范式转变
最开始,我们仅能使用 AI 做函数生成,tab 补全等非常基础的编程辅助。那时候,只有 VSCode Copilot,那时候,很多人还看不起 AI 编程。
Deepseek 带来的开源思维链也仅仅是今年春节才爆火起来。 时间没过多久,思维链、工具调用、Agent、超长上下文一个接一个出现,Claude 3.5 Sonnet 出现之后,AI 编程范式似乎一夜间就改变了。
本来他充其量只是个助手,现在起码是能干活的中级工程师。项目搭建、组件重构,指挥得当他都能完成。
而且现在重构试错成本巨低,以前做一次重构发现效果不太好,代码都舍不得删,现在好了,半天够换着方法重构好几遍了。
Andrej Karpathy 创造了 Vibe Coding(氛围编程)这个词。他本人通过不断接受 AI 建议(“我总是接受所有建议,我不再阅读差异”),将错误信息复制粘贴给 AI,快速构建 Web 应用。在最近 AI IDE 井喷之后,大家应该或多或少都能意识到 Vibe Coding 是真的可行的。
提示词工程
Garbage in, garbage out
AI 发展至今,提示词工程的效果逐渐弱化,AI IDE 和插件本身就自带好几千字甚至上万字的系统提示词,有时候自己附加提示词他甚至会无视(例如你很难让 Augment 不要写测试、文档,他总会自动写)。
角色扮演和思维链之类的提示词效果已经不明显,进入玄学的提升范畴。在 IDE 里现在比较好用的提示词应该基本只剩单样本和少样本提示词 (One-Shot & Few-Shot)。
还有一个流派是给 IDE 设定一堆 Rule 提示词:
又或者 Kiro 搞的那套:
- 阶段 1:需求澄清,将模糊想法转化为结构化需求文档
- 阶段 2:设计与研究,基于需求开发综合设计方案
- 阶段 3:任务规划,基于需求和设计创建可执行的实施计划
- 阶段 4:任务执行,按照 SPECS 文档执行实施任务
我曾经做过一次完整的流程,检查需求文档耗费精力,做一堆任务耗费时间也耗费 Token,结果没有特别好。kiro 自动生成的 task,最后几步可能会搞些看起来很高级的优化,但实则不推荐,本着能用就行的原则,一路上只要你觉得代码符合你的审美,最后的优化可能是过度优化。
总结下来,就是提示词优先提供信息型的内容,而不是指令型的内容。
上下文工程
Augment Code 是现在最好用的 AI IDE 插件,其中 Context Engine 和 Diagnostics 是两个非常强大的功能。
Context Engine:
Diagnostics:
这就是所谓的上下文工程,其核心是检索、工具、记忆,通过这三种内容的组装,系统自动帮助用户收集上下文。
但问题是不是所有工具都这么完善,未来上下文工程可能会发展得更完美,但现在还是处于比较初级的阶段。现阶段我们还是经常需要主动收集上下文提供给大模型。
主动提供上下文
下面介绍一些我平时会用的上下文获取方法。
UI 实现
对于多模态模型,图片是上下文的一部分,使用图片实现 UI 是很基础的操作。
现阶段要做到像素级的还原度,是不可能的,不过有一些值得注意的点,可以稍微提高生成质量。
使用图片时,可以先让 AI 描述图片内元素的基本布局,甚至引导它描述部分细节,如果它一开始就描述不准确,那后面就不用期待它能写对了。
为自己的代码库生成一个组件列表,让 AI 在从图片实现页面时在里面挑组件,必要时还是要主动告诉它需要什么已经抽象过的组件,因为光看名字很可能看不出来。
v0 是一个超强的截图转代码工具,还原度比直接用 Claude 高非常多。
修复 problem
[
{
"resource": "/d:/gpu/src/pages/ResourceManagement/TeamResourceManagement.tsx",
"owner": "_generated_diagnostic_collection_name_#4",
"code": {
"value": "lint/style/useImportType",
"target": {
"$mid": 1,
"path": "/linter/rules/use-import-type",
"scheme": "https",
"authority": "biomejs.dev"
}
},
"severity": 8,
"message": "All these imports are only used as types.",
"source": "biome",
"startLineNumber": 35,
"startColumn": 8,
"endLineNumber": 35,
"endColumn": 26,
"origin": "extHost1"
}
]
Apifox 复制
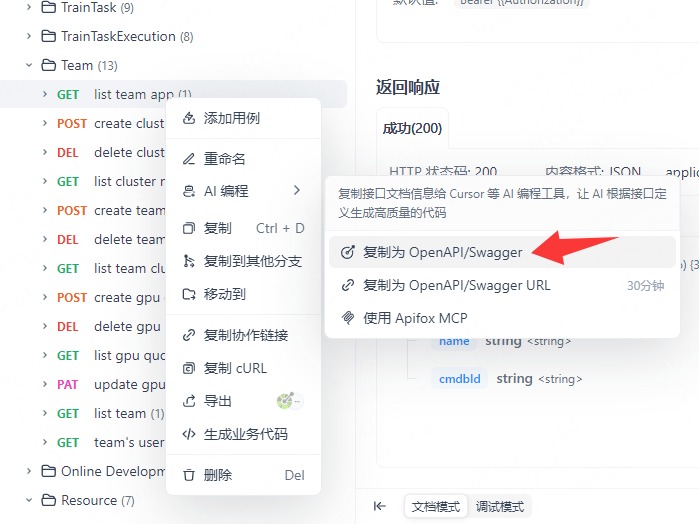
可以在 Apifox 直接复制接口的 OpenAPI 规范,贴进去让 AI 加 api 十分方便且可靠。
openapi: 3.0.1
info:
title: ""
description: ""
version: 1.0.0
paths:
/api/v1/team/app/list:
get:
summary: list team app
deprecated: false
description: ""
tags:
- Team
parameters:
- name: teamId
in: query
description: ""
required: true
schema:
format: int
type: integer
- name: page
in: query
description: ""
required: false
schema:
default: 1
format: int
type: integer
- name: size
in: query
description: ""
required: false
schema:
default: 10
format: int
type: integer
- name: Authorization
in: header
description: ""
example: Bearer {{Authorization}}
schema:
type: string
default: Bearer {{Authorization}}
responses:
"200":
description: ""
content:
application/json:
schema:
$ref: "#/components/schemas/mlops.api.team.v1.ListTeamAppRes"
description: ""
headers: {}
x-apifox-name: 成功
security: []
x-apifox-folder: Team
x-apifox-status: released
x-run-in-apifox: https://app.apifox.com/web/project/6423715/apis/api-326223640-run
components:
schemas:
mlops.api.team.v1.ListTeamAppRes:
properties:
apps:
format: "[]*dto.App"
items:
$ref: "#/components/schemas/mlops.internal.model.dto.App"
description: ""
type: array
type: object
x-apifox-orders:
- apps
x-apifox-ignore-properties: []
x-apifox-folder: ""
mlops.internal.model.dto.App:
properties:
id:
format: int
type: integer
name:
format: string
type: string
cmdbId:
format: string
type: string
type: object
x-apifox-orders:
- id
- name
- cmdbId
x-apifox-ignore-properties: []
x-apifox-folder: ""
securitySchemes: {}
security: []
附带最佳实践
多数解现象是指 AI 模型倾向于生成训练素材中最常见、最直接的解决方案。换言之,训练素材只能反映那个语言的平均编码能力。尤其是 React,React 的思维负担是非常重的,这是框架本身的问题,架不住素材实在多,所以它几乎总能写出“能跑”的代码,事实上一看很多严格的规则都会标红,很多实现不是最优解。
这可能导致 AI 写的代码在通用场景下正确,但在特定项目背景下并非最优,甚至,仅仅是能用的屎山,而且放任 AI 多数解也可能造成代码膨胀。
因为多数解现象的存在,开发者必须识别这些潜在的假设和非最优选择,并根据实际需求进行调整。
在前端开发领域,由于门槛低,谁都能写,可能会导致一些代码质量问题,这些有问题的代码如果作为训练数据就会加重上述的多数解问题。所以作为前端开发,可能需要在上下文附加 React 最佳实践。
写 ChangeLog
获取上次发版的 git 提交哈希,跟 AI 说从根据这个哈希的提交开始到最新的提交生成 ChangeLog。他就会自动通过 git 命令收集需要的信息给你输出。
给一个模板可以保证 ChangeLog 格式统一。
## v1.0.0 (2025-01-15)
**功能描述 - 简短的版本亮点描述**
**代号: 项目代号**
### ✨ 新功能
- **核心功能增强** - 改进了应用程序的整体性能和稳定性
- **更好的文件格式化** - 保存的文件现在具有适当的缩进以提高可读性
### 🔧 改进
- **更新的macOS图标** - 刷新应用程序图标以更好地集成macOS
- **增强的性能** - 各种底层改进以获得更好的用户体验
### 🐛 修复
- **修复了登录问题** - 解决了某些情况下用户无法登录的问题
- **修复了数据同步** - 改进了数据在设备间的同步稳定性
### 🚀 性能优化
- **启动速度提升** - 应用程序启动时间减少了30%
- **内存使用优化** - 降低了内存占用,提高了运行效率
### 📚 文档更新
- **更新了用户手册** - 添加了新功能的详细说明
- **API文档完善** - 补充了缺失的API接口文档
### ⚠️ 重大变更
- **API变更** - 某些API接口进行了重构,请查看迁移指南
- **配置文件格式** - 配置文件格式有所变更,需要手动更新
---
**升级说明:**
- 建议在升级前备份重要数据
- 详细的升级指南请参考官方文档
当然,前提是你的 commit message 要写得很标准。
DeepWiki
DeepWiki 是一个超赞的仓库 wiki 生成工具,只要你提供 GitHub 地址,它就能给这个仓库生成一个颇为完整的 wiki 页面。
同时,DeepWiki 提供 MCP 能力:
{
"mcpServers": {
"deepwiki": {
"serverUrl": "https://mcp.deepwiki.com/sse"
}
}
}
通过 ask_question 工具可以让你的 AI 工具向 Deepwiki 提问,如果你使用的某个冷门库文档没写好,或许可以直接用这个工具得到解决方案。
对于你自己写的项目,也可以 AI 生成文档,你审阅后没问题,这就能成为下次提问的上下文。
llms.txt
llms.txt 是一个专门给 AI(大语言模型)看的“摘要文件”,就像给人类看的 README.md 一样,但格式更简洁、结构化,方便 AI 快速理解你的网站或项目。
- 位置:放在网站根目录,如
https://example.com/llms.txt - 格式:纯文本(UTF-8),类似简化版 Markdown
- 用途:告诉 AI 你的网站有哪些关键页面、API 文档、SDK 下载地址等,避免它去爬整个站点
- 对比:
robots.txt:告诉搜索引擎哪些页面不要爬sitemap.xml: 单纯的网站地图,包含站点所有链接llms.txt:告诉 AI 哪些页面值得看,并附有页面介绍
很多技术文档(如 Apple 的)用 JavaScript 动态加载,AI 直接访问只能看到空白页。而 llms.txt 提前把关键信息整理成静态文本,AI 就能直接读取并生成更准确的代码或回答。对于 llms.txt 里提及的地址,规范也建议网站在原始 URL 后添加 .md 扩展名,提供页面的纯Markdown版本。
例子:
# FastHTML
> FastHTML is a python library which brings together Starlette, Uvicorn, HTMX, and fastcore's `FT` "FastTags" into a library for creating server-rendered hypermedia applications.
Important notes:
- Although parts of its API are inspired by FastAPI, it is _not_ compatible with FastAPI syntax and is not targeted at creating API services
- FastHTML is compatible with JS-native web components and any vanilla JS library, but not with React, Vue, or Svelte.
## Docs
- [FastHTML quick start](https://fastht.ml/docs/tutorials/quickstart_for_web_devs.html.md): A brief overview of many FastHTML features
- [HTMX reference](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Brief description of all HTMX attributes, CSS classes, headers, events, extensions, js lib methods, and config options
## Examples
- [Todo list application](https://github.com/AnswerDotAI/fasthtml/blob/main/examples/adv_app.py): Detailed walk-thru of a complete CRUD app in FastHTML showing idiomatic use of FastHTML and HTMX patterns.
## Optional
- [Starlette full documentation](https://gist.githubusercontent.com/jph00/809e4a4808d4510be0e3dc9565e9cbd3/raw/9b717589ca44cedc8aaf00b2b8cacef922964c0f/starlette-sml.md): A subset of the Starlette documentation useful for FastHTML development.
一些生产例子:
| 站点 | 地址 |
|---|---|
| Vite | https://vite.dev/llms.txt |
| Svelte | https://svelte.dev/llms.txt |
| Windsurf | https://docs.windsurf.com/llms.txt |
| Ant Design | https://ant.design/llms.txt |
索引站:
这三个目录站持续收录互联网上新增的 llms.txt,可直接搜索或按标签浏览。
其他 AI 编程策略
无限重试流
失败后,直接找到他的错误,然后直接更新提示词整个重试。例如你知道他会把问题复杂化,那就一开始就把简单的思路告诉他。另外,你可以知道 AI 的能力边界后补充上下文,例如你让他用一个库实现功能,但是他并不会用,那就需要补充文档链接。
这么做的好处是整个对话中完全不存在错误的步骤,上下文是完全干净的。
Copy And Paste Great Again
类似的组件复制粘贴在前 AI 时代是一个大问题。当两个组件或函数有一点差异时,一般倾向于直接复制一份,而不是做抽象。但是后续修改时,要一一修改每一个地方,这不难,但是个体力活。
AI 时代来临后可以更放心地在初始开发时用复制粘贴这个模式。AI 可以找出类似内容批量修改,再也不需要做体力活。在后面如果真的有更多的使用情况,也可以后续再用 AI 做抽象。
毕竟过早优化是万恶之源,封装方法和组件越早,后面业务变更需要修改时就越畏手畏脚。
双向奔赴
在遇到你预感到 AI 不能或难以解决的难题时,交下任务同时可以自己再在 ChatGPT 上尝试寻找解决方案。这样有两个好处:
- 方便 AI 写完之后看懂它的实现方案
- 找到更好的方案指导 AI 优化
上面提到的多数解现象出现时就提到,AI 给出的答案只是一个均值。如有必须,我们需要进一步指引 AI 重构,例如不要啥都写 useEffect,优先事件驱动之类的。
最后还有一个隐藏的好处,就是你的思维仍然没有脱离上下文,效率会再高一点点。
启动模板
使用 AI 需要有选型能力,仅从 Web 前端角度来说,AI 擅长这个技术栈:
- 最新版 React,或次新版,防止 AI 不会写,不过随着模型进步和上下文扩大,直接加文档链接问题不大
- 最新版 Tailwind
- Shadcn/UI 用于美观的组件,AI 写这玩意写得很好,组件下载即用,颜值高,可以自己微调样式
- Vite 用于高速构建
- TypeScript 用于类型安全,现在没有 TS 已经不会写代码了
- Zustand 用于简化状态管理,同样是压缩上下文的手段,接口设计越精简,AI 适配就越好
- React Query 用于数据获取,过去手写每一个 loading 状态非常体力活,现在不怕了,直接让 AI 全写了,用户体验大提升
- ESLint 用于代码质量检查
- Prettier 用于代码格式化
候选 Biome,eslint 和 prettier 二合一的存在。处理速度很快,而且有更多代码优化规则(例如 if 提早 return 了会提示你可以省略后面的 else,AI 写出来还是基本带 else 的)
React、Tailwind 几乎是标配市面上众多 App 生成网站(Lovable、Bolt等)默认输出都是用这个组合。
上面提到的 V0 图生组件,它生成的结果就是 React 组件,用 React 就能拿来即用。
以后开源库的用户量也是变得越来越“赢家通吃”。AI 越懂的库,用户越多,用户越多,训练材料越多,AI 越容易写好,然后循环了。
前后端融合
如果一个人同时管理前后端代码,那么强烈建议前后端仓库放到一起。又或者直接回到前后端不分离的时代,潮流果然是个圈。
前后端不分离更适合没有代码基础的用户。他们本来就不清楚如何分辨前后端错误。AI Agent 能灵活获取前后端双方的代码,就能更清楚分辨是哪一方出现问题,防止在另一个代码库里做无效努力。
实际效率提升
关于 AI 编程的实际效率提升,可能没有那么明显,国外一些对照实现显示效率提升可能在 20% 左右,甚至有的实验结果是负提升。
最后 30% 的耗时
70% 问题: 许多开发者发现AI能完成约70%的初始解决方案,但剩下的 30% 令人沮丧,可能导致“一步进两步退”的问题。非工程师尤为如此,他们缺乏理解代码的底层心智模型,难以修复 AI 引入的新 bug。
对于 70% 问题,现阶段对于完全 Vibe Coding(不理解代码)的使用者应该是无解的。但是作为程序员,我们必须当心氛围编程的问题长期积累,变为粪味编程。
我们必须在每次提交前初步理解代码,懂个大概即可,遇到错误再细看。我会更习惯直接用 git 检查 AI 更新的代码,而不是用 AI 工具自带的那个采纳或拒绝,直接全部采纳然后在 git 工具用 diff 检查会比较符合我原来的习惯。
对时间的错觉
开发者花费额外时间验证、调试和调整AI的输出。AI 可能产生低性能甚至错误的代码,然后需要人工纠正。本质上,“幻觉”和错误步骤引入了额外的循环。
开发者可能过于容易接受 AI 输出,然后在错误时调试更长时间,而不是编写更简单的正确解决方案。研究指出,即使在经历减速后,开发者仍然感觉 AI 帮助了——一种认知偏见,因为 AI 让事情感觉更容易,即使它实际上并不更快。
所以尝试忽略这个“错觉”,尝试注意一下,通过等待多轮对话,纠正 AI,骂 AI,到最后真正能比自己写快多少。
更碎片的思维
尽管可以并行的任务更多,但这对人类本身大概不是好事。
这彻底打破原来有可能产生的心流,你不可能盯着 AI 编码,即使你不嫌盯着它浪费时间,你的眼睛也很难跟上它的实现。但你不盯着就意味着你打断了当前任务去干别的事了。
这会产生一个很恐怖的效果,现代人碎片化的注意力更稀碎了,可能造成注意力无法集中或记忆力减退的问题。
编码之外
AI 编码助手在提高个人编码效率方面表现出色,但在软件开发的整体流程中,仍有许多环节是 AI 难以优化的:
- 无法缩短跨团队合作时间:软件开发不仅仅是编写代码,还涉及多个团队之间的协调,或团队内部不同角色(产品、设计、前端、后端、测试、运维等)间的沟通和协作。
- 无法缩短会议时间:各种会议仍然是软件开发过程中不可或缺的环节。这些会议的目的不仅是传递信息,更是形成共识和做出决策的过程,AI 现在无法参与。
- 决策过程的复杂性:技术选型、架构设计、资源分配等决策需要考虑技术因素、业务因素、团队因素等多方面的权衡。虽然 AI 可以提供建议,但最终的决策仍然需要人类基于经验和判断来完成。
该学什么
- 学会提问
- 精进调试策略,迅速找到问题所在,为 AI debug 提供上下文
- 熟悉性能优化原理,识别 AI 实现的不足,引导优化
- 测试边界条件,学习软件测试方法,或使用 AI 编写测试代码
- 熟悉项目整体架构和运维
- 创意 UI 设计,就我看来现在即使提示词鼓励它把界面做的有创意,结果还是逃不出很普通的页面结构