回顾
本篇文章我们针对于上文”电商搜索业务总结“中的业务需求进行拆解,并以技术角度进行分析。
- 对于关系好的商户我想把他们的品牌优先展示,增加曝光率
- 新上架一款商品,我想立即在平台上搜索到
- 当我使用具体款号搜索时,我希望只展示这一款的商品
- 我希望在搜索结果页中看到更多的品牌,而不是整页都是同一个品牌
- 对于有品牌中有奇葩的字符时,我希望搜索能够正常的处理
- 我希望热词搜索能够展示每日 Top 10 的数据并且支持自定义
- 搜索建议词要求按“品牌+品类”、“品类+品类”的格式展示
- 商品撤柜(合同到期)、关网销(不在线上卖)、下架(有问题)时要及时的清除这些商品
- 针对于搜索结果,我要统计其中品牌品类以及门店的信息
- 我希望能在搜索时进行价格区间、折扣区间、分类、门店进行过滤
- 我希望能在搜索时能按上新时间、销量、价格进行排序
- 我希望在搜索“阿迪“时,能查询到阿迪达斯、阿迪王、三叶草等商品
术语
在分析需求前,我先将搜索中常用的术语先列一下,便于后面的展开:
- 文档:结构化的数据,比如一件衣服的数据信息
- 字段:文档中的基本组成部分,一个文档中可包含一个或多个字段
- 索引:根据设置选取某个字段建立倒排索引,和数据库索引意思类似,都是为了加快查询速度
- 组合索引:我们可以将多个字段放到同一个索引中,查询时会同时在这些字段中进行查找
- 分词:总体上讲就是将一个字符串按一定的逻辑拆成几个小的子序列
- 模糊搜索:当搜索意图不明确时,比如只记得几个字,但是不知道全称叫什么情况下使用,模糊搜索会降低精准度
- 短语搜索:希望保持查询的内容相对顺序和位置,这会提高精准度,但是会减少召回数量
- 召回:从索引中返回命中的文档
- 粗排(基础排序):从海量的索引中取出匹配度高的 TopN 的文档取出
- 精排(业务排序):在精排的基础上,根据具体的业务规则进行排序
- 布尔查询:高级搜索功能,利用 OR、AND 等来影响召回数量,多用在过滤条件
- 纠错:将搜索词中有问题的字进行修改替换,比如,”连衣群“纠错后变成“连衣裙”
- 打分:每个文档自身都会有一个分数,分数越高表示越匹配用户输入的内容
- 权重:业务排序参考的部分,比如夏天了,把夏季这个属性的权重调高,那么排序时会优先展示权重高的内容
- 同义词:例如 Adidas 和阿迪达斯
- 停用词:在构建索引时要排除的内容,一般是标点、语气词等助词
- 统计:对查询结果的某个字段进行统计,比如 100 件衣服里是李宁品牌的有几件
- 全量更新:将索引全部更新一遍,耗时高,一般会在访问量小的时间进行
- 增量更新:更新部分索引,平时更新都是增量更新
- 索引重建:当更新了索引结果或者改了字段类型那么就需要重建索引
需求分析
从业务需求中,我们可以宏观上分成个两个部分:查询部分和索引部分,查询部分是我们从输入一个关键字开始到返回查询结果结束之间的内容,那查询的数据从哪来呢,这就是索引部分要做的事情,简单讲就是将我们业务系统中的非结构化的数据转换成需要的结构化数据过程。下面我们展开来讲。
索引部分
我们在业务系统中经常会使用 MySQL 进行数据持久化,MySQL 的 InnoDB 存储引擎会使用 B+ 树来存储索引,B+ 树的查询效率已经很高了,那么我们为什么不直接将 MySQL 用作电商搜索呢,这不是本文的重点,但你可以参考这几篇文章
Elasticsearch 中为什么选择倒排索引而不选择 B 树索引
数据源
搜索索引的数据一般都是来源于业务系统,在电商领域中分散在多个系统中,主数据(款、色、规、季节、名称、图片),库存,价格,销量,门店,供应商,我们需要将这些属性合并到一个结构中,然后针对需要查询的字段建立合适的索引,这样搜索引擎中就有了索引数据。
此时我们要考虑数据变化后,索引如何更新,商品信息并非一成不变,下单、加购、降价、撤柜等都会带来一系列的变化,那我们如何获取到这些变化呢?
Dump 架构设计
- 新上架一款商品,我想立即在平台上搜索到
- 对于有品牌中有奇葩的字符时,我希望搜索能够正常的处理
- 商品撤柜(合同到期)、关网销(不在线上卖)、下架(有问题)时要及时的清除这些商品
在电商最开始时,没有太大的用户量,而且为了快速试错,可用采用简单粗暴的方式
定时任务同步
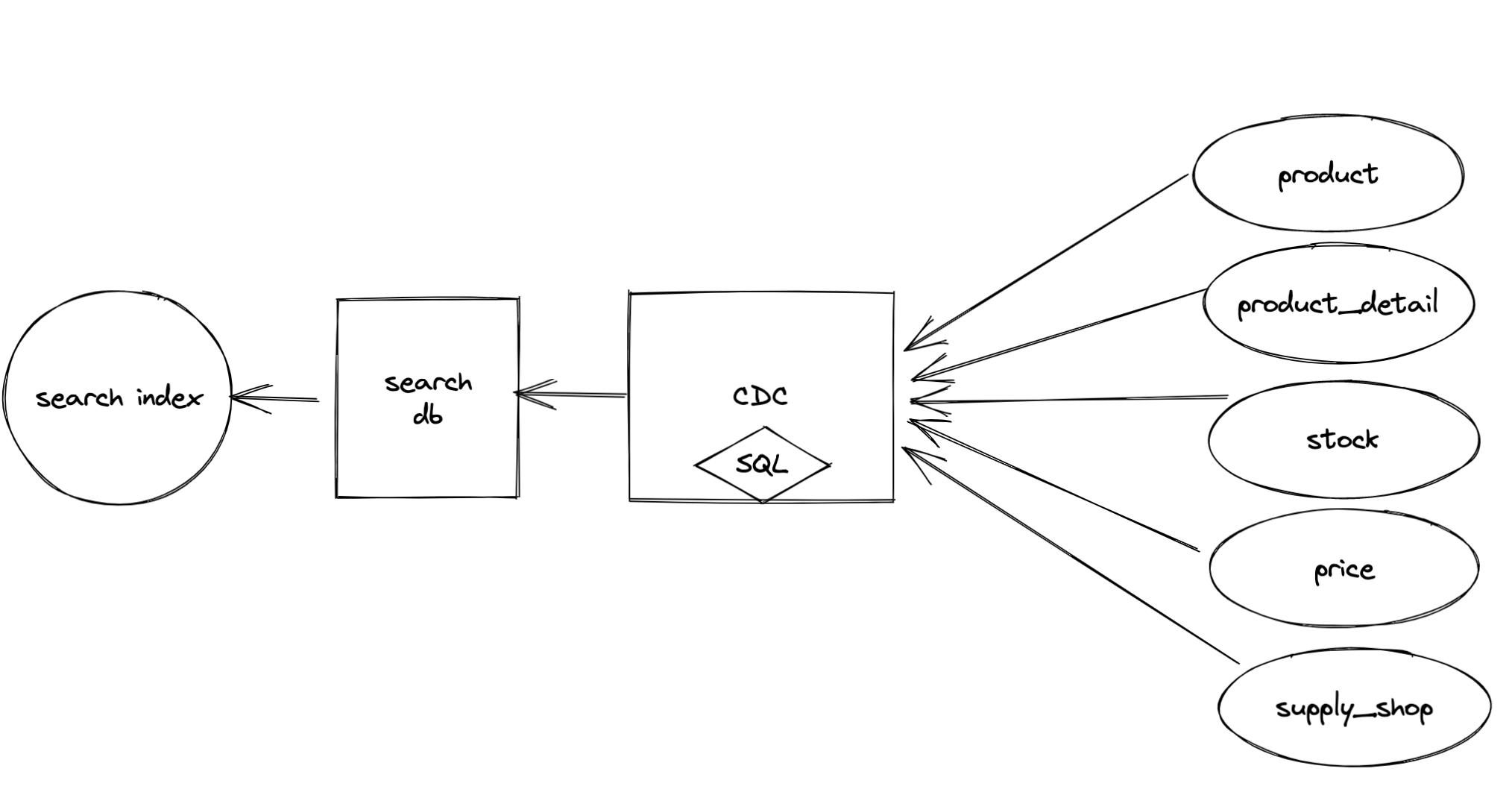
写 SQL,多表联查,建立搜索宽表,定时任务同步,同步完后直接针对变更的数据进行增量更新索引
优点:快速上线
缺点:延时高、效率低、耗资源
Binlog 同步
CDC 服务
CDC(Change Data Capture) 是指通过监听数据的一系列变化而做出相应的处理,对于 MySQL 我们能利用 binlog 的方式对表的 DML 操作进行记录,但是通常情况下数据库变化很快,我们的下游系统可能无法快速处理,此时就需要在中间加入消息队列进行缓冲。
如今有很多的开源或者原产品都提供了 CDC 功能,比如国内流行的 Canal、云产品 DTS。我们可以在技术方案调研后选择合适的产品。
优点:近实时更新
缺点:链路被拉长,复杂度上升,运维成本高
Binlog 同步方式的数据流通如下:
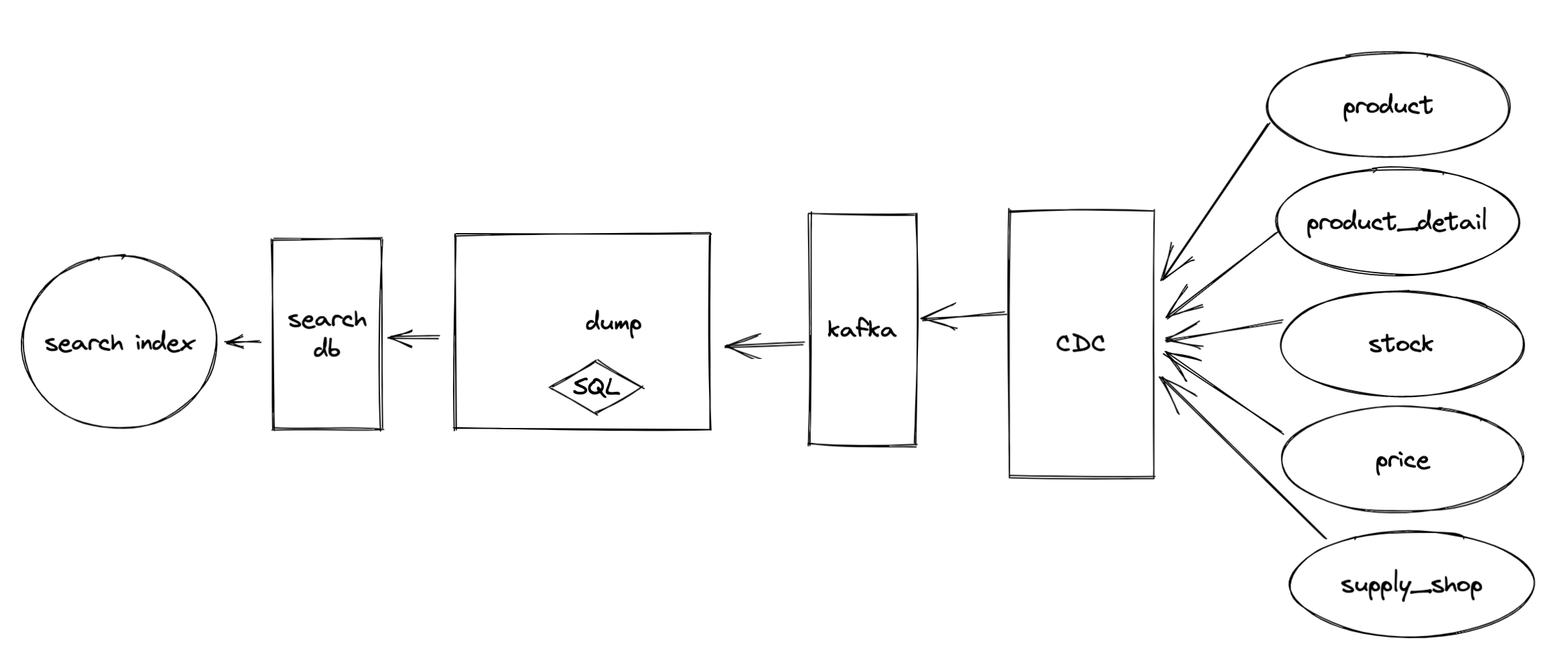
说明:图中 dump 服务的 SQL 的作用是,为了得到索引的结构化数据。因为从队列中获得的是针对商品的某个部分信息,我们要利用这些信息通过 SQL 查询重新查询一次,这样做的好处依然是简单,在中小型企业来说非常合适。search db 是搜索的宽表,这个宽表的作用是方便迁移搜索引擎,比如 Solr、ElasticSearch、OpenSearch,都支持表同步。
查询部分
查询部分涉及到的点很多,但是流程基本上是类似的,我们从一个问题展开讲
用户在输入一个关键字以后,搜索系统内部是如何处理的?
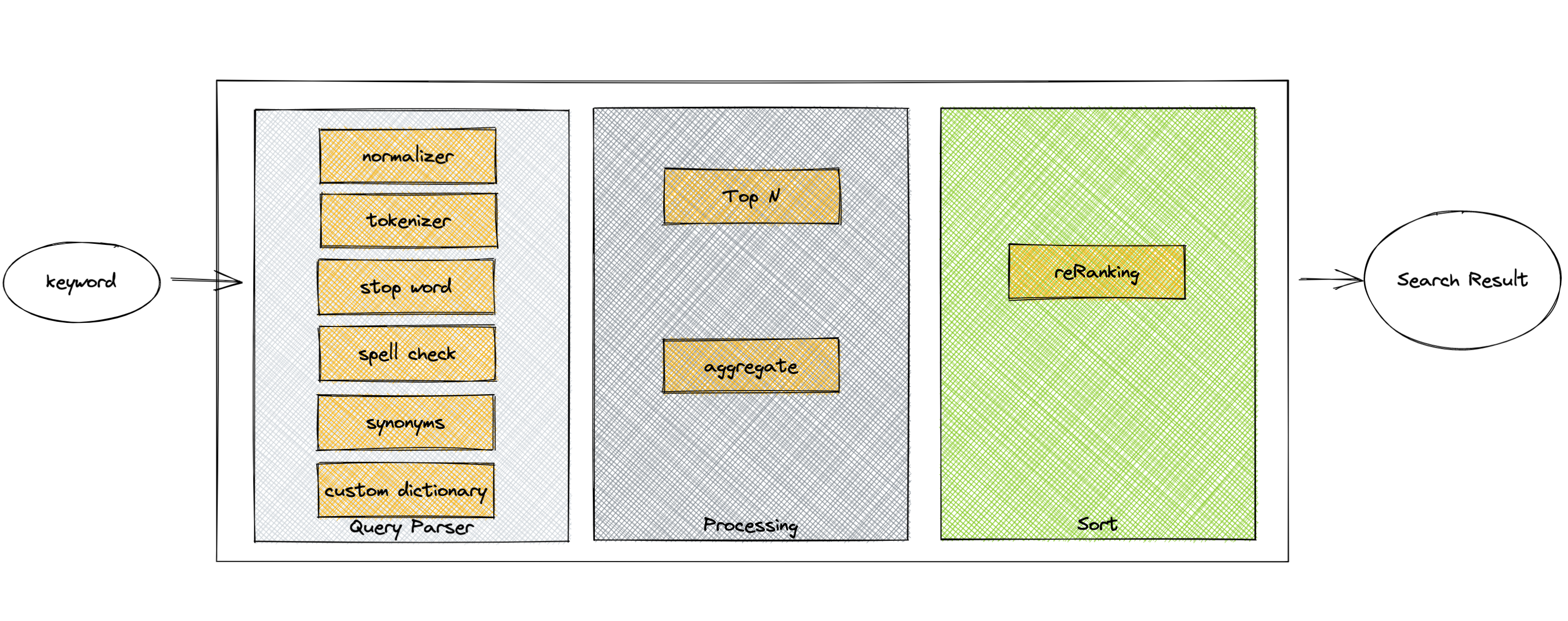
简单讲就是
- 用户输入查询 keyword
- 搜索查询服务处理特殊字符、规则过滤等,然后拼接搜索参数
- 传递到搜索引擎中
- 搜索引擎进行归一化、分词等一系列的处理,根据相关性选取 Top N 的索引(粗排)
- 针对索引进行聚合计算,如统计每个品牌的数量
- 对结果,根据业务规则进行重新排序(精排)
- 返回结果
查询前
- 我希望热词搜索能够展示每日 Top 10 的数据并且支持自定义
这个需求有很多的解决方案,
最简单的方式就是做一个管理端,根据运营要求自动切换;
还有一种是根据用户数据分析,选取每日中搜索量或者下单量 Top 10 作为热词展示
查询中
suggest
- 搜索建议词要求按“品牌+品类”、“品类+品类”的格式展示
在用户查询(正在输入过程中),我们会针对已输入的内容作为 keyword 然后去搜索引擎中查询,推测用户想要搜索的内容。
前端页面已经有了成熟的组件,详情 google ”auto complete“。搜索引擎一般都会针对建议词做专门的处理,并通过 API 的方式暴露。
词典
- 我希望在搜索“阿迪“时,能查询到阿迪达斯、阿迪王、三叶草等商品
在索引中如何只保存了”Adidas“这个品牌名时,”阿迪“ 就无法命中”Adidas“这些索引,那我们可以配置同义词词典,”阿迪达斯,Adidas“搜索引擎会自动加载这些词典作为映射,但这里有一个问题,就是只有在用户完全输入”阿迪达斯“,搜索才会识别它有同义词,当搜索”阿迪“时同样无法命中,此时的解决方案就是将中英文、常用名纳入到索引中,并设置模糊搜索。
精准搜索
- 当我使用具体款号搜索时,我希望只展示这一款的商品
精准搜索可直接在 keyword 两边加上双引号,但正常买东西显然不会这么干,这部分最好的解法其实是在页面上提供能让用户选择的地方,比如淘宝的搜索页。这就需要和产品进行 PK。

查询后
统计
- 针对于搜索结果,我要统计其中品牌品类以及门店的信息
这部分是在搜索结果中做一些数学运算,比如说求和、求平均值等,注意这部分是比较耗费性能的,在使用时需要谨慎,这个功能是为了方便顾客进行筛选,下图中就是统计出来的品牌、品类等属性。

排序
- 对于关系好的商户我想把他们的品牌优先展示,增加曝光率
对于粗排出来的商品,其默认顺序一般无法满足我们的要求,此时需要根据实际业务来定义。
这个需求做法也是需要一个管理后台,在里面配置需要优先展示的品牌或者供应商,然后在精排时,根据这些数据动态排序。
打散
- 我希望在搜索结果页中看到更多的品牌,而不是整页都是同一个品牌
搜索引擎中的索引来源是数据库,而数据库中保存的是有一定顺序的数据,比如同一个品牌的数据全都聚集在了一起,这样搜索出来的数据也会产生品牌堆积的现象,此时可以用打散函数。类似于编程语言中的 Random,根据某个维度进行打散,举例来说,现有搜索结果品牌堆叠现象明显,那可以采用 distinct(brand) 这样的方式打散。
排序
- 我希望能在搜索时能按上新时间、销量、价格进行排序
排序时搜索中必不可少的功能,升序、降序是基础内容,如果排序属性中有订单信息的话需要在 Dump 服务中进行处理,并设置成属性。
筛选
- 我希望能在搜索时进行价格区间、折扣区间、分类、门店进行过滤
筛选是在用户搜索后想进一步缩小范围,在技术层面直接使用搜索引擎的过滤功能,这在每个搜索引擎中都存在,也比较简单。
总结
本篇文章虽然讲的是技术,但并没有局限于某个搜索引擎,而是尽肯能的站在通用的角度上分析,本文也没有涉及到”高大上“的人工智能领域,所以只为中小企业的电商搜索工程师提供解决思路,搜索逻辑在头部电商网站中往往是超级复杂的,而本文介绍的内容,一个人完全能够掌控的住。