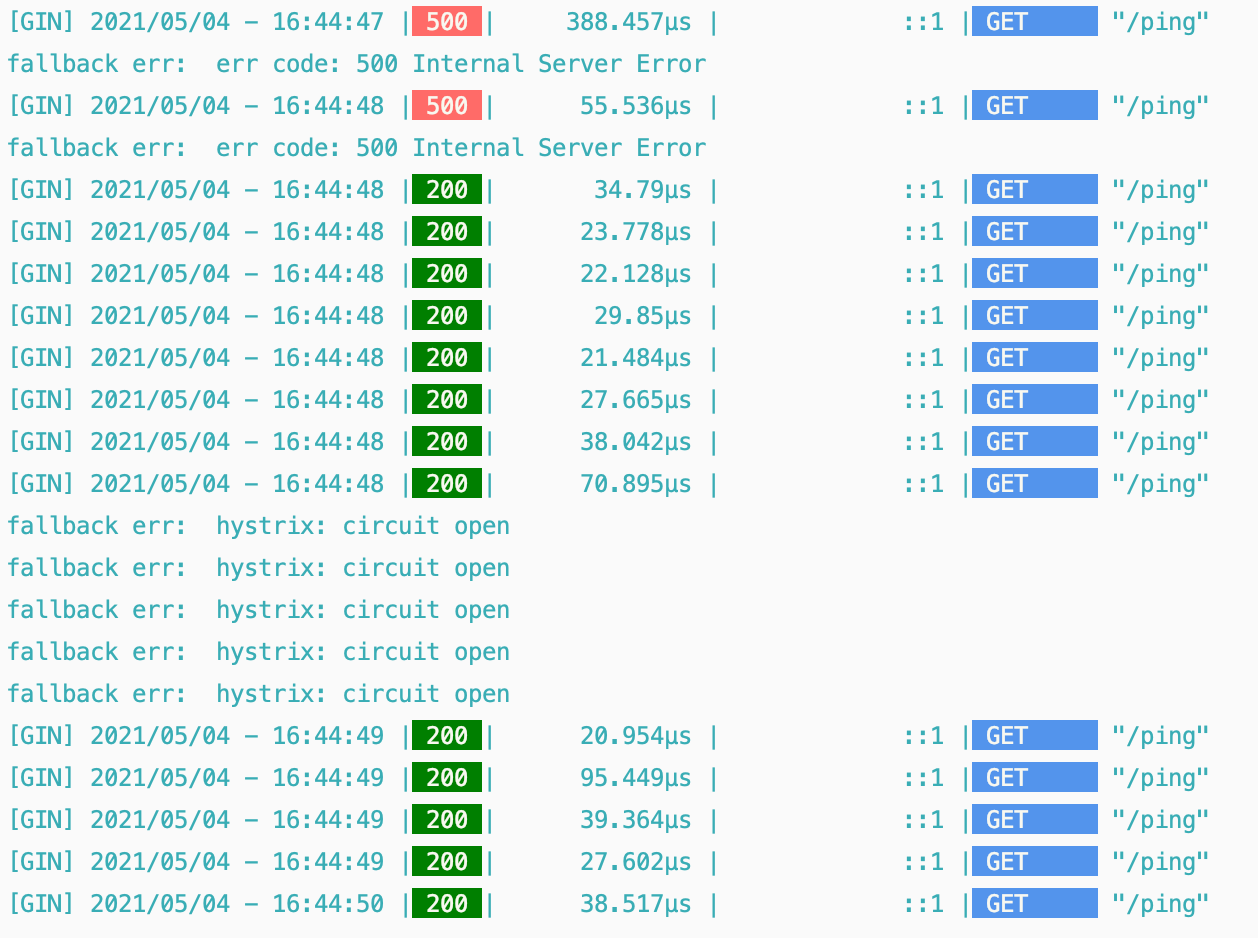
func(b *sreBreaker)Allow()error { // 统计成功的请求,和总的请求 success, total := b.summary()
// 计算当前的成功率 k := b.k * float64(success) if log.V(5) { log.Info("breaker: request: %d, succee: %d, fail: %d", total, success, total-success) } // 统计请求量和成功率 // 如果 rps 比较小,不触发熔断 // 如果成功率比较高,不触发熔断,如果 k = 2,那么就是成功率 >= 50% 的时候就不熔断 if total < b.request || float64(total) < k { if atomic.LoadInt32(&b.state) == StateOpen { atomic.CompareAndSwapInt32(&b.state, StateOpen, StateClosed) } returnnil } if atomic.LoadInt32(&b.state) == StateClosed { atomic.CompareAndSwapInt32(&b.state, StateClosed, StateOpen) }
// 计算一个概率,当 dr 值越大,那么被丢弃的概率也就越大 // dr 值是,如果失败率越高或者是 k 值越小,那么它越大 dr := math.Max(0, (float64(total)-k)/float64(total+1)) drop := b.trueOnProba(dr) if log.V(5) { log.Info("breaker: drop ratio: %f, drop: %t", dr, drop) } if drop { return ecode.ServiceUnavailable } returnnil }
func(b *sreBreaker)Allow()error { // 统计成功的请求,和总的请求 success, total := b.summary()
// 计算当前的成功率 k := b.k * float64(success) if log.V(5) { log.Info("breaker: request: %d, succee: %d, fail: %d", total, success, total-success) } // 统计请求量和成功率 // 如果 rps 比较小,不触发熔断 // 如果成功率比较高,不触发熔断,如果 k = 2,那么就是成功率 >= 50% 的时候就不熔断 if total < b.request || float64(total) < k { if atomic.LoadInt32(&b.state) == StateOpen { atomic.CompareAndSwapInt32(&b.state, StateOpen, StateClosed) } returnnil } if atomic.LoadInt32(&b.state) == StateClosed { atomic.CompareAndSwapInt32(&b.state, StateClosed, StateOpen) }
// 计算一个概率,当 dr 值越大,那么被丢弃的概率也就越大 // dr 值是,如果失败率越高或者是 k 值越小,那么它越大 dr := math.Max(0, (float64(total)-k)/float64(total+1)) drop := b.trueOnProba(dr) if log.V(5) { log.Info("breaker: drop ratio: %f, drop: %t", dr, drop) } if drop { return ecode.ServiceUnavailable } returnnil }
![熔断器<sup id="fnref:2" class="footnote-ref"><a href="#fn:2" rel="footnote"><span class="hint--top hint--rounded" aria-label="熔断原理与实现Golang版 https://www.jianshu.com/p/0ee350cde543
">[2]</span></a></sup>](https://img.lailin.xyz/image/20210504154754.png)