这样如果有船舱漏水一般只会影响这一小块空间,不至于把整个船都给搞沉了。
同样我们的软件服务也是一个道理,我们要尽量避免出现一个问题就把这个业务给搞挂的情况出现。
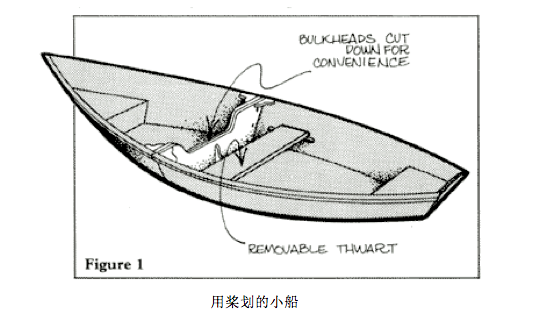
一般而言类似的文章都会告诉大家服务隔离应该分为哪里类型,或者那些级别,然后一般分别怎么做,今天我们换一个套路,我们从一个服务演进的角度来看,我们服务隔离是怎么做的
服务的演进
PS: 接下来的部分架构纯属瞎扯,但是道理是差不多的,辛苦各位凑合看一下了
如下图,今天天气不错,我们开始创业(天气和创业有啥关系???),搞了一个电商网站,由于前期人手不足技术也不够,就一个服务和一个数据库就开始对外提供服务了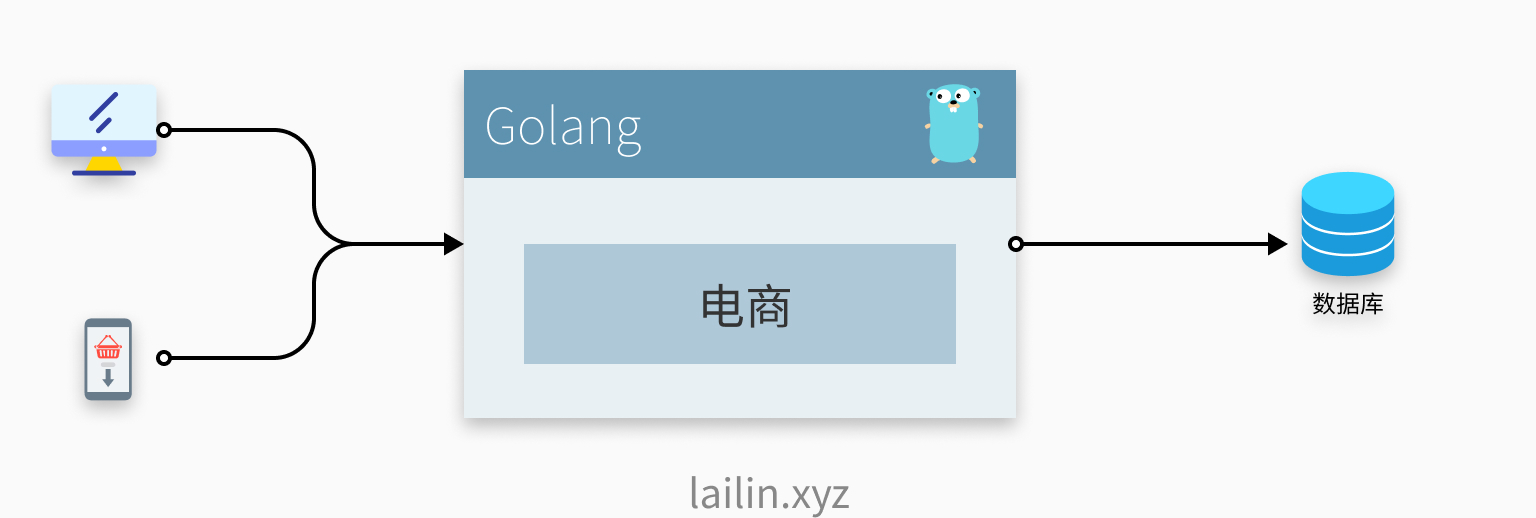
随着货物的不断上架,我们发现产品相关介绍的图片、视频等信息占用了我们服务的大部分带宽,并且也不太好管理,用户访问呢也比较慢,影响了剁手的体验,这时候我们做了一波优化,把静态资源的数据使用云服务商提供的对象存储给保存了起来,然后在前面接入了一个 CDN 给用户提供更好的体验。
这就是第一次隔离,动静隔离,我们使用对象存储和 CDN 将静态资源和动态 API 进行了隔离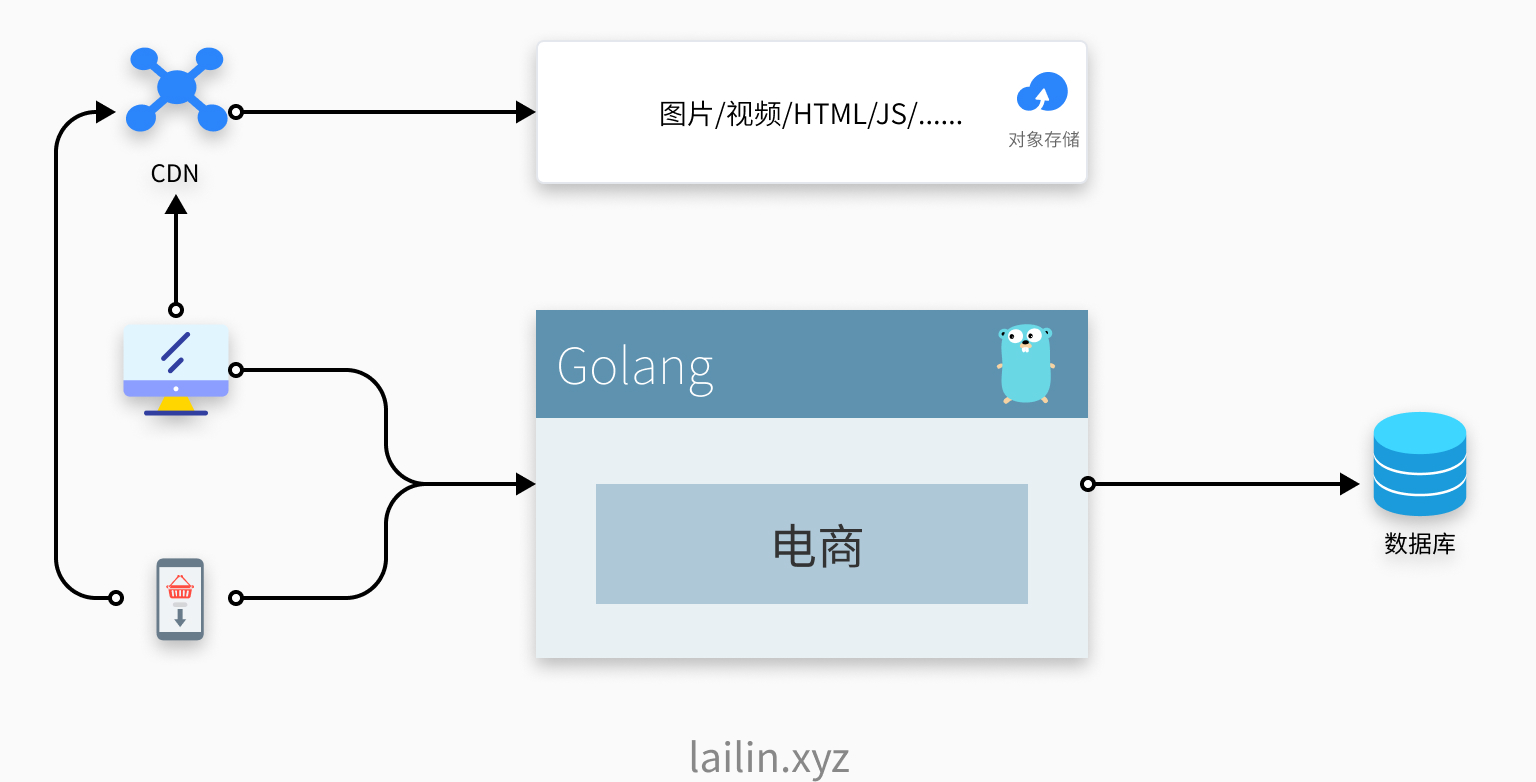
然后突然有一天我们发现,用户大量投诉说什么垃圾网站,突然访问这么慢,进过紧锣密鼓的排查发现,原来是我们的运营同学在后台进行数据统计准备出报告的时候影响了生产的数据库,导致影响了我们的用户。
这怎么能行呢,怎么可以影响我们的衣食父母,所以我们有进行了一波优化,我们对数据库进行了主从分离,然后将运营后台和我们的商城主服务做了拆分,后续所有的统计查询请求我们都从从库查询,其他请求才会去修改主库。
是滴,我们又做了一次隔离,一个是将数据库做了主从隔离,另外一个按照不同的用户属性,做了用户隔离。当然这是比较宏观的在这过程中我们肯定也会对数据中的表进行一些拆分设计,例如将经常变化的数据和不太经常变化的数据分配到两张表等。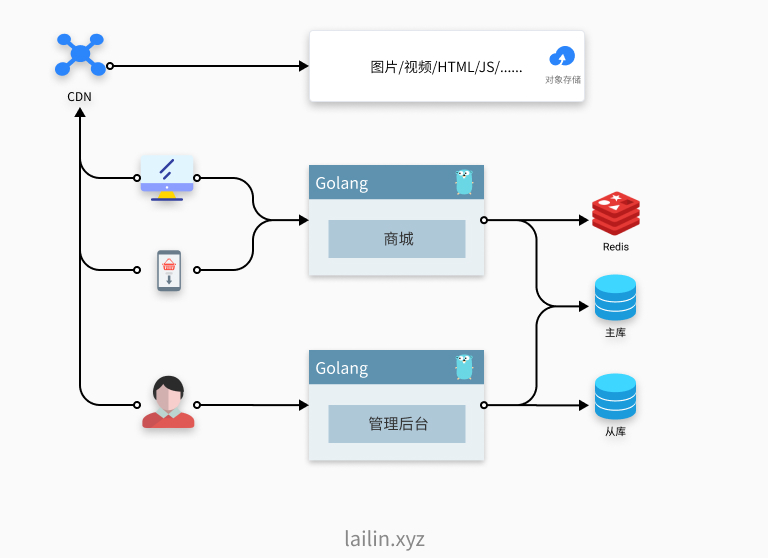
不知道是随着一些爆款活动的推出,以及不知名大 V 的推广使得我们的业务欣欣向上,还是我们新来的技术总监为了 KPI 我们进行了轰轰烈烈的微服务改造的活动,最后经过长达一年多的改造,我们的服务架构改造成了下面这个模样。
我们的请求在访问之前都会先经过 WAF 防火墙,然后再到对应的 CDN 节点然后经过我们的 API 网关到 BFF 层。然后 BFF 层再去调用各种服务聚合成业务数据并且返回。
我们其实又做了一层按照服务的隔离,我们将一个单体服务拆分成了一个个的小服务,就不会出现评论挂掉了导致整个服务挂掉无法下单的情况。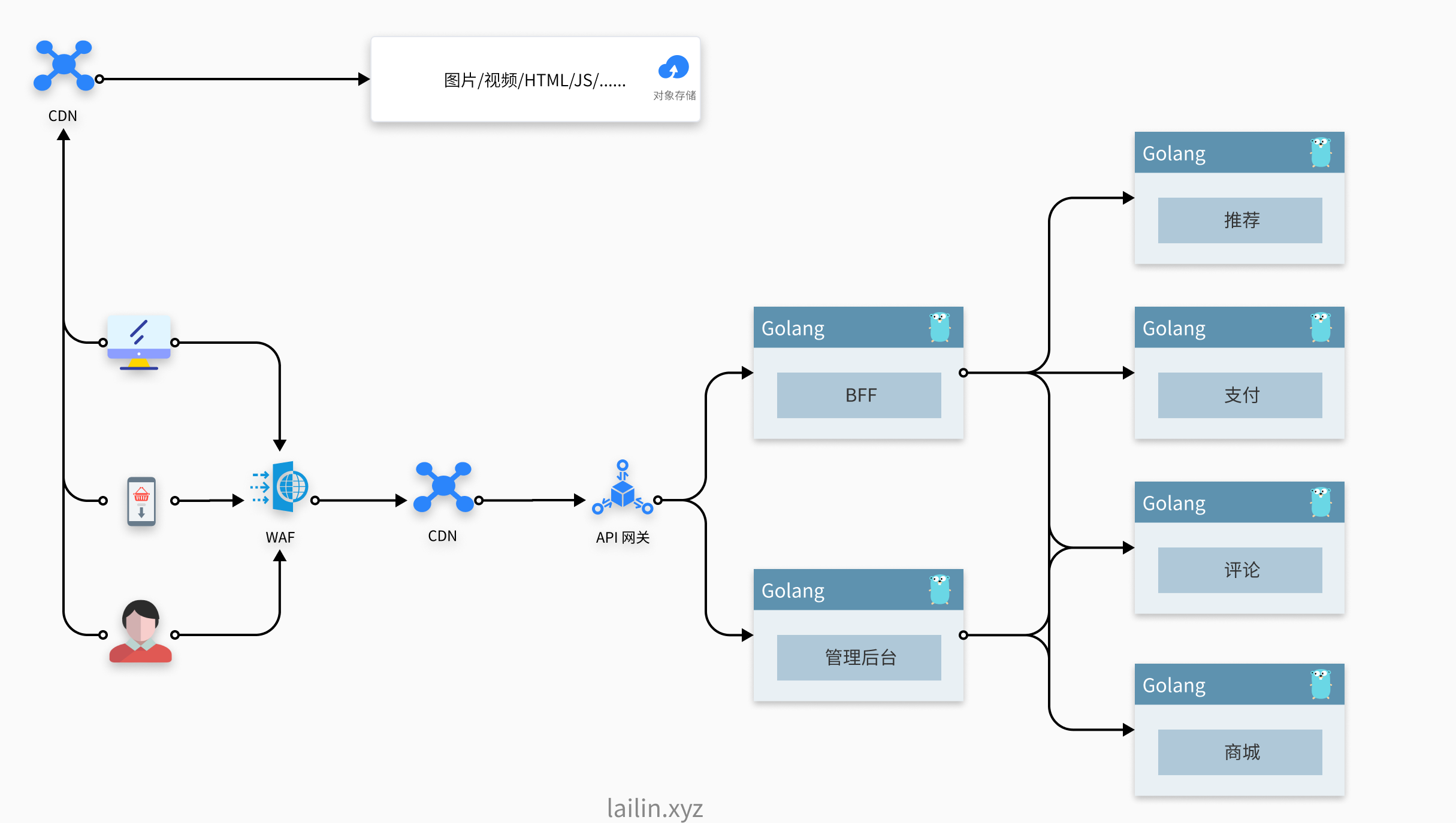
微服务改造完成之后我们发现,的确整体的服务质量都好了很多,但是突如其来的一个 bug 导致我们的监控大量告警,这是为什么呢,原来是我们的推荐服务出现了一个内存泄漏的问题,然后我们的服务限制做的不够好根本没有设置任何限制,这就导致它占用了资源池中的大量资源,让我们的其他服务资源紧缺。
然后我们就又做了一个改造,我们把支付和商城这种最重要的业务单独放在了一个池子里面,对于像评论推荐这种没有那么重要的业务放在共享的资源池当中。
所以这一次我们按照服务的优先级进行了隔离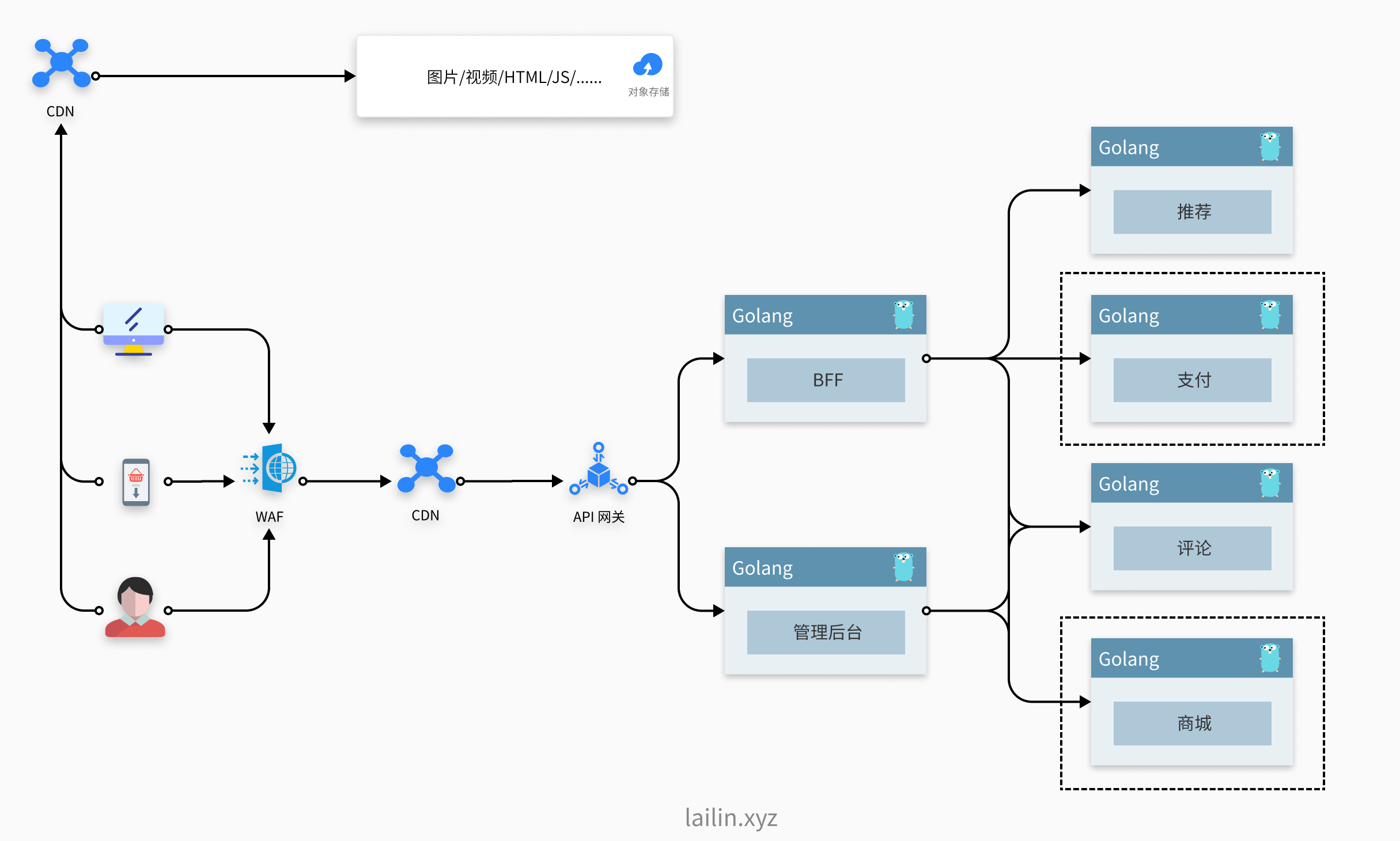
然后突然有一天,我们的一个商品成为了爆款,大量用户涌入访问,成功将我们的 cache 打挂,后续我们做了什么改动呢,我们将 remote cache 提升为了 local cache,在 sdk 当中自动识别出热点流量,然后将其缓存,大大减少了 redis 的压力
这一次我们就将热点数据进行了隔离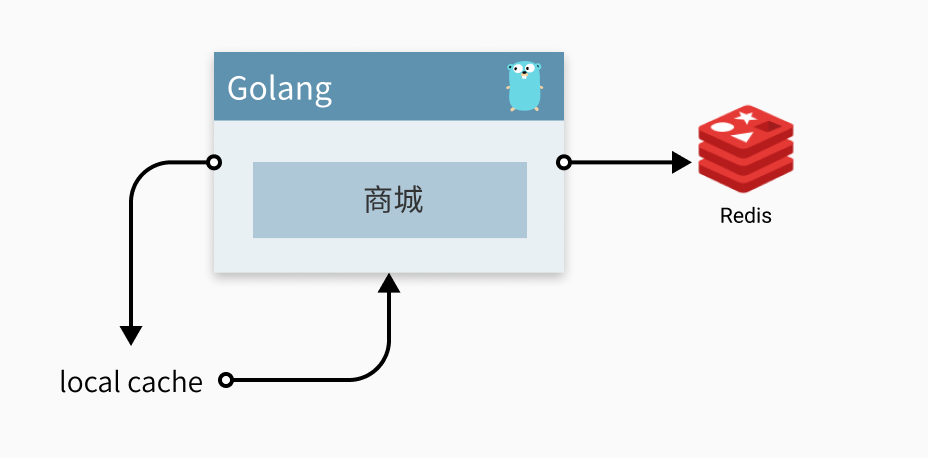
好啦,瞎扯结束总结一下吧
总结
通过上面纯属虚构的面向事故驱动的例子,我们可以发现,我们隔离设计一般分为以下几种:
- 服务隔离
- 动静隔离:例如上面讲到的 CDN
- 读写隔离:例如上面讲到的主从,除此之外还有常见的 CQRS 模式,分库分表等
- 轻重隔离
- 核心隔离:例如上面讲到将核心业务独立部署,非核心业务共享资源
- 热点隔离:例如上面讲到的 remote cache 到 local cache
- 用户隔离:不同的用户可能有不同的级别,例如上面讲到的外部用户和管理员
- 物理隔离
- 线程:常见的例子就是线程池,这个在 Golang 中一般不用过多考虑,runtime 已经帮我们管理好了(后续有一个系列讲这个)
- 进程:我们现在一般使用容器化服务,跑在 k8s 上这就是一种进程级别的隔离
- 机房:我们目前在 K8s 的基础上做一些开发,常见的一种做法就是将我们的服务的不同副本尽量的分配在不同的可用区,实际上就是云厂商的不同机房,避免机房停电或者着火之类的影响
- 集群:非常重要的服务我们可以部署多套,在物理上进行隔离,常见的有异地部署,也可能就部署在同一个区域
今天的内容就到这里,画图真的好费时间,下篇文章讲一讲过载保护-令牌桶,敬请期待
参考文献
关注我获取更新


