你好,我是猫哥。这里每周分享优质的 Python、AI 及通用技术内容,大部分为英文。另有电报频道作为副刊,补充发布更加丰富的资讯,欢迎关注。
本期分享了 12 篇文章,12 个开源项目,全文 2000 字。
🦄文章&教程
众所周知,CSV 文件使用逗号分隔内容,但这对于存在逗号、分隔符和换行符等情况不太适用,文章建议使用 ASCII 的通用分隔符作为替代,可以处理复杂数据,避免格式出错。
2、用 Scrapy 和 Playwright 实现无限滚动页面的抓取
介绍了用 scrapy-playwright 插件实现无限滚动网页的内容抓取,包括如何配置、处理 CORS 问题、滚动抓取的原理解析、详细的实现代码。
介绍了如何用 pytest-cov 计算代码库的测试覆盖率,并用 nox 等工具对不同版本的 Python 和库进行组合测试。既测试代码本身,也测试它与整个 Python 生态的集成。
Fastcore 的作者介绍了这个库的主要功能,它主要用于扩展 Python 的能力,包括:使**kwargs 透明化、设置实例属性时规避样板代码、避免子类的样板代码、类型分派、更好的 functools.partial、更有用的 __repr__,等等。
5、Knuckledragger:一个半自动的 Python 校验助手
作者开发了 Knuckledragger,是一个基于 Z3 的半自动 Python 校验助手,文章介绍了它的基本设计原则、核心原理、理论和应用、支持的主要功能,等等。
6、优化 PyTorch Docker 镜像:如何将大小减少 60%?
在集群上训练神经网络时,常用 Docker 容器打包所有依赖项。通用配置的镜像大小达 7.6G,文章介绍了几项优化配置,可节省 60% 的空间。
求和类型(Sum Types)是类型理论中的概念,将不同的类型组合成一种单一类型。Python 不支持这种类型,文章介绍用 Pydantic 的 unions 和 TypeAdapter 来实现一个相似的类型,并完成 JSON 序列化和反序列化。
这是新发起的一个提案(草稿状态),可视为 f-string 的扩展,类似于 JavaScript 的标签模板字面量,使用自定义的函数代替“f”前缀,实现更丰富的功能,如安全检查、延迟计算、Web 模板等。
textual 框架已经很流行了呢,Github 星星近 25K。这篇文章是框架作者写于 2022 年的,分享了 7 个观点:终端速度很快、DictViews 非常棒、lru_cache 速度很快,等等。
10、通过 GDB 用 PDB 调试运行中的 Python 脚本
如何在 Linux 上调试正在运行的 Python 脚本?文章介绍了用系统原生调试器 GDB 的 attach 命令,以及 Python 自带的调试器 pdb 来调试 Python 脚本。
Copy-on-Write 是一种提高内存使用率的优化技术,Pandas 2.0 已经支持了,但未完全实现。文章介绍了如何启用 CoW,以及它对 Pandas 到底有哪些好处、启用与不启用 CoW 的差异。
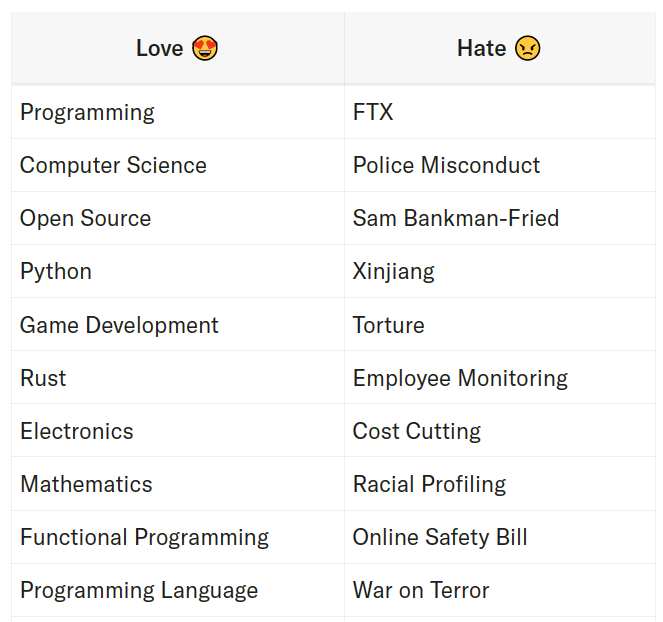
12、3.5 亿 Token 不会说谎:Hacker News 中的爱与恨
分析了 Hacker News 从 2020.1 至 2023.6 的所有帖子及其不少于 5 条评论,利用 LLama3 70B 从不同维度对这些内容做统计。用到的框架是 Netflix 开源的 metaflow,文章介绍了使用的工作流和提示词。
🐿️项目&资源
用 Rust 开发的高性能邮件校验库,比传统工具(如 python-email-validator、verify-email 和 pyIsEmail)快 100-1000 倍。
向 Python 中添加其它语言的优秀特性,如 Julia 的 multiple dispatch、Ruby 的 mixins,以及 Haskell 的 currying 和 binding 等;同时添加了不少有用的功能。
3、scrapy-playwright:Scrapy 的 Playwright 集成
集成 Scrapy 和 Playwright 的优点,遵循 Scrapy 的常规工作流,可很好处理 JavaScript 相关的内容。支持协程和 asyncio。
4、DELTADB:基于 Polars 和 DeltaLake 的数据库
用 Python 开发的轻量级可扩展数据库,提供基本的数据库操作和版本控制,由 polars 和 deltalake 提供高性能支持。
由相互协作的多个代理组成的 AGI,具备自我进化能力,可根据需要构建出新的代理来完成特定的任务。
6、llm_aided_ocr:用 LLM 矫正扫描版 PDF 的 OCR 结果
利用自然语言和 LLM,提升 OCR 对扫描版 PDF 文件的扫描准确度,将结果转换为格式良好且可读的文档。(star 1.2K)
7、translation-agent:使用反省工作流的翻译代理
Andrew Ng 开源的用于机器翻译的工作流,基本流程是先让 LLM 翻译,然后再让它提出修改建议,最后基于建议作修改。(star 4.4K)
这是一个在线学习 Python 的网站,包含一系列课程、视频、PPT 材料和参考资料等,另外发布在 Coursera、edX 等平台,参加课程可获得证书。
9、unstract:无代码 LLM 平台,启动 API 和 ETL 管道
利用 LLM 启动 API,将复杂的文档转换为结构化 JSON,或者启动 ETL 管道,从云文件/对象存储系统中读取复杂文件,并将结构化数据写入数据仓库和数据库。
10、tokencost:轻松估算 400+ LLMs的 token 价格
这个库提供了 400+ 主流 LLM 的 token 花费计算能力,跟踪最新的价格变化,有效管理对接 LLM 的成本。(star 1.3K)
11、PyOptInterface:Python 作数学优化的高效建模接口
数学优化建模,性能超过了 Pyomo 和 JuMP.jl 等,适合大规模数学优化问题(线性规划、二次规划、混合整数线性规划等)的建模和求解。
12、metasequoia-sql:注重性能的 SQL 语法解析和分析器
适用于 SQL 的格式化、执行和分析场景,致力于打造性能最高的 Python 版 SQL 解析器,包含词法树解析、语法树解析和语法树分析等功能。
🐧 往年回顾
Python 潮流周刊#15:如何分析异步任务的性能?(2023.08.12)
🐱欢迎订阅
技术周刊是聪明人在信息过载时代中筛选优质知识的聪明手段。这是一个专为国内 Python 开发者量身打造的资讯平台,为你挑选最值得分享的文章、教程、开源项目、软件工具、播客和视频、热门话题等丰富内容。立即订阅,每周将收到一篇文章推送,每周进步一点点。
欢迎留言,说说你最喜欢本期的哪一则分享?大家反馈得越多,我今后分享的也会越多!
欢迎将本专栏分享给同样爱学习的同学,当有人通过你分享的海报或者链接,购买了专栏,那么你将获得高额的返利。