介绍
作为 Github 上的 热门项目 OpenIM,如何在云原生时代中创造出价值,这是非常重要的,OpenIM 是一个优质的小团队,我们在自动化中并没有特别深入的见解。
- 使用 GitHub Actions 进行持续集成和持续交付 (CI/CD):
- GitHub Actions 提供了一个平台,可以自动构建和测试 Go 语言项目。通过配置 GitHub Actions 工作流,你可以在代码更改时自动运行测试,确保代码的质量和功能 。
- KubeVela 项目实践:
- KubeVela 是一个 Go 语言的云原生和开源项目,它展示了如何在云原生环境中组织 CI/CD 过程,包括自动化测试。KubeVela 使用声明性工作流来协调 CI/CD 过程,你可以参考 KubeVela 的 GitHub 仓库来理解和应用这些实践3 4 [5](https://github.com/kubevela/workflow#:~:text=KubeVela Workflow is an open,engine in your own repository)。
- 云原生测试框架与工具:
- 在云原生开发中,合约测试(Contract Testing)是一种常见的测试实践,它确保服务间的通信符合预定义的 API 协议。例如,Cloud-Native Toolkit 中使用 Pact 进行合约测试。通过编写和集成测试,你可以验证服务间的通信是否符合预期6 。
- 代码覆盖率检查:
- 在进行自动化测试时,检查代码覆盖率是一个好的实践。许多测试框架内置了代码覆盖率检查功能,可以配置它们来报告测试的代码覆盖率。例如,使用 SonarQube 工具来读取和报告代码覆盖率信息6 。
- 利用开源工具和框架:
- 你可以利用开源工具和框架来进行测试,例如使用 Cypress 进行云原生应用的测试[7](https://dev.to/litmus-chaos/cloud-native-application-testing-automation-2bh5#:~:text=Cloud Native Application %26 Testing,Testing Using Cypress for)。还有其他的项目和资源,例如在 GitHub 上的 learning-cloud-native-go/myapp 仓库,提供了云原生 Go 项目的完成示例,你可以参考这些示例来理解和应用云原生测试实践[8](https://medium.com/learning-cloud-native-go/lets-get-it-started-dc4634ef03b#:~:text=The completed project can be,The completed API)。
- 自定义自动化测试流程:
- 通过结合 GitHub Actions 和开源工具,你可以定制项目的 CI/CD 流程,包括自动化测试和验证步骤9 。
自动化测试的价值量化
自动化很明显,是后期的手动成本很低,也就是说,随着时间的推移,自动化运行的次数增多,自动化的价值 ROI 变高
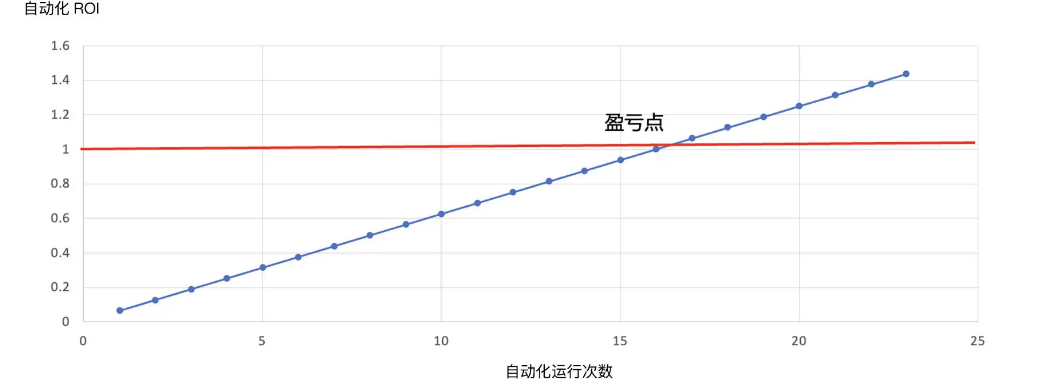
除了开发成本,还有维护成本。自动化测试开发出来后,还需要维护版本升级、诊断错误、优化结构等等的工作,这笔成本是需要持续投入的。
所以,得出公式如下:
产出 / 投入 = 0.5*N/(8+ 维护成本)
ROI 大于 1 就是赚了,小于 1 就是亏了。那么,给定一个测试案例,要不要对它做自动化,判断的依据是(自动化测试)预期 ROI 至少要大于 1。
自动化测试是一个长收益模式。在理想情况下,是一次性投入(投入为开发成本),之后每运行一次,就会增加一份产出。所以,时间越长,次数越多,收到的回报就会越大。
关于开发成本(包括开发成本 d 和维护成本 m),类似估算软件开发工作量,代码行法、功能点法,我们也可以引入到估算开发工作量里,比较好掌握。但维护成本就有点模糊了,这里包含了多种可变因素,是自动化测试项目风险的主要来源。
自动化测试是用来做回归测试的
回归测试(Regression Testing)是软件测试的一种类型,它的目的是在对软件进行修改(例如修复bug、添加新功能或代码重构)后验证现有功能是否仍然正常工作。它能帮助确保最近的代码更改没有破坏或影响已有的功能。
在GitHub项目中,回归测试和PR过程可以相互配合,例如:
- 在PR过程中,当开发人员提交一个新的PR时,可以配置GitHub Actions自动触发回归测试,执行测试套件以验证代码更改的影响。
- 回归测试的结果可以作为PR审查的一部分,帮助团队成员评估代码更改的质量和影响。如果回归测试失败,可能需要修复代码并再次运行测试,直到所有测试通过。
- 一旦所有的回归测试通过,并且代码得到团队成员的批准,PR就可以合并到主分支。
自动化测试的开始
实践中,冒烟测试是你自动化的开始
冒烟测试通常是在软件构建或发布到测试环境后的第一轮测试。它主要是为了确保软件的基本功能正常运行,而不是在细节上进行深入的测试。冒烟测试的主要目标是:
- 识别是否存在阻止软件基本功能运行的严重问题。
- 确保软件在基本层面上是“健康”的,可以进一步测试。
冒烟测试通常覆盖:
- 核心功能的基本测试,例如软件是否能正常启动和运行。
- 主要的接口和交互是否能正常工作。
- 任何其他被认为是“破坏性”的基本问题。
在实践中,可以设定目标,冒烟测试 100% 自动化。这时,自动化测试就可以和手工测试配合,形成一个新版本发布 + 冒烟测试的简单流水线。
最优自动化实施截面
制定策略,能够让这个自动化测试设计获得尽可能大的 ROI。
我们知道不同的阶段,测试的时间以及测试的频率是不同的。
测试 ROI 金字塔
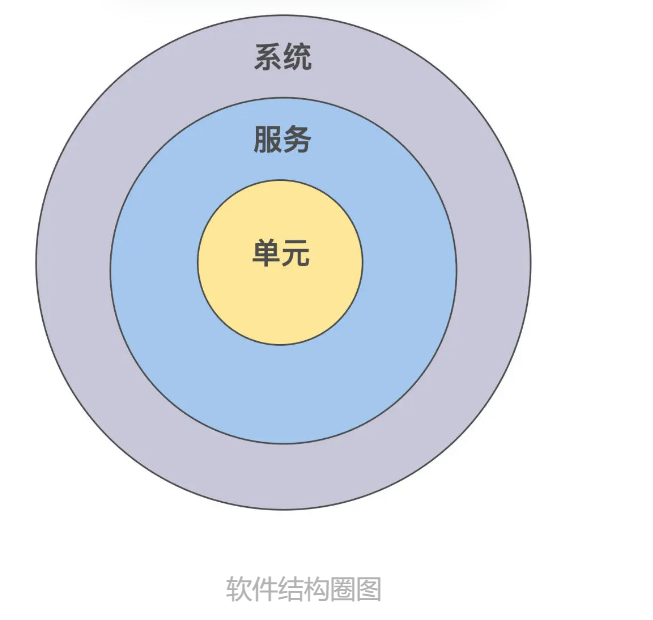
在测试设计领域,经常提到的方法是分层。具体就是给定一个系统,结构上划分三个层级,单元在最小圈;服务包含多个单元,在中圈;而系统又包含多个服务,是外部的最大圈。结构图如下:
在实践中,这三种测试该怎么组合安排呢?迈克·科恩在 2009 年他的新书《敏捷成功之道》中首次提出了测试金字塔模型。单元测试自动化在金字塔底部,接口测试自动化在中部,而 UI 测试自动化在金字塔顶部。
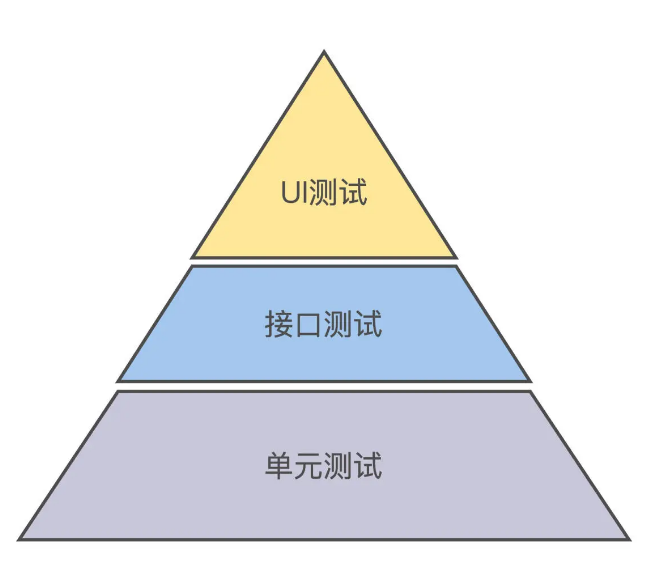
为什么是金字塔?要是不去理解规律背后这个“为什么”,你就用不好这个规律。上一讲我们知道了“ROI 其实是自动化测试的隐式命脉”,现在我们就利用 ROI 思维,分析一下测试金字塔规律。

下面,我们分别看看每层的 ROI。单元测试可以在开发人员每次 code commit 触发运行,回归频率高;接口测试在每轮集成测试运行,回归频率中;UI 自动化测试在用户验收测试,回归频率低。
按照 ROI 模型,我们可以得出 3 种类型自动化测试的 ROI 排序,如下表:
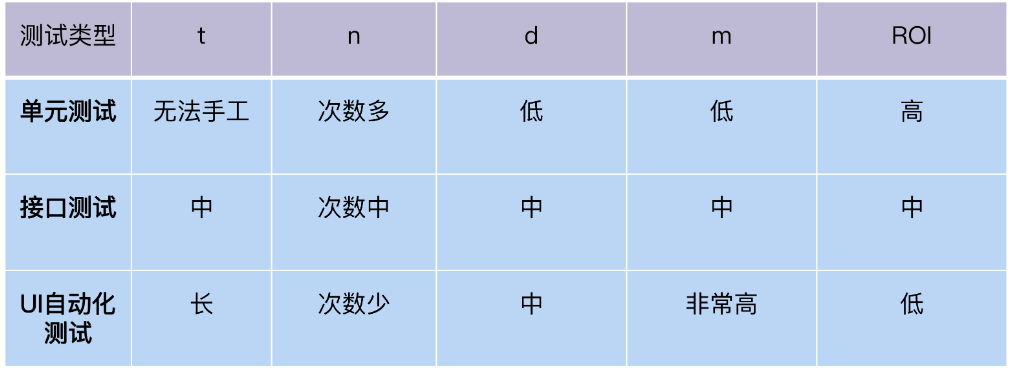
对照测试金字塔不难发现,实际上三类自动化测试的 ROI 是自底向上由高到低的。
那么,我们应该优先投入精力做 ROI 最高的单元测试,再做 ROI 中的接口测试,最后完成 UI 测试。
分层测试为啥会“内卷”
分层测试中,我们需要写的最多的是单元测试:
package main
import (
"testing"
)
func TestValidateCredentials(t *testing.T) {
valid := validateCredentials("username", "password")
if !valid {
t.Errorf("expected valid credentials")
}
}
接口测试:
接口测试主要针对应用程序的API接口。我们可能会有一个API端点来处理登录请求。
package tests
import (
"net/http"
"testing"
)
func TestLoginEndpoint(t *testing.T) {
resp, err := http.Post("/login", "application/json", strings.NewReader(`{"username":"username","password":"password"}`))
if err != nil {
t.Fatalf("could not send request: %v", err)
}
if resp.StatusCode != http.StatusOK {
t.Errorf("unexpected status: got (%v) want (%v)", resp.StatusCode, http.StatusOK)
}
}
端到端测试 (E2E Testing):
端到端测试验证整个系统的工作流程。我们可以使用工具如Selenium来模拟用户的登录过程。
// 使用 Selenium 或类似工具进行端到端测试
Selenium 是一个强大的工具,用于控制Web浏览器通过程序进行自动化测试。它支持多种浏览器,包括Chrome、Firefox、IE和Safari。通过Selenium,测试人员可以编写脚本来模拟用户交互,验证应用程序的行为,并确保应用程序按预期工作。以下是Selenium的一些主要特点和组件
UI测试 (UI Testing)
UI测试主要针对应用程序的用户界面。我们同样可以使用Selenium或其他工具来模拟用户交互,并验证登录页面的UI元素。
// 使用 Selenium 或类似工具进行UI测试
可以看到,一个请求,从浏览器页面发起,进入 API 网关,再传递到服务里的 Login 函数,经过了 UI 测试、API 测试和单元测试三个测试截面。
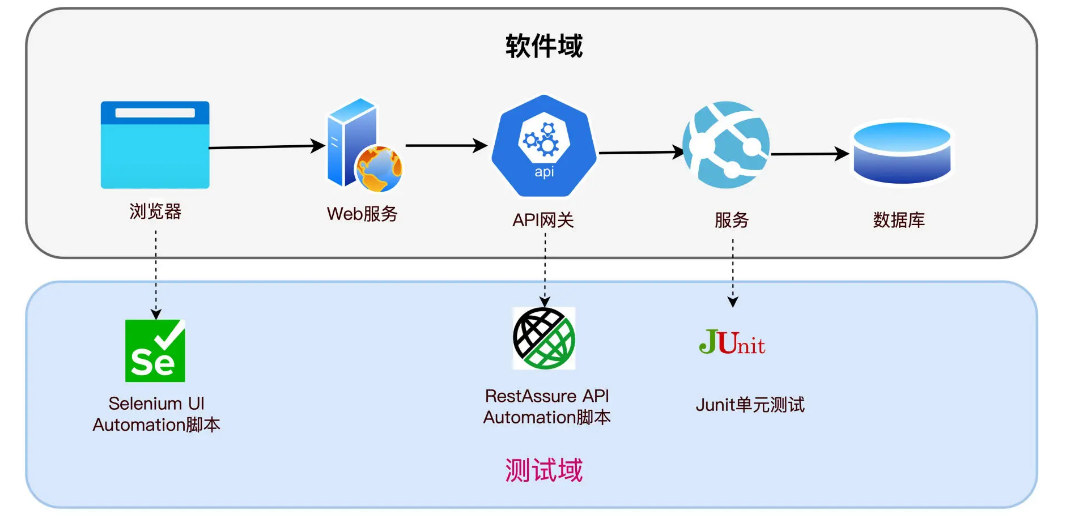
三个测试截面测的是一个请求在不同层面上的形态,那么每一个截面都可以测试全部的案例,也可以测试部分的案例。就像 3 个人负责 1 个项目一样,如果没有经过事先的协调和安排,3 个人可能做了重复的事情,造成浪费,也可能存在一件事 3 个人都没干,形成测试盲区。
需求 / 策略矩阵
咱们先看看测试需求是什么,用 FURPS 模型来理一下需求。FURPS 是用 5 个维度来描述一个软件的功能需求,FURPS 这个单词对应着每个需求的英文首字母:
- F=Function 功能
- U=Usability 易用性
- R=Reliability 可靠性
- P=Performance 性能
- S=Supportability 可支持性
选择工具框架
工具选型很重要,在大型企业中,无论你是作为评审者,还是方案建议人。不过常常出现的场景就是,方案建议人讲了一通新工具 A 如何优秀强大,从问题分析到方案解决一应俱全。但参会专家并不是全都熟悉这个新工具,就会问出一堆类似“为什么你不用工具 B”的问题。

通过这个模型,我们得到一个重要结论:一个自动化测试案例的开发工作量,在给定条件下,什么经验的工程师用什么工具,需要多长时间完成,这是可以估算的定值。但维护工作量包含了多种可变因素,是自动化测试项目的风险所在。
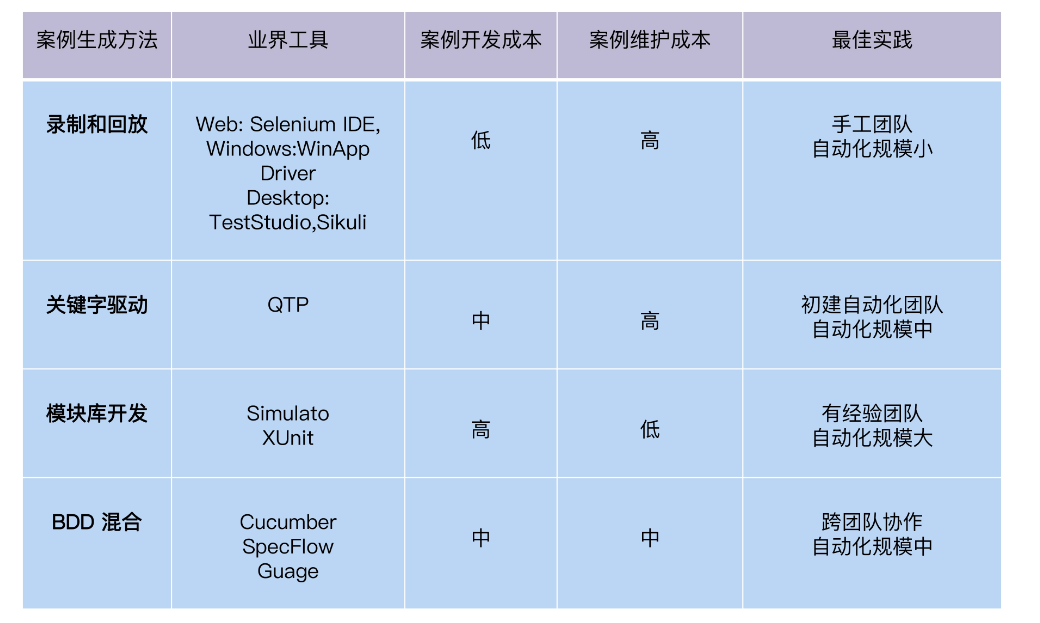
录制和回放
第一代的自动化测试工具大多基于录制回放,像最早的 WinRunner 就是录制桌面 UI 应用的。目前代表工具就是 Selenium IDE。
要生成测试代码很简单,开启浏览器 Selenium 的插件,打开测试的网页,比如 http://www.youtube.com 点击视频
通过录制产生自动化脚本的这种方法,优点是速度快、零编码,对测试人员技术要求低。缺点是规模一旦扩大,维护工作量几乎无法承受,比如和 CICD 集成、自定制报告、多环境支持等等。
方法二:关键字驱动
不过,录制回放产生的脚本,还是面向过程的一个个函数,还需要测试人员有一定代码基础,才能扩展和维护这些函数。
那么,有没有办法,让没有代码经验的人也能编辑、维护脚本呢?关键字驱动方式应运而生了,它增加了页面控件对象的概念,调用对象的方法就是操作对象运行,在这种机制下,对象、对象的行为、输入的数据和描述信息,这些内容都能用一个表格的形式呈现。业务人员只需要编辑表格,就能修改运行逻辑了,这就叫做关键字驱动。
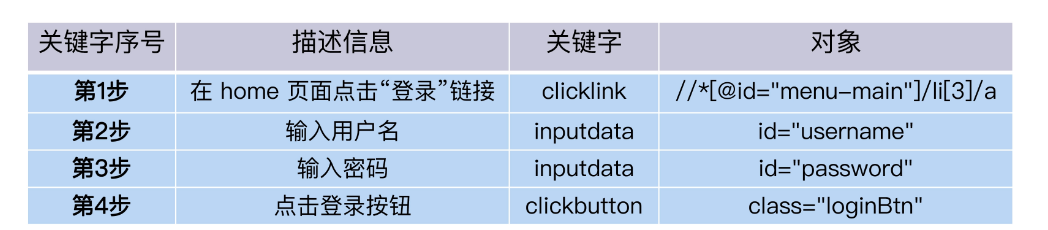
相比录制回放,关键字驱动框架的优势在于降低了测试开发人员的技术要求。而且测试开发人员对代码还有了更多的逻辑控制能力,比如增加循环结构、wait time、log 输出,只要框架提供足够丰富的关键字就行。
但你也不难看出,编辑表格的人和维护关键字仓库的人,并不是同一拨人。前者是对业务了解的测试人员,后者是技术能力强的开发人员,这样开发维护起来会增加难度。
方法三:模块库开发
随着软件技术的发展,自动化测试人员的技术水平也在提高,要解决的问题也更加复杂。比如自动化测试的代码怎么能够有效地复用,有没有好的扩展能力等等。这个扩展能力是二维的,分为水平功能扩展和垂直层级扩展。
水平功能扩展指的是测试功能增多,自动化测试代码就借鉴了软件的模块设计思维,一个应用的测试场景可以切分成多个功能模块。比如订餐的流程可以分成登录模块、下单模块、快递模块,模块之间通过调用关系连接起来,组成测试场景。

而在技术层面上,又可以垂直切分出功能案例库和通用库。比如页面的组件可以形成复用库、page 对象、button 对象、link 对象等等,把和开发技术耦合的技术层封装在复用库里,而和测试相关的业务功能实现在功能案例库里。
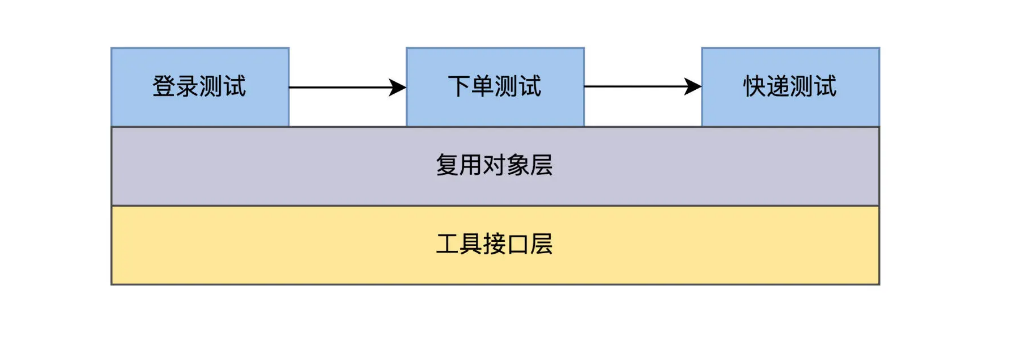
这样的设计,遵循了高内聚低耦合的软件设计思想,未来自动化测试规模扩展时也很方便。比方说增加一个支付功能,就可以把支付页面的对象写到复用库里,新创建一个支付测试案例,前面和下单模块衔接,后面和快递模块对接,就能跑起来了。
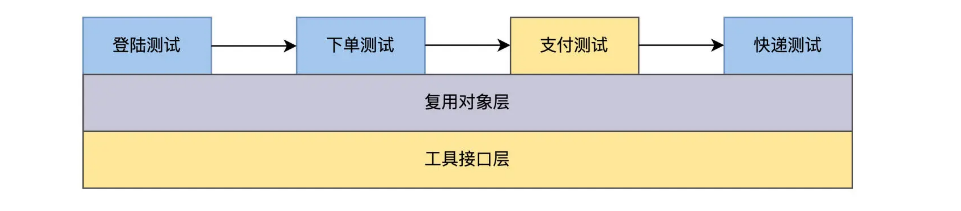
方法四:BDD 混合框架
还有一种方法是 BDD 混合框架。BDD 全称是 Behavior Drive Development,行为驱动开发,它通过 Gherkin 语法定义测试场景。
Gherkin 语法包含一套类自然语言的关键字:when、given、then,given 描述条件,when 描述行为,then 描述结果。这样一个场景的 3 要素:上下文、动作和结果就说明白了。
所以,Gherkin 语法描述出来的测试场景,能够同时被非技术和技术人员理解。客户、需求人员、开发人员和测试人员从 BDD 案例各取所需,需求人员得到用户手册,开发人员得到 Use Case,测试人员得到测试案例。这些都有 BDD 框架支持生成代码,比如 Cucumber。
方法五:更高 ROI 的探索,自动化前沿技术
最后,我要说一下目前比较火,听起来也很酷的自动化前沿技术。
AI 测试曾被寄予厚望,我们期待由它发展出一套自动化测试全栈解决方案,可以自动生成测试案例和代码,而且维护工作量为零。不能说这些全都是镜花水月,我相信目前 AI 只在一小部分测试领域里落地,比如图像识别的 Applitools,可以用作图片验证;游戏领域里的监督学习,用来行为克隆等等。
我也曾看过一些 AI 根据规则自动生成测试案例的演示,但演示只是演示,它演示的方案需要的很多条件,现实还不具备,比如基于非常理想的数据模型等等。所以,我认为 AI“落地”的定义是,它的形式是产品,而不是个人业余的项目或者一段开源代码。
相比 AI 测试,我更看好另外一种自动化生成测试的思路,就是基于规则化或可以模式化的业务场景,把案例的生成和代码生成一并自动化,形成一种可以量化的案例发现方案。我会在第 5 讲带你了解这个思路如何实现。
记住,测试工作是要能证明软件功能的成败,其方法论基石是确定论,而不是未知论。说得通俗一点,测试是在编网,虽然网会漏鱼,但我很确信只要投入人手和时间,就能把网编到什么程度,网住什么鱼。 而不是今天我捉到一条鱼,明天不知道鱼在哪里。这是我不认为 AI 能完全替代手工测试工作的原因。
脚本复用:什么样的代码才值得写
我们看一下下一段用 go 语言写的代码:
package main
import (
"github.com/tebeka/selenium"
)
func login() {
var webDriver selenium.WebDriver
var err error
caps := selenium.Capabilities{"browserName": "chrome"}
if webDriver, err = selenium.NewRemote(caps, ""); err != nil {
panic(err)
}
defer webDriver.Quit()
err = webDriver.MaximizeWindow("")
if err != nil {
panic(err)
}
err = webDriver.Get("https://www.example.com/users/sign_in")
if err != nil {
panic(err)
}
username, err := webDriver.FindElement(selenium.ByID, "user_name")
if err != nil {
panic(err)
}
password, err := webDriver.FindElement(selenium.ByID, "user_password")
if err != nil {
panic(err)
}
login, err := webDriver.FindElement(selenium.ByXPATH, `//button[normalize-space(text())="登录"]`)
if err != nil {
panic(err)
}
err = username.SendKeys("openim@example.com")
if err != nil {
panic(err)
}
err = password.SendKeys("123456")
if err != nil {
panic(err)
}
err = login.Click()
if err != nil {
panic(err)
}
}
func main() {
login()
}
在这段Go代码中:
- 我们首先导入了
github.com/tebeka/selenium包,它是一个提供Selenium WebDriver绑定的Go库。 - 在
login函数中,我们创建了一个新的WebDriver实例,并使用ChromeDriver来启动一个新的浏览器会话。 - 然后,我们最大化了浏览器窗口,打开了登录页面,并找到了用户名、密码和登录按钮的元素。
- 最后,我们输入了用户名和密码,并点击了登录按钮。
提高复用率:一份代码,多浏览器运行
可以看到,脚本运行的测试案例只在 chrome 上,但作为一个 web 应用,一般是要支持市面上主流的浏览器,看一下 阿里云网站 支持 12 种浏览器,列表如下:
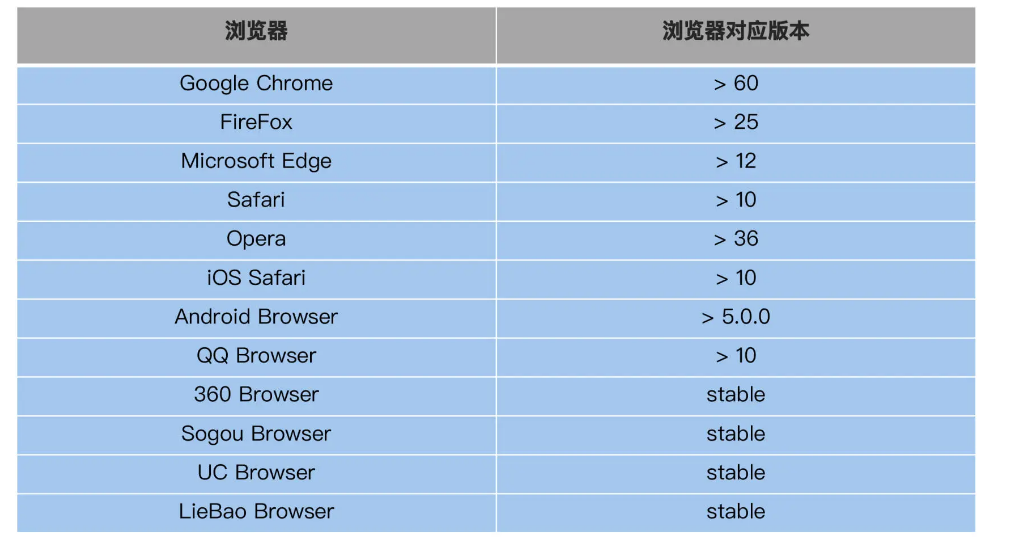
那么,有没有办法让我们的脚本能够一下子测试 12 种浏览器呢?此时我们需要修改脚本,支持调用多个浏览器 driver:
package main
import (
"fmt"
"github.com/tebeka/selenium"
"github.com/tebeka/selenium/chrome"
)
func login(driver selenium.WebDriver) {
err := driver.MaximizeWindow("")
if err != nil {
panic(err)
}
err = driver.Get("https://www.example.com/users/sign_in")
if err != nil {
panic(err)
}
username, err := driver.FindElement(selenium.ByID, "user_name")
if err != nil {
panic(err)
}
password, err := driver.FindElement(selenium.ByID, "user_password")
if err != nil {
panic(err)
}
login, err := driver.FindElement(selenium.ByXPATH, `//button[normalize-space(text())="登录"]`)
if err != nil {
panic(err)
}
err = username.SendKeys("openim@example.com")
if err != nil {
panic(err)
}
err = password.SendKeys("123456")
if err != nil {
panic(err)
}
err = login.Click()
if err != nil {
panic(err)
}
}
func main() {
drivers := []string{"chrome", "firefox"} // 此处列举了两种浏览器驱动,可以根据实际需求添加更多驱动
for _, driverName := range drivers {
var webDriver selenium.WebDriver
var err error
switch driverName {
case "chrome":
caps := selenium.Capabilities{"browserName": "chrome"}
webDriver, err = selenium.NewRemote(caps, "")
if err != nil {
panic(err)
}
case "firefox":
caps := selenium.Capabilities{"browserName": "firefox"}
webDriver, err = selenium.NewRemote(caps, "")
if err != nil {
panic(err)
}
default:
fmt.Printf("Unsupported driver: %s\n", driverName)
continue
}
defer webDriver.Quit()
login(webDriver)
}
}
在这段Go代码中:
- 我们定义了一个
login函数,它接受一个selenium.WebDriver实例作为参数。这个login函数执行了与Java代码中相同的登录步骤。 - 在
main函数中,我们创建了一个drivers数组,包含了我们想要测试的浏览器驱动名。我们遍历这个数组,并为每个驱动名创建一个新的WebDriver实例。 - 对于每个
WebDriver实例,我们调用login函数来执行登录测试。
driver 的数目有多少个,就运行多少次,每次运行从 iteration 数组里取得 driver 的名字,交给脚本去启动相应的浏览器。
提高复用率:一份代码,多数据运行
刚才已经迈出了第一步,不错,我们再继续看脚本,还有没有可以改进的地方。现在,我们的脚本只能测试一组用户数据,用户名 openim,密码是 123456。在测试方法论中,一个测试案例应该有多组测试数据,那合法的用户名的数据格式不止这么多,按照字符类型划分等价类,至少有 5 组:
- ASCII 字符
- 数字
- 特殊字符
- 拉丁文字符
- 中文字符
密码一般是数字,ASCII 字符加特殊字符 3 种。我们至少可以开发出 5*3=15 种合法的用户名密码组合,作为测试用例。
package main
import (
"github.com/tebeka/selenium"
)
type UserPassword struct {
username string
password string
}
func login(driver selenium.WebDriver, credentials UserPassword) {
err := driver.MaximizeWindow("")
if err != nil {
panic(err)
}
err = driver.Get("https://www.example.com/users/sign_in")
if err != nil {
panic(err)
}
usernameField, err := driver.FindElement(selenium.ByID, "user_name")
if err != nil {
panic(err)
}
passwordField, err := driver.FindElement(selenium.ByID, "user_password")
if err != nil {
panic(err)
}
loginButton, err := driver.FindElement(selenium.ByXPATH, `//button[normalize-space(text())="登录"]`)
if err != nil {
panic(err)
}
err = usernameField.SendKeys(credentials.username)
if err != nil {
panic(err)
}
err = passwordField.SendKeys(credentials.password)
if err != nil {
panic(err)
}
err = loginButton.Click()
if err != nil {
panic(err)
}
}
func main() {
drivers := []string{"chrome", "firefox"}
userPasswords := []UserPassword{
{"xxxx", "123456"},
{"测试用户", "Welcome1"},
// ... other user-password combinations
}
for _, driverName := range drivers {
var webDriver selenium.WebDriver
var err error
caps := selenium.Capabilities{"browserName": driverName}
webDriver, err = selenium.NewRemote(caps, "")
if err != nil {
panic(err)
}
defer webDriver.Quit()
for _, credentials := range userPasswords {
login(webDriver, credentials)
}
}
}
在这段Go代码中:
- 我们定义了一个
UserPassword结构体来保存用户名和密码的组合。 login函数现在接受一个selenium.WebDriver实例和一个UserPassword实例作为参数。- 在
main函数中,我们创建了两个数组,一个用于保存要测试的浏览器驱动名,另一个用于保存要测试的用户名和密码的组合。 - 我们遍历每个浏览器驱动名,为每个驱动名创建一个新的
WebDriver实例。然后,我们遍历每个用户名和密码的组合,并对每个组合调用login函数来执行登录测试。
提高复用率:一份代码,多环境运行
现在我们已经摸着道了,提高 ROI,那就是让一份自动化测试程序,尽可能多复用在不同的测试场景中。这些测试场景本来就是有效的测试需求,转换成自动化也是一劳多得。
还有没有其他场景呢?当然有,举个例子,在我们的产品发布 pipeline 里,贯穿了从开发环境、测试环境、准生产环境到生产环境,由低向高的交付过程。
那你的测试脚本需要兼容每一个环境,在所有需要运行它的环境里都可以直接跑,不需要做任何修改。一份脚本,运行在 dev,test,stage,productin 4 种环境下,我们的 n3=4, n=n1+n2+n3=15+12+4=31 次
如何做到同一个测试程序跑多个环境,最好的方式就是提取出配置文件:
我们的自动化测试也可以实现类似的机制。聪明的你,可以考虑自开发一个测试配置文件加载模块,代码不需要多,但会直接增加 ROI。
另外,如果你的产品支持多国语言,那么一份代码跑多国语言版本,也是一个会显著增加自动化测试 ROI 的好主意。
像上面的代码,当前只支持中文页面。假设我们的产品要求支持 9 种语言,那可以让页面控件加载不同语言的 label text。
package main
import (
"github.com/tebeka/selenium"
)
type Credentials struct {
username string
password string
}
type Profile struct {
url string
}
type Label struct {
loginText string
}
func login(driver selenium.WebDriver, credentials Credentials, profile Profile, language string, label Label) {
err := driver.MaximizeWindow("")
if err != nil {
panic(err)
}
err = driver.Get(profile.url)
if err != nil {
panic(err)
}
usernameField, err := driver.FindElement(selenium.ByID, "user_name")
if err != nil {
panic(err)
}
passwordField, err := driver.FindElement(selenium.ByID, "user_password")
if err != nil {
panic(err)
}
loginButton, err := driver.FindElement(selenium.ByXPATH, `//button[normalize-space(text())="`+label.loginText+`"]`)
if err != nil {
panic(err)
}
err = usernameField.SendKeys(credentials.username)
if err != nil {
panic(err)
}
err = passwordField.SendKeys(credentials.password)
if err != nil {
panic(err)
}
err = loginButton.Click()
if err != nil {
panic(err)
}
}
func main() {
drivers := []string{"chrome", "firefox"}
credentialsList := []Credentials{
{"xxxx", "123456"},
{"测试用户", "Welcome1"},
// ... other user-password combinations
}
profiles := []Profile{
{url: "auto-dev.yml"},
{url: "auto-test.yml"},
{url: "auto-prod.yml"},
// ... other profiles
}
languages := []string{"en", "zh_CN", "zh_TW", "FR"}
labels := []Label{
{loginText: "登录"},
// ... other labels
}
for _, driverName := range drivers {
var webDriver selenium.WebDriver
var err error
caps := selenium.Capabilities{"browserName": driverName}
webDriver, err = selenium.NewRemote(caps, "")
if err != nil {
panic(err)
}
defer webDriver.Quit()
for _, credentials := range credentialsList {
for _, profile := range profiles {
for _, language := range languages {
for _, label := range labels {
login(webDriver, credentials, profile, language, label)
}
}
}
}
}
}
在这段Go代码中:
- 定义了几个结构体和类型来表示测试方法的参数。
login函数现在接受五个参数,每个参数对应一个@Iteration注解。- 在
main函数中,创建了几个数组来保存每个@Iteration注解的值。使用嵌套循环来遍历这些数组,并为每个参数组合调用login函数。 - 在
login函数中,使用参数值执行登录测试。
现在一份脚本经过了多浏览器、多数据、多环境和多语言 4 轮打磨,运行的次数 n=n1+n2+n3+n4=12+15+4+9=40 次。如果各个场景有关联关系,比如页面的语言和测试数据有耦合,英文页面的 encoding 和数据的 charset 有关联,那么两个场景的次数就是完全组合,采用乘法,15*9=135 次。
而且,从脚本的变化可以看到,脚本第一版本里的 hard code 也一个个被消除了,取而代之的是数据驱动。消除 hard code 是提升 ROI 的结果。
还有哪些工作值得做?
维护工作量的不确定性是自动化测试的一个重要风险,所以我们有必要看一下维护的工作量都花在哪里了。
- 被测截面发生变化带来的维护工作量。比如 UI 自动化测试的产品页面发生了变化,API 自动化测试的接口做了重构。
- 诊断自动化测试的工作量,如果把自动化测试结果分为真阳,假阳,真阴,假阴。那假阳和假阴都是需要诊断的。
Auto Gen Auto:所有测试工作即代码
我们前面用了 4 讲篇幅,讨论 ROI 模型和由此衍生出来的一套实践原则,从分层测试、选型思路和具体代码多个角度探索提升 ROI 的方法。
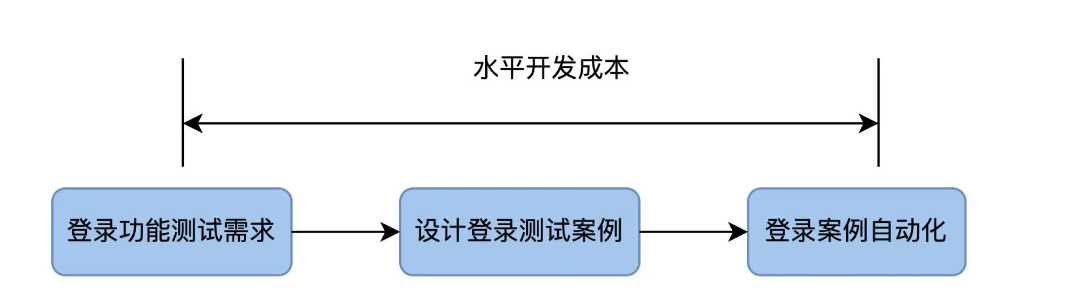
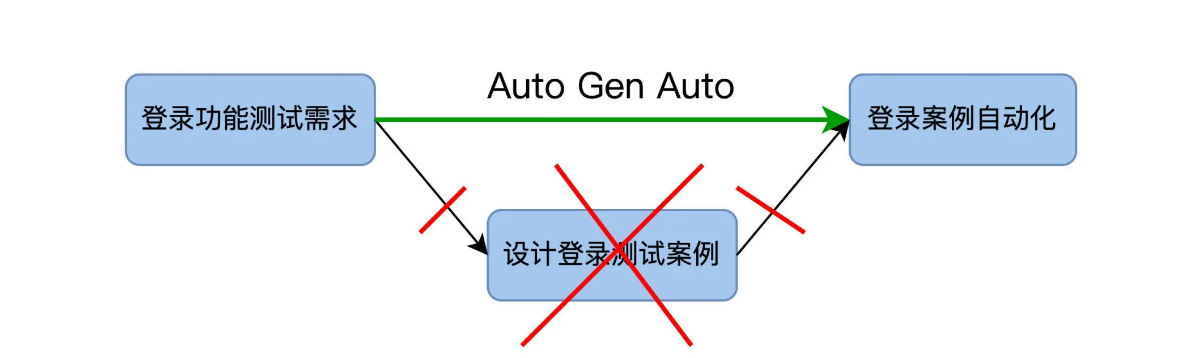
这些方法还都是基于常规的自动化测试开发流程,先有测试需求,再设计测试案例,然后做自动化。以登录测试为例:

自动化测试的开发成本,就是把测试需求转变成自动化测试代码这个过程花费的时间。在我们的图里,它是从左向右,所以我管它叫做水平开发成本。
当登录功能测试需求发生变化时,就会重新走一遍这个流程,出现了多个版本的测试需求,也会带来多个版本的自动化测试案例。从下图可见,这个版本是自上向下增加,所以我管它叫做垂直维护成本。
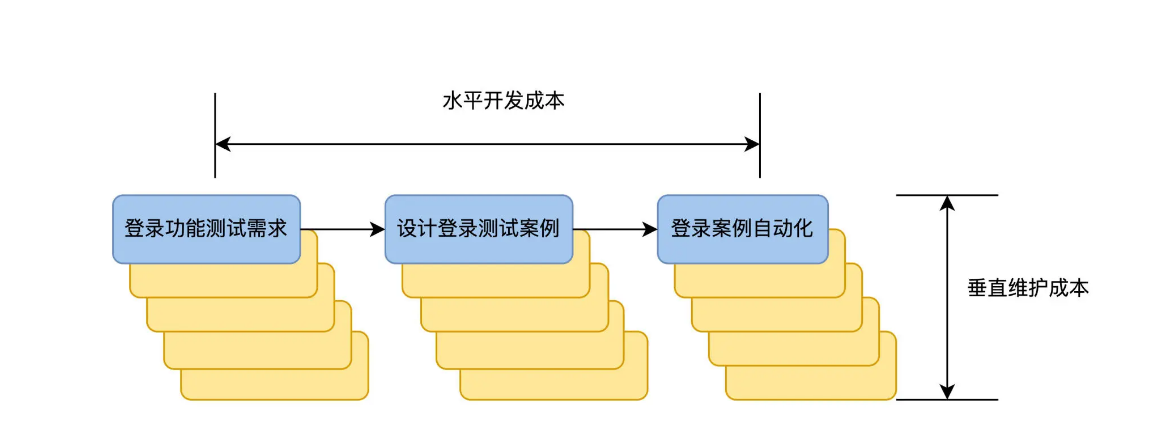
我们现在可以直观地看到开发成本和维护成本了。好,问题来了,有没有办法从流程上动手术,来降低这两个成本呢?
这就是我们今天要讲的 Automation Generate Automation,也叫自动化产生自动化测试代码,为了方便起见,下面的篇幅用缩写 Auto Gen Auto 来指代。
Auto Gen Auto 技术
常规的自动化测试,是指用代码实现设计好的 TestCase,而 Auto Gen Auto 的目的是让 Test Case 生成也自动化,如下图所示。
因为从测试需求到自动化测试案例是完全自动化的,每次需求改变的时候,只需运行一次 Auto Gen Auto 即可生成新的自动化案例,垂直维护成本为零。所以 Auto Gen Auto 技术如果能落地,ROI 就会大大提高。
从何处下手
业界熟知的测试方法是黑盒测试和白盒测试。白盒测试从测试案例设计开始,需要我们先了解代码逻辑结果,一个函数里有几个判断分支,处理那些数据。基于这些了解,再设计案例验证函数输出和达成代码覆盖率。
在白盒测试里,Auto Gen Auto 不是啥稀奇事,XUnit 框架都提供了不少开发 IDE 的 plugin,可以扫描一个 class 的函数,直接产生 test 方法。开发人员只需补充少量代码,test 方法就可以运转起来了。
与之对应的是黑盒测试,测试案例设计不基于产品代码,而是用户规格说明。比如,用户在订餐系统上完成一个订单,用户该怎么操作,下单成功后应该收到物流单号等等,设计这些测试案例的目的是验证业务能够完成,不需要去看代码。
今天,我们要关注的是在黑盒测试领域的 Auto Gen Auto,这个更有挑战性,也更有探索价值。因为,作为测试人员花了大量时间来设计黑盒测试案例,而且还要手工维护这些测试案例的变化,这个过程要是都能自动化了,就会省去很大的重复又枯燥的工作量。
如何实现
怎么做到 Auto Gen Auto 呢?用代码生成代码,前提是测试需求得有一定的规则或模式,然后代码才能解析规则,根据规则生成最终的测试代码。
这个实现思路,在开发中是很常用的,比如 Maven Archetype 使用模版自动生成项目代码,Soap 使用 WSDL 来生成调用桩等等,原理图如下。
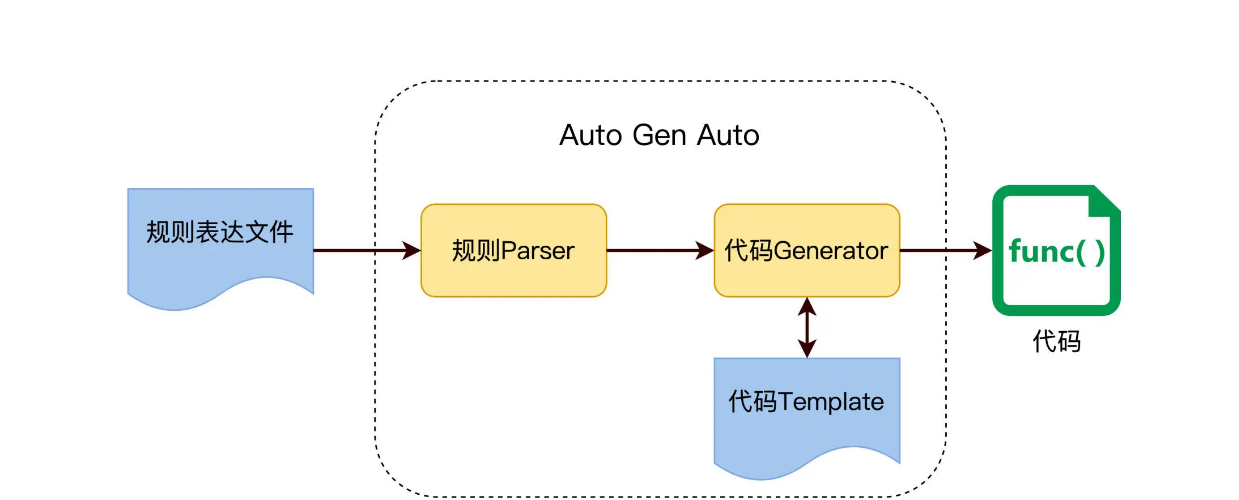
所以,要做 Auto Gen Auto,我们的目标是先要找出测试需求里的这些规则,并把它们表达出来,放在一个规则文件里。我们看看下面的例子。
测试等价类的规则
远在天边,近在眼前,我们在测试案例设计中经常用到的等价类和边价值方法,就可以作为 Auto Gen Auto 的规则。
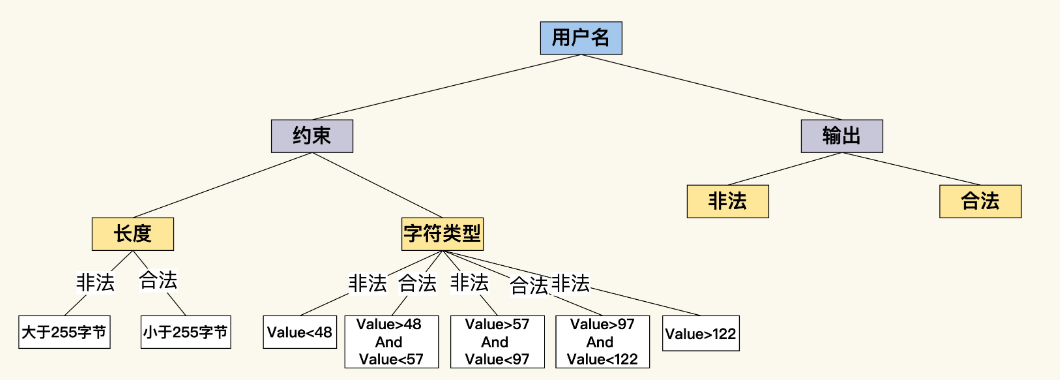
等价类是指某个输入域的子集合,在同一个子集合里的所有元素对于测试的效果都是等价的。
我们要测试一个订餐系统的用户名,首先要了解用户名上的约束。从长度上来看,假设用户名最大长度是 255 个字节,根据这个约束,至少能产生 2 个测试等价类:有效等价类是小于 255 字节的用户名,无效等价类是大于 255 字节的用户名。测试用户注册功能时,就可以用到这 2 个等价类了。
用同样的思路看用户名的另外一个约束,那就是字符类型的限制,假设用户名只能由英文字母和数字组成,根据这个约束,又可以产生多个等价类,中文字符、ASCII 字符、数字、High ASCII 等等。
如果能让测试案例和等价类自动对应,然后依据规则动态产生测试案例,这些问题就会迎刃而解。不过,我们得先把这些约束规则外化表达出来,在这里,我用一个 user-rule.yaml 文件来表达这些规则。
name: user name rules
appliedTestCase: register, login
rules:
lengthRule:
express: <=255 chars
characterRule:
express: value>=97 and value<=122
express: value>=48 and value<=57
然后,我们写一段代码,从这个 YAML 文件中直接把规则加载进来,在内存中形成一个分类树。
业务的逻辑规则
用等价类的规则表达小试牛刀后,我们尝到了甜头。看来,只要能把规则表达出来,生成测试案例这个工作就可以交给代码去做。我们再找一个更加实用的场景,来看看怎么落地。
在做 API 测试的时候,restAPI 的接口一般是通过 Open API 规范来描述。在设计阶段,开发先定义要实现的 API 接口,Client 要发送什么样的 Request,Server 要返回什么样的 Response。
比如下面的 user-restapi.yaml 文件,就是遵循 Open API 规范,定义了一个根据 name 查询 User 的 RestAPI。
/api/users:
get:
description: 通过name查询用户.
parameters:
- username
type: string
description: 用户name
responses:
'200':
description: 成功返回符合查询条件的用户列表.
schema:
type: array
items:
$ref: '#/definitions/User'
这个接口很简单,但它也声明了一个简单的契约,Client 要想查询 User,它需要向 server 发送一个 http get 请求,发送的 url 格式如下:
http://{host}:{port}/api/users?username=openim
而 server 如果查询到了 User,它应该返回这样一个 http status code 为 200 的 response,内容如下:
{
"items": [
{
"ID": "123456",
"name": "liusheng",
"age": 18
}
]
}
YAML 文件里定义接口所用到的关键字,像 get、description、parameters 等等,它们都是 Open API 里定义好的,含义也是明确的,那么 YAML 表达出来的规则内容也是可以解析出来的。因此,我们同样可以根据规则内容,直接生成测试代码。
实际上,业界已经有了现成的工具,对于 Go 语言,有几个类似于 OpenAPI Generator 的工具,可以用于从 OpenAPI 规范生成客户端库、服务器存根和其他资源。以下是其中一些工具:
- GoSwagger:
- openapi-generator-go:
- 这是专为 Go 语言设计的官方 OpenAPI Generator 的变体。它为许多字段提供了 getter,使得定义和处理模型的接口更加容易。此生成器还对枚举(包括使验证枚举更容易的实用方法)、数组和
allOf有更好的支持。
- 这是专为 Go 语言设计的官方 OpenAPI Generator 的变体。它为许多字段提供了 getter,使得定义和处理模型的接口更加容易。此生成器还对枚举(包括使验证枚举更容易的实用方法)、数组和
- oapi-codegen:
- oapi-codegen 是一个从 OpenAPI 规范生成 Go 应用程序服务器代码的工具。此工具提供了生成类型和服务器代码的命令,使得基于给定的 OpenAPI 规范轻松构建 Go 服务器变得更容易。
- APIMatic 为 Go SDKs 提供的代码生成器:
- APIMatic 提供了一个为 Go SDKs 的代码生成器,该生成器从 OpenAPI 定义生成强类型的 SDK 以及完整的 API 引用。如果你想为你的 REST API 创建一个 SDK,这个工具会特别有用。
另外,有了一份定义完备详细的接口设计文档,Auto Gen Auto 解决方案才可能实现。它不仅能够生成 API test,还可以生成 performance test 等等。
左移&右移:测试如何在Dev和Ops领域大展身手?
所以,你要找到更多的土壤让自动化测试落地生长。如果你想在工作中推广自动化测试,哪些落地场景更容易出业绩呢?除了之前说过的回归测试领域,我们不妨把眼光从测试工作放宽到更多的领域,Dev 和 Ops 领域,自动化测试在这些领域里一样可以发挥价值,我叫它自动化测试左移和自动化测试右移。
自动化测试左移
如果把软件的生命周期的一个个阶段,软件需求分析、软件设计、软件开发、单元测试、集成测试、系统测试,从左向右排列,开发活动在左侧,测试在后面也就是右侧。如下图:
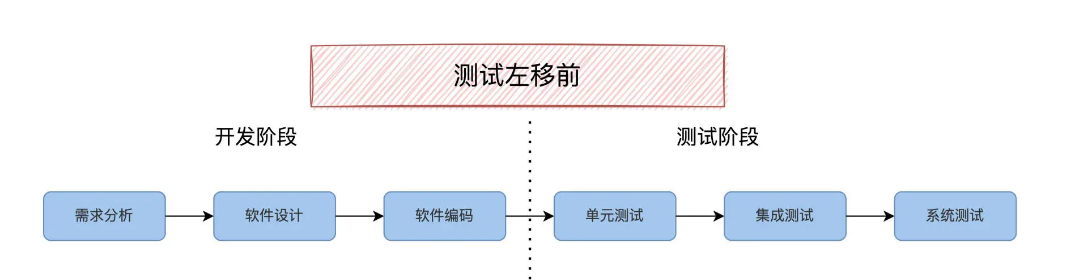
测试左移,就是说本来在生命周期后期的测试活动提前,在软件开发阶段就参与进来,能让软件质量内建到开发阶段,而不是在后期通过软件测试去发现。比如在需求分析阶段参与需求评审和规范制定,在软件设计阶段就开始测试案例设计。形象地看,是测试活动从右侧向左侧移动,即测试左移。
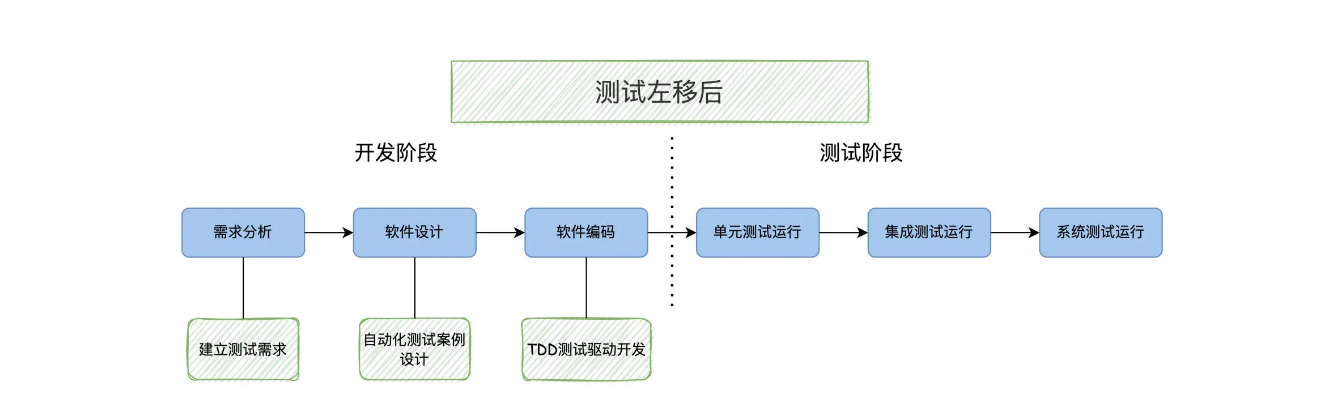
测试左移后,当然也会带动自动化测试的变化。在传统模式下,按照软件生命周期顺序,自动化测试是这么安排的:编码完成之后运行单元测试,集成阶段运行接口测试,系统阶段运行 UI 自动化测试。
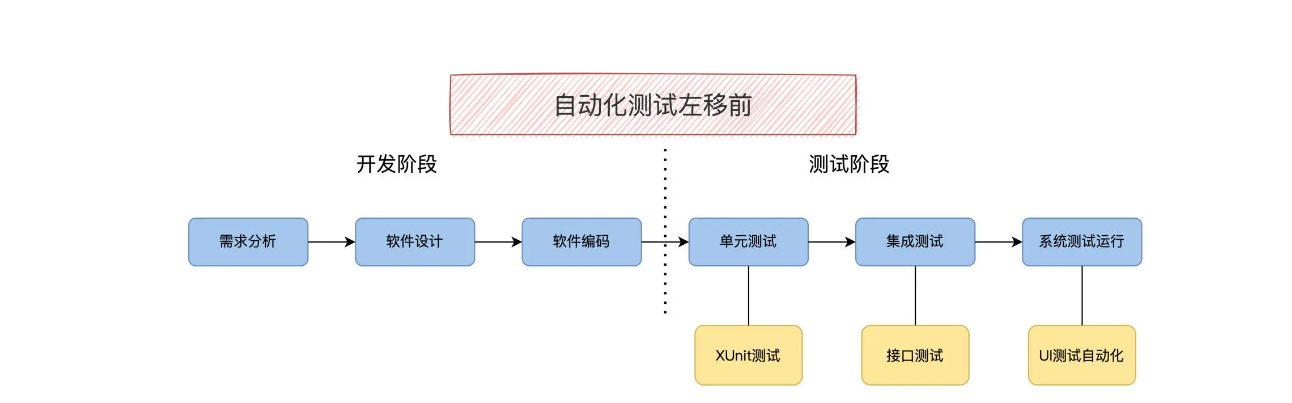
这种流水线做法只能说中规中矩,那还有优化提升空间么?从图上看到,我们如果在编码阶段引入了 bug,影响接口的 bug 要等到集成测试阶段才能发现,影响 UI 的 bug 要等到系统阶段才能发现。我们既然已经有了接口和 UI 自动化测试,可不可以把它们利用起来,尽早测试呢?
现在我提出一个新概念,自动化测试左移,在构建阶段建立一个冒烟测试集合的概念,包括单元测试和部分接口测试,甚至部分 UI 自动化测试,它们一起运行,来验证版本的每一次构建甚至代码的每一次提交。只要这个冒烟测试集合足够快和稳定,就可以被开发人员接受。
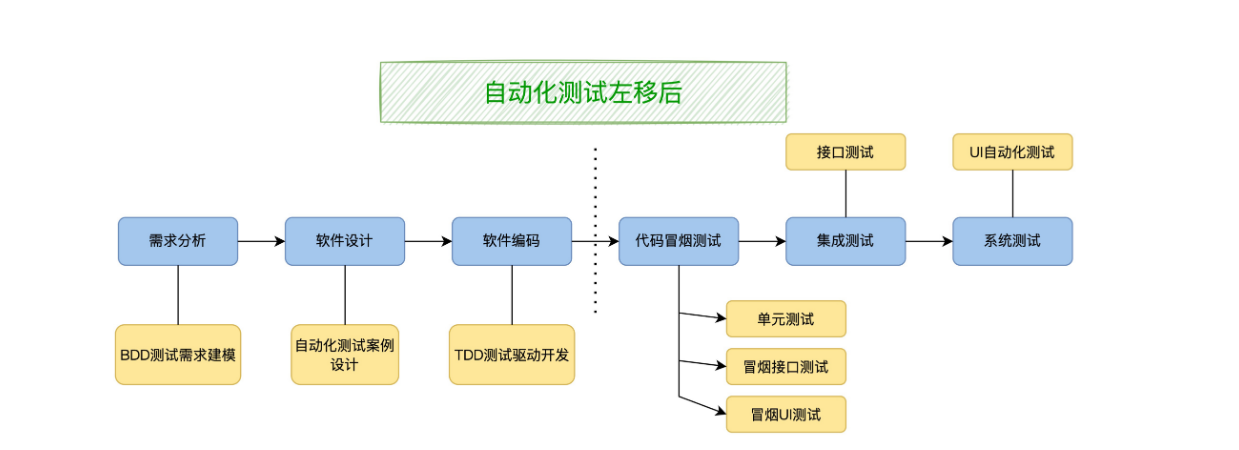
自动化测试左移都有哪些好处呢?
最直观的好处是提早确认代码的变更,满足最终需求,尽早发现回归 bug。软件测试领域有一个理论,叫做验证和确认,在每个软件阶段,都要做两种测试工作:第一是验证当前阶段做好了本阶段要求的事情。比如,编码阶段要把详细设计实现;第二是确认当前阶段实现的功能,可以满足最终的用户需求。
应用到具体场景里,在编码阶段做单元测试这叫验证,在编码阶段运行接口测试和 UI 自动化测试则是确认,都是有价值的测试活动。
此外,自动化测试就像一辆赛车,需要运行调试、持续保养维护,才能调整到最佳状态。
我见过一些团队,只在软件产品发布的时候,才把开发出来的 UI 自动化测试作为验收测试运行一次。这样 UI 自动化测试大概率会失败,测试人员不得不花时间一一解决。不难猜到,在整个发布周期里,UI 功能都变化了很多,相应的漏洞更是不可胜数。久而久之,测试人员就对自动化测试产生了厌烦,把它看成摆设、负担,又重归手工测试的状态。
而自动化测试左移到开发的日常活动中,开发人员每天做一次 code commit,做一次版本构建就会触发自动化测试,运行频率随之提高。一旦自动化测试运行失败,要么是发现了回归 bug,要么是自动化测试需要维护了,问题发现得越早,修复越快,自动化测试就越健康,越稳定可用。在磨合调试的动态过程里,自动化测试越跑越稳定高效,团队也能实实在在体会到它的用处。
所以,自动化测试左移在结果上提高了 ROI,丰富了运行场景,也锻炼了自动化测试项目和人马。火炼真金,大浪淘沙,方能走向成功。
自动化测试右移
既然有左移,那也存在右移。测试的右移是什么?测试阶段结束,产品就会上线,也就进入了线上运维阶段。所以测试右移是指测试活动介入线上运维,用户画像等工作。这里我说的自动化测试右移,意思是自动化测试也可以在生产环境里运行,起到一个自动检查监测的作用。
你可能会问,线上观测已经有了一套 Ops 流程和工具了,比如 Newrelic 和 Splunk 等,都能监测 Web 服务、API 网关,数据库等全栈环境了。自动化测试线上运行的价值在哪里?
部署后验证测试
Ops 工具看似很强大,能输出一堆软件服务的各种度量指标,告诉我们软件服务在生产环境里是健康运行的,但是有一个关键的事情,我们无法从 Ops 那里得知:那就是服务是不是按照客户的期望运行的,这对产品价值非常重要,但只有运行测试才能知道。
结合具体场景,我们分析一下这个问题是怎么产生和解决的。
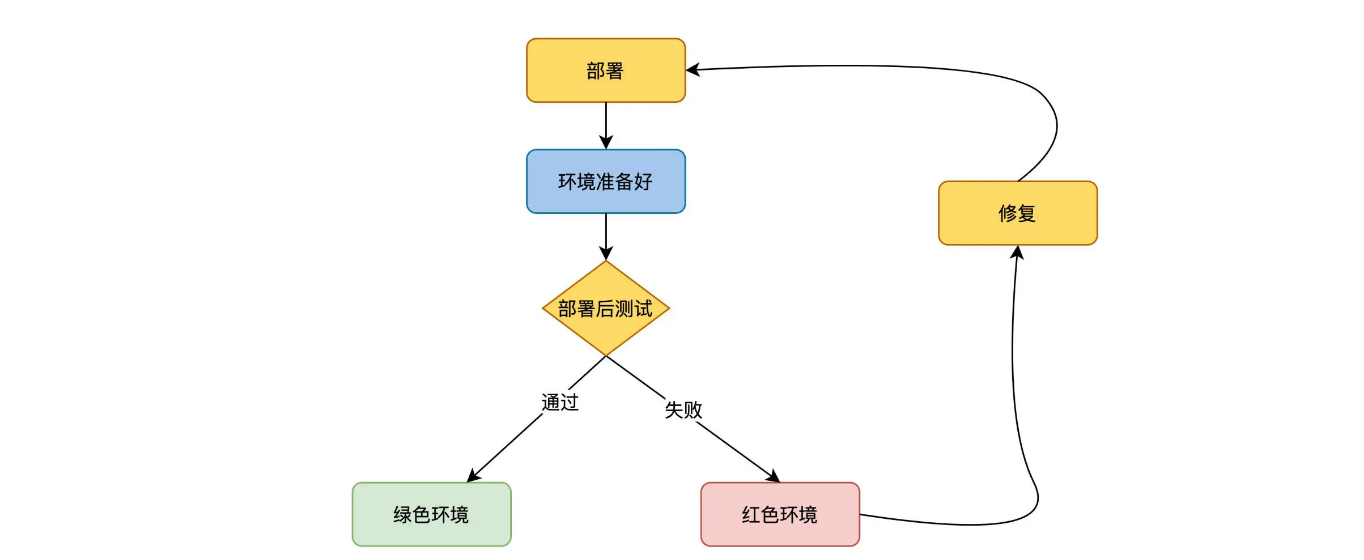
线上升级常用的做法是红绿部署(也叫蓝绿部署)。红绿部署的机制是这样的,当准备升级软件服务时,保持原有的服务红色环境不变,部署一套新的服务绿色环境。在路由层面,把流量切换到绿色环境,完成软件的升级。这样做的好处是,软件升级对用户影响微小,风险也可控。
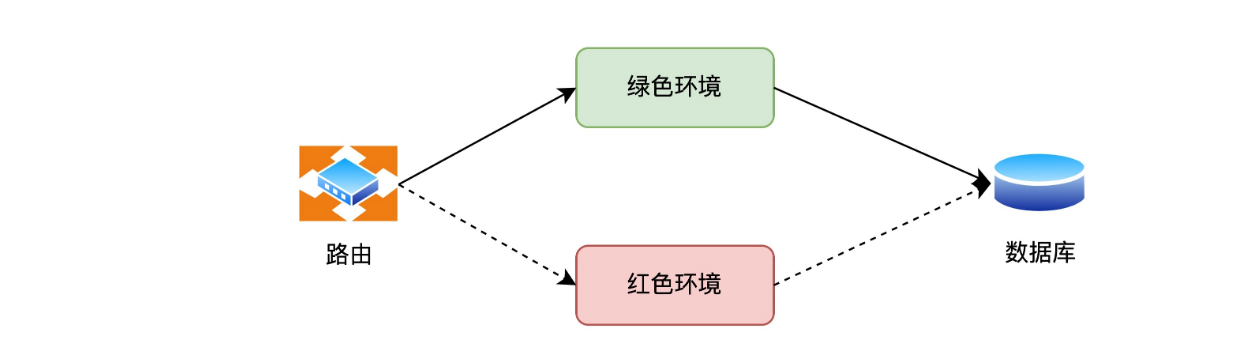
通过 Post Deployment Test 的通过与否,来设定环境是绿色还是红色。像下图:
生产环境定时监测
部署升级后,生产环境就开始运行了,直到下一次升级为止。在这段线上运行的时间里,是不是就不再需要测试了呢?
按照传统测试理论,测试的生命周期到正式发布为止,也有的到 Beta 测试为止,而部署到生产环境后,就进入了运维阶段,就是 Ops 工程师的事了,测试人员就不需要关注了。
但在云时代情况发生了变化。软件开发方不仅交付软件服务,而且也控制着服务器的运行环境。因此测试人员的责任从“在软件发布之前发现 bug”变成了“在客户之前发现 bug”。
有很多 bug,在测试环境里是发现不了的,只有生产环境才能暴露。这些跟客户的行为、生产环境的数据、特定的错误扩散模式都有关系。只要我们在客户遇到 bug 之前发现它,测试工作仍然是有价值的。
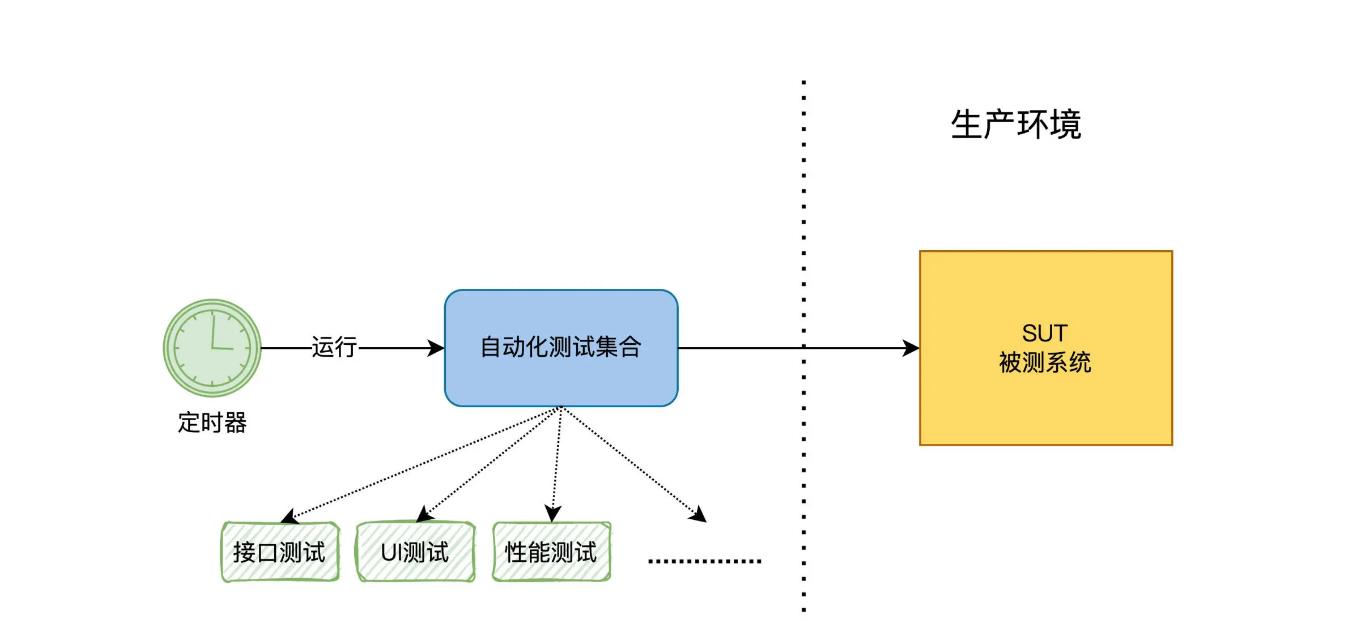
这时我们可以建立一个机制,通过自动化测试来定时监测生产环境。每天定时触发自动化测试任务的运行,去检测生产环境的业务功能是否正常,然后生成测试报告。
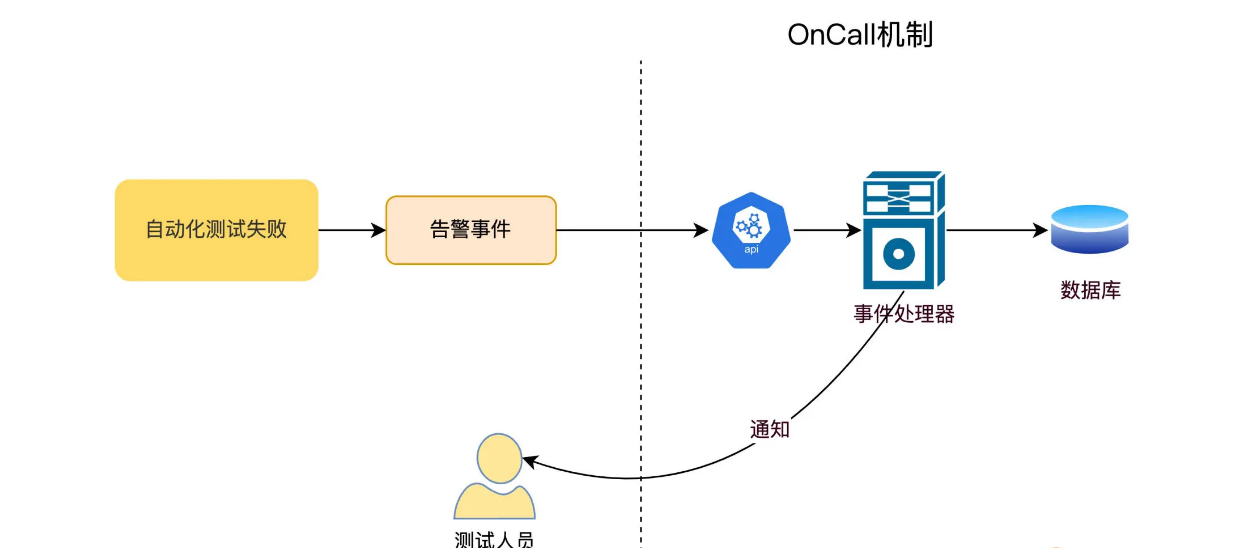
对于自动化测试生成的结果报告,我们还可以把它集成到 Ops 的 Oncall 流程里去。当自动化测试任务出了错误,触发 Event 时,就会进入到 Oncall 系统。Oncall 系统会找出值守的测试人员,发送通知,让测试人员来处理测试错误,判断是不是线上出了 bug。
cucumber
Cucumber 是一个支持行为驱动开发 (BDD) 的软件工具,它允许开发者、QA 工程师和非技术干系人在软件开发过程中共同参与。以下是 Cucumber 的主要特点和用法:
- 描述行为:
- Cucumber 允许用户使用自然语言(通过 Gherkin 语言)编写软件的期望行为。这使得即使是非技术团队成员也能理解和参与到需求和测试的定义中。
- 自动化测试:
- 通过将 Gherkin 语言的描述转换为代码,Cucumber 可以自动执行这些描述的测试。这为自动化验收测试提供了一个强大的框架。
- 支持多种编程语言:
- Cucumber 支持多种编程语言,包括 Ruby、Java、JavaScript、Python 等,使其能够集成到多种不同的技术堆栈中。
- 促进团队协作:
- 通过提供一个共同理解和描述软件行为的平台,Cucumber 有助于提高开发、测试和业务团队之间的沟通和协作。
- 持续集成与持续交付(CI/CD):
- Cucumber 可以集成到持续集成和持续交付的流程中,自动执行测试,确保软件的质量。
- 可插拔和扩展性:
- Cucumber 提供了一个可插拔的架构,允许开发者和测试工程师通过插件和自定义代码来扩展其功能。
- 生成报告:
- Cucumber 能够生成易于理解的测试报告,显示哪些测试通过了,哪些测试失败了,以及为什么失败。
Cucumber 支持 Go 语言
是的,Cucumber 确实支持 Go 语言,通过一个名为 Godog 的项目实现。以下是一些相关的信息:
- Godog 项目:
- Godog 是 Cucumber 的 Go 语言实现,它是 Go 语言的官方 Cucumber BDD(行为驱动开发)框架。该框架合并了规范和测试文档,使用 Gherkin 格式的场景描述来格式化给定的、何时的和然后的规范。值得注意的是,Godog 不会干预标准的
go test命令行为。
- Godog 是 Cucumber 的 Go 语言实现,它是 Go 语言的官方 Cucumber BDD(行为驱动开发)框架。该框架合并了规范和测试文档,使用 Gherkin 格式的场景描述来格式化给定的、何时的和然后的规范。值得注意的是,Godog 不会干预标准的
- 官方文档:
- 在 Cucumber 的官方文档中也有提到 Godog,并且有一个 专门的仓库 用于维护 Godog 项目。
- GitHub 仓库:
- Godog 的 GitHub 仓库 是该项目的官方源代码仓库,你可以在这里找到有关 Godog 的所有信息,包括如何使用它来进行 BDD、示例、文档以及该项目的许可信息。
- 其他信息:
- 还有一个相关的 GitHub Issue 提议将 Go(Godog)支持添加到 Cucumber 的 language-service 项目中,这显示了 Cucumber 社区对 Go 语言支持的持续关注和开发。
单体到微服务集群要测什么
单体怎么测
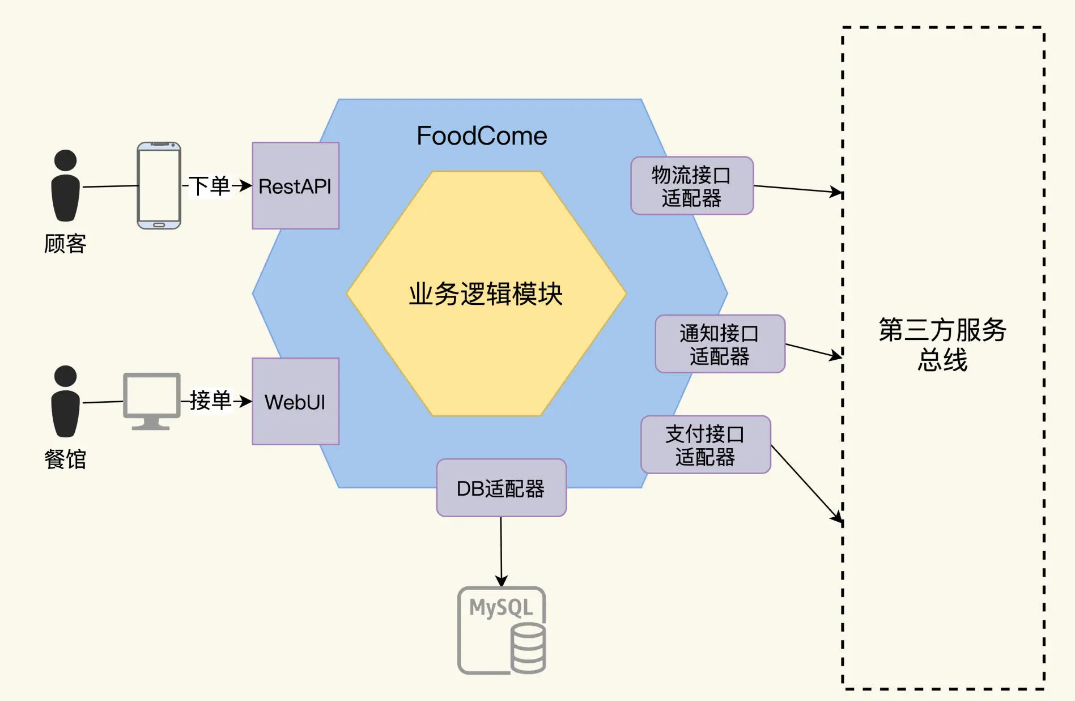
我们现在有一个名为 FoodCome 的应用。它刚开发出来的时候是一个单体系统。
这里要解释一下,什么是单体系统。一般的理解是,单体系统是一个整体,用一种语言开发,一次构建所有代码,产生一个部署实体,在运行态下是一个进程。比如常见的 Web 应用,就是一个 war 包。
这个 FoodCome 就是一个 Web 应用,它为用户提供点餐功能。用户可以通过手机下单点餐,订单生成后,餐馆可以接单,厨房制作完成,转给物流交付给用户。
为了分析测试需求,我们用六边形架构图方法来理清系统内外的交互接口。六边形架构法是把服务画成一个嵌套的六边形,最外层的大六边形是适配器层,代表了本系统和对外的所有交互。里层的六边形是领域业务层。适配器层负责对外交互,这个和业务关系不大,一般是通用的技术,主要是驱动、协议和基础设施,而领域层是业务逻辑的组织和实现。如果你对六边形架构不太熟悉,还可以参考这里了解。
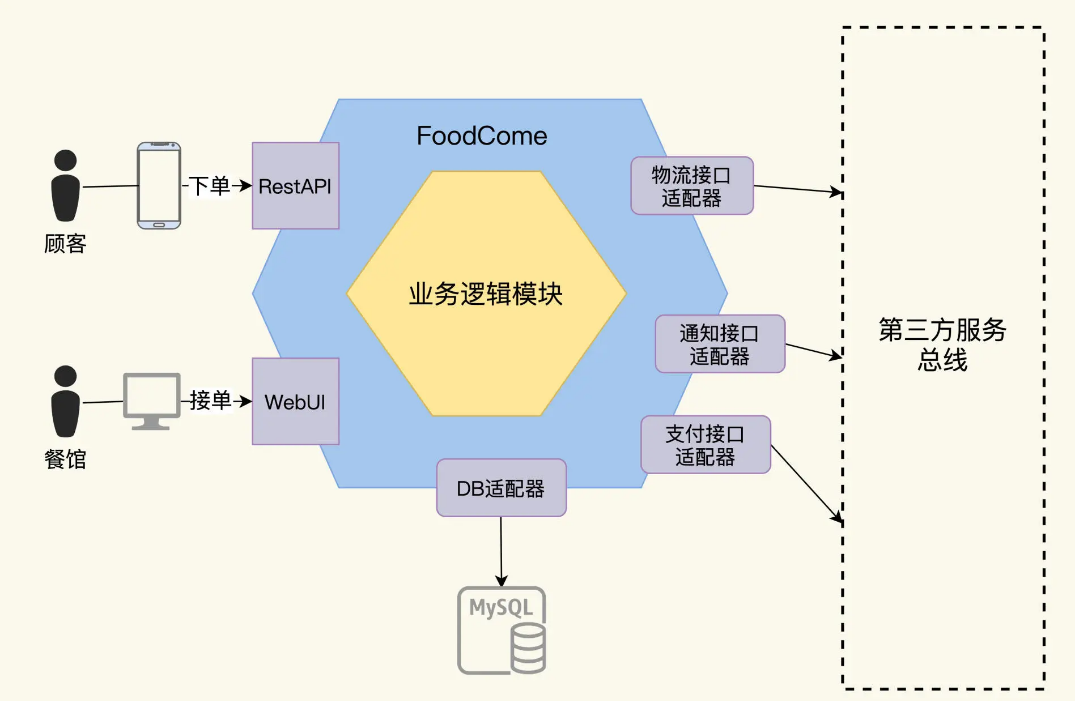
FoodCome 是一个单体系统,它运行起来后,外层六边形上的接口有这么 2 种:
- 用户接口,用户有 2 种类型,一个是食客顾客,一个是餐馆业主。顾客通过手机下单,进入到 FoodCome 系统,而餐馆通过 FoodCome 的 Web 客户端可以查看和接受订单。
- 适配器接口,和第三方系统的集成接口。FoodCome 集成了物流系统、通知系统和支付系统。顾客的订单通过支付系统完成支付后,餐馆开始加工,加工完毕后,食品通过物流系统快递给顾客。整个工作流,都会有状态的变更通知发送给用户。
2 种接口明确了,我们再具体分析下测试需求都有哪些。
想定义测试需求,先要明确功能需求。功能需求是描述软件的功能,听着是不是像循环定义?想描述清楚软件的功能并不容易,这里我们借用迈克·凯恩提出的方法,一个软件软件功能需求要回答这三个问题:第一,这个功能存在的价值是什么?第二,软件是怎么实现这个价值的?第三,这个功能能给谁带来价值?
测试需求 BDD Feature
BDD 的全称叫做 Behavior Drive Development,行为驱动开发模式。想达到驱动开发的程度,这个 Behavior 行为的定义就要足够细化,开发人员知道怎么去实现了,同样,测试人员也知道该怎么测试了。
BDD 是怎么做的呢?它把 User Story 细化成一个或多个 feature,每一个 feature 都是一个可测试的场景。
这个 feature 的文件书写也是有格式要求的,通过一个叫做 Gherkins 的语法关键字模版来写 feature 文件。
Gherkins 的语法关键字模版 Gherkins 提供的常见关键字有: 1.Given: 用户场景的前提条件,可以是时间条件,也可以是另外一个用户场景的输出结果。 2.When: 用户在这个场景里做的行为操作 3.Then: 行为的输出结果 4.And: 连接多个关键字
Gherkins 提供的常见关键字有:
- Given: 用户场景的前提条件,可以是时间条件,也可以是另外一个用户场景的输出结果。
- When: 用户在这个场景里做的行为操作
- Then: 行为的输出结果
- And: 连接多个关键字
微服务怎么测
同时,软件技术也在发展,出现了 VMware、Docker 和 Kubernetes 等轻量化部署方式,这使得拆分的困难变小,部署的成本降低。微服务架构诞生后,一个系统拆分成多个独立开发和运行的服务,这个服务不管大小,业界都管它叫微服务。它们也有一套服务治理的技术规范,用来保证部署和运行的可靠性和扩展性。
随着业务规模的扩大,开发人手增加,FoodCome 被拆分成 5 个微服务,具体如下:
- 订单服务:处理用户下的订单;
- 物流服务:Foodcome 内部的物流管理,与外部物流对接;
- 餐馆服务:管理餐馆的信息,参与订单的工作流;
- 账户服务:管理订单里的顾客信息,和外部的支付系统对接。
- 通知服务:产生消息通知用户,和外部的邮件系统对接。
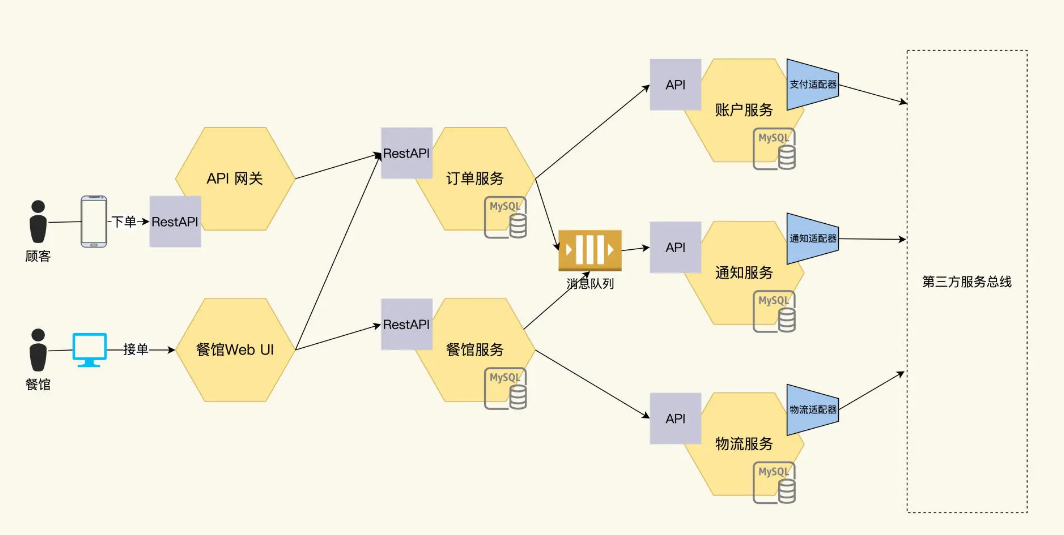
在这个架构下,原先单体应用的对外接口保持不变,但是单体应用内部被 5 个独立的微服务取代。用户的订单请求先通过 API 网关到达订单服务,完成支付后,餐馆接单,再通过物流系统交付订单。
每个微服务实现自治,独立开发和发布部署,加快发布速度。而且增加新功能也很方便,比如登录鉴权,在这个图中再增加一个认证服务就可以,这是给客户带来的好处。
现在的问题是,这给测试带来哪些变化呢?分拆后,FoodCome 系统变成了微服务集群,就像一部巨大机器,由多个零件组成,互相咬合,一起工作。作为测试人员,不但要验证每个零件是合格的,还要有办法预测它们组装起来的机器也能正常工作。
这里的测试难点是,微服务的数量增加,服务间的交互量也会剧增,相比单体系统,集成测试在微服务集群架构下更加关键。
要做集成测试,我们就先搞明白微服务间是怎么交互的。在微服务架构下,交互可以有多种风格,比如 RPC 远程过程调用、REST 风格、Message Queue 消息队列等等。根据交互的方法和风格,我把它们整理出一个表格,方便你理解。
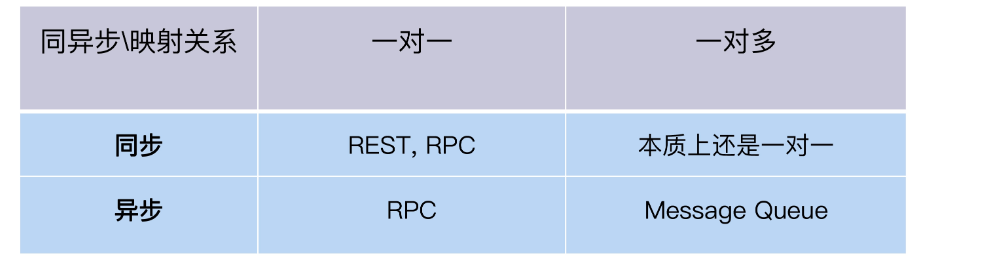
在 FoodCome 采用了两种交互方式,RestAPI 和 Message Queue。
RestAPI 用来处理实时性强的服务间交互,比如前端通过 API 网关调用订单服务来下订单。
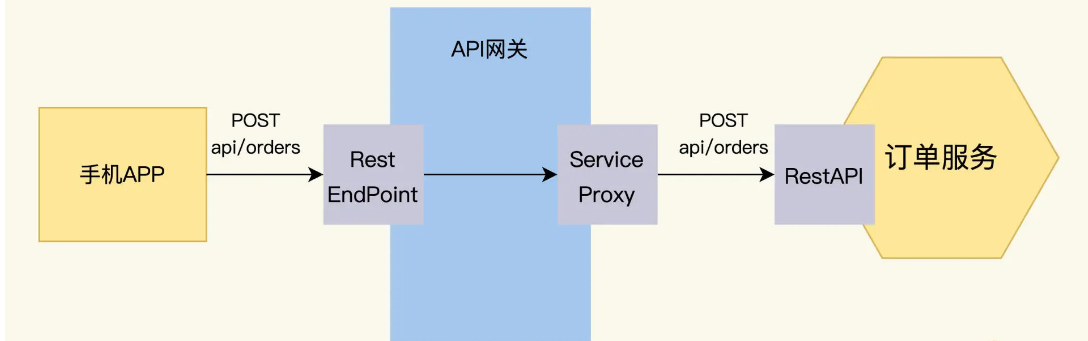
Message Queue 用来处理异步的交互,订单服务和通知服务之间通过 Message Queue 来交换信息.
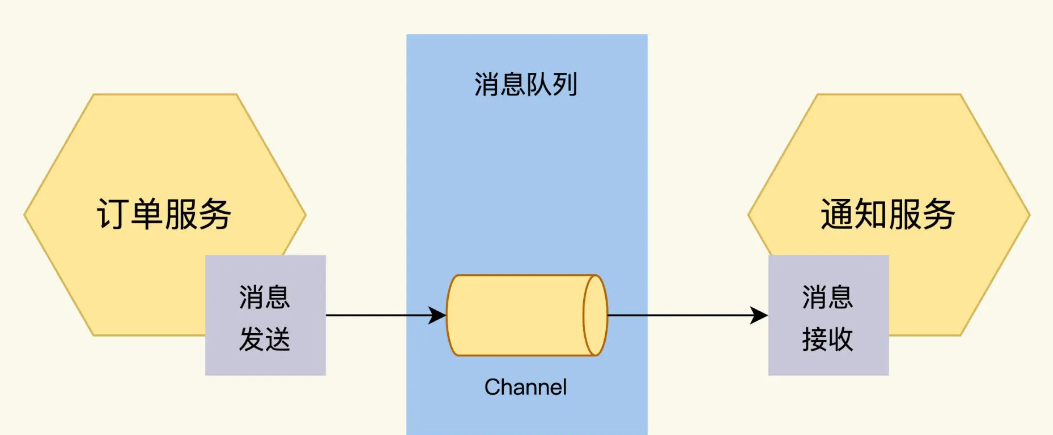
下面我们来看一下这两种交互方式的具体实现,然后找出测试点。
REST
我们需要先知道 Rest 接口是怎么设计的,才能找出后面都要测什么。
什么是 REST
REST 是 Representational State Transfer 的缩写,叫做表现层状态转换。听起来挺拗口,但我一说你就能懂,它其实是一组松散的规范,不是严格的协议,也不是强制的标准。这个规范的目的就是让 API 的设计更加简单易懂。
它包含以下几个基本原则:
- REST 是基于 HTTP 协议的;
- 通过 HTTP 的 URL 暴露 Resource 资源;
- 通过 HTTP 的操作原语,提供对 Resource 的操作,GET、 POST、PUT、DELETE 对应着增删改查的操作。
只要开发人员懂 HTTP 协议,按照上面的规则用 REST 风格表达他的 API 是很容易的。同样,另外一个开发人员看到 REST API,也很快就能知道这些 API 是干什么用的,几乎不用看难懂的文档。
这是 REST 的优点,REST 风格下设计的 AP,学习成本非常低,所以互联网上有很多服务都是通过 REST 方式对外提供 API,比如亚马逊的 AWS 云服务、Google 的 Document 服务等等。
Order Service 的 REST API 设计
遵循 REST 规范,Order Service 的接口设计可以按照“名词 - 动词”的思路来捋清。
首先寻找名词,Order,它对应 REST 上的一个 Resource 资源:
http://api.foodcome.com/api/v1/orders
再找到动词“下单”,它对应 HTTP 协议上的 POST 原语,对 Orders 资源发送 POST 请求就是下单:
POST http://api.foodcome.com/api/v1/orders
之后将“查询订单”这个动词,转成 HTTP 协议上的 GET 原语,查询条件 orderID 以参数形式加在 URL 里:
GET http://api.foodcome.com/api/v1/orders?orderID=123456
同样,修改订单使用 PUT 原语,删除订单使用 DELETE 原语。
我们再用同样的方法来把其他名词“顾客”和“餐馆”,转成 Resource 和操作:
http://api.foodcome.com/api/v1/customers
http://api.foodcome.com/api/v1/restaurants
Order service 的 RestAPI 规格定义
不成熟的开发团队,经常是一边写代码,一边设计 API,这样做的结果不难推测,一千个开发人员会写出一千个 Order Service API,虽然他们都声称遵循了 REST 规范。
所以,好的实践是,开发团队需要先设计 RestAPI,并把它表达出来,然后团队就可以进行评审,达成理解一致。
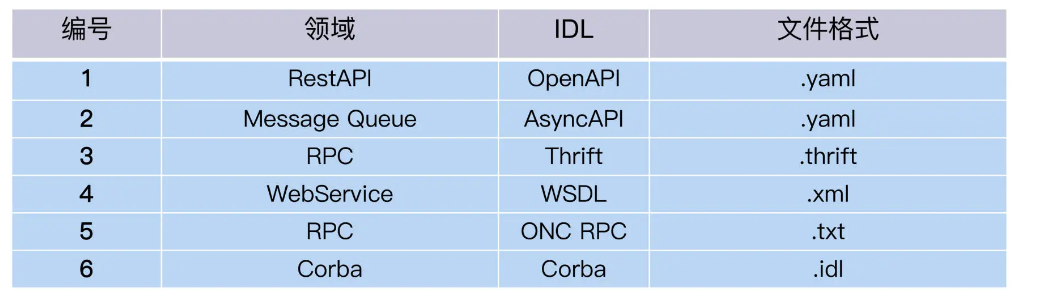
那表达的载体是什么呢?这里就要提到 Interface Definition Language 这个概念了,顾名思义,IDL 是接口定义语言,它通过一种独立于编程语言的语法规则来描述 API。不同类型的 API,它的 IDL 是不一样的。
我们用 REST 主流的 IDL,也就是 OpenAPI 的语法规范,来描述下订单的这个接口的参数,把请求和响应写在一个 YAML 文件里。
"/api/v1/orders":
post:
consumes:
- application/json
produces:
- application/json
parameters:
- in: body
name: body
description: order placed for Food
required: true
properties:
foodId:
type: integer
shipDate:
type: Date
status:
type: String
enum:
- placed
- accepted
- delivered
responses:
'200':
description: successful operation
'400':
description: invalid order
到这里,FoodCome 服务间的 REST 接口规格说明书就生成了!
这个规格说明书定义了客户端和服务端之间的契约,顾客要下单的话,客户端应该向服务端 api/v1/orders 发送一个请求,里面包含了食品的代码、日期等等,而服务端成功则返回一个 HTTP 200 的响应,失败返回一个 HTTP 400 的响应。
异步消息
说完了同步常用的 REST,我们再分析一下异步消息。
什么是异步消息呢?消息就是客户端和服务端交换的数据,而异步指的是调用的方式,客户端不用等到服务端处理完消息,就可以返回。等服务端处理完,再通知客户端。
异步消息在微服务集群的架构里,能够起到削峰、解耦的作用。比如 FoodCome 在订餐高峰时段,先把订单收下来,放到消息队列,排好队,等待餐馆一个个处理。所以异步消息是现在业界很常用的一种服务交互方式,它的技术原理是消息队列,技术实现是消息代理,有 Kafka、RabbitMQ 等等。
而开发人员在设计微服务时,首先要设计异步消息接口,定义好我的微服务什么时候往消息队列里放消息,放什么样的消息。同样,也要定义好取消息的时机和方法。
异步消息接口设计
首先,要定义消息体,订单服务会向外发出三种消息 OrderCreated、OrderUpdated、OrderCancelled。消息里包含了 order ID、order items、order Status 这些字段。
其次,还要说明这个消息发送到哪个 channel 里。Channel 就是消息的队列,一个消息代理里可以有多个 channel,每个 channel 有不同的功能。
因为 order 的消息有严格的时序,比如,OrderCancelled 和 OrderCreated 这两个消息的顺序反了的话,会引起程序处理的混乱。所以,我们把这三种消息都发送到一个叫 order 的 channel 里。
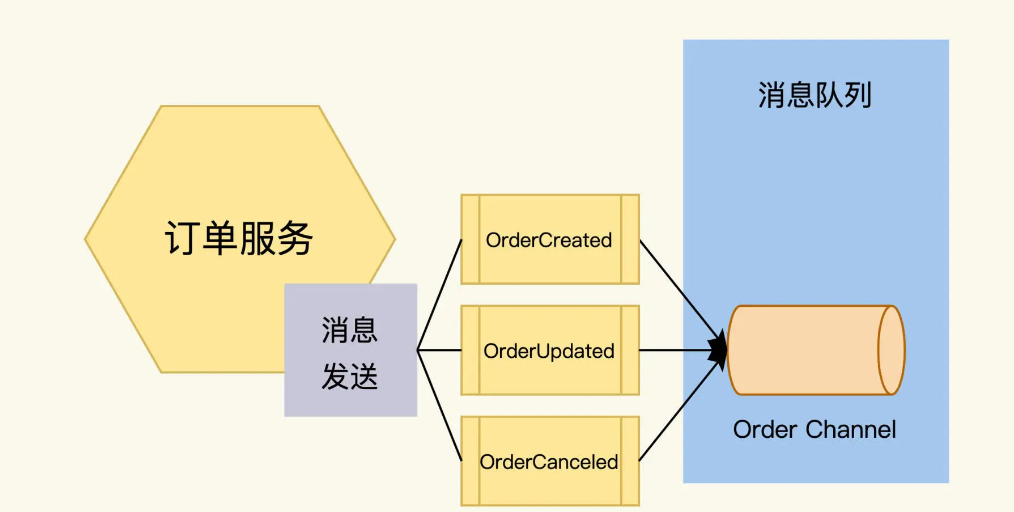
异步消息接口规格说明书
好,下面就到关键环节了,对于测试人员来说,我们最关心的就是接口规格说明书,跟 REST 一样,消息队列也需要找到 IDL 来描述接口上的信息。
RestAPI 的主流 IDL 是 OpenAPI,相对应地,MessageAPI 的 IDL 是 AsyncAPI。上面的 Order 消息接口,用 AsyncAPI 规范来定义,会是下面这个样子:
asyncapi: 2.2.0
info:
title: 订单服务
version: 0.1.0
channels:
order:
subscribe:
message:
description: Order created.
payload:
type: object
properties:
orderID:
type: Integer
orderStatus:
type: string
这段代码描述的是,订单服务在运行时会向 Order channel 输出 OrderCreated 消息,这个 OrderCreated 消息包含了 2 个字段,order 的 ID 和 order 的状态。
在设计阶段测试要做什么?
刚刚我们花了不少篇幅分析 API 设计,如果你之前一直只做测试,也许会疑惑:“这些看起来是开发领域的知识啊,是不是跑题了?”其实我想说的是,API 领域是开发、测试共同关注的。测试应该主动参与到这些领域的活动,才能让测试更加有效。
我曾经看到过两个微服务团队各自开发都很快,但是微服务一上线,就发现问题了,有的是接口就对不上,有的是数据类型不一致等等千奇百怪的问题,这些问题花了大把诊断时间不说,甚至会给客户带来损失。
第一,测试设计先行原则
测试设计先行,需要的是开发设计先行。开发不做设计,测试干着急也没法设计。怎么督促开发设计先行呢?一个关键指标是,它在设计阶段是否输出了接口规格说明书。对于开发工作来说,是需要去代码实现的开发需求。对于测试工作来说,它就是测试需求,需要根据它写测试案例。
第二,找到合适的 IDL 来表达接口设计。
一份周密、高质量的测试需求,会是成功测试的开始。所以这个接口规格说明书不仅要有,还得规范,能指导我们生成测试案例。
怎么做到呢?让开发人员写一份 Word 文档?一千个开发人员能写出一千个规格说明。这时,IDL 的价值就显现出来了,它提供一套规范和语法,像一门专用语言,能精准描述接口。而且它与编程语言无关,可以根据 IDL 做 Java 的实现,也可以是 C++, JavaScript,Python 等等。
OpenAPI 和 AsyncAPI 是 IDL 族群里的 2 种。我这里列出一个常见的 IDL 列表,你可以看看你领域里的 IDL 是什么。
3KU法则:为一个订餐系统设计全栈测试方案
对于一个订餐系统来说,我们把测试需求整理如下:
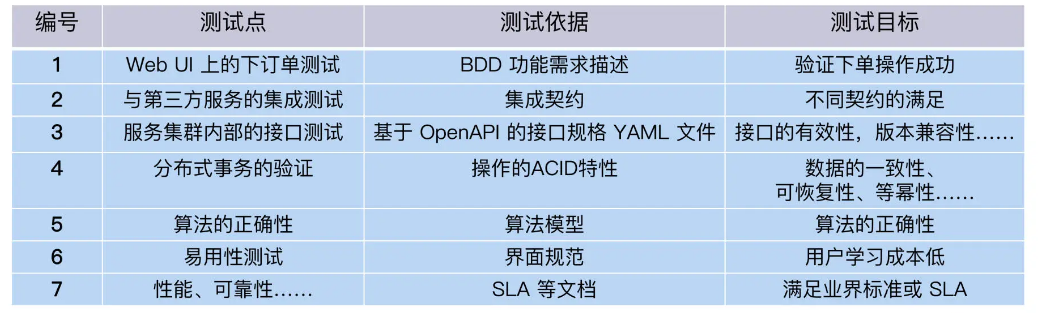
订餐系统还有很多其他的测试需求,比如兼容性、安全性等等,因为本专栏的关注点是自动化测试,我在这里就不再列出来了。
做不做自动化测试?
有了文档化的测试需求列表后,我们在设计自动化测试方案时,需要先想清楚,这些需求做不做自动化测试?
测试四象限法 则能帮我们有效完成这个思考过程。这个测试四象限,是布雷·麦瑞克提出来的方法模型:根据需求的性质和等级 2 个维度,对测试需求进行分类。
一个维度是 测试需求的性质,是技术性还是业务性的?通俗来说就是,如果这个需求越靠近程序员的思维,比如算法、接口、事务等等,它的技术性就越强;而越靠近用户的思维,比如工作流,场景等等,就是业务性越强。
另一个维度是 测试需求的等级,也就是需求属于关键性的还是精益性的?你可以这样理解,关键性的需求指的是,对于用户显式而重要的需求。比方说,一个系统必须能下单,才能成为订餐系统。而精益性的需求指的是用户隐式的需求,没有直接表达出来,但也可能很重要,比如性能、可靠性等等。
好,明白了性质和等级这 2 个维度后,我们现在用这两个维度把测试需求列表过一遍,把它们填到象限里。
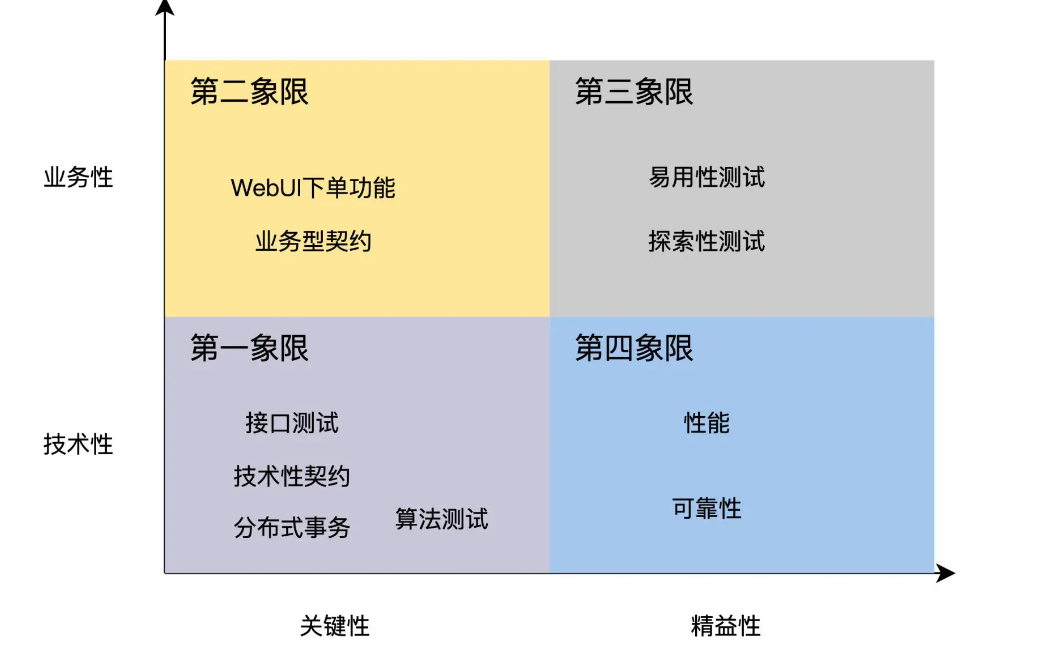
先看算法、接口、分布式事务测试,它们技术性强、也是关键需求,放在了第一象限,WebUI 测试业务性强且属于关键需求,放在了第二象限,易用性测试放在第三象限,性能和可靠性放在第四象限。
针对每个象限,测试四象限法建议自动化测试实施策略如下:
- 第一象限里的测试需求是 100% 全部自动化;
- 第二象限里的测试需求是自动化 + 手工;
- 第三象限里的测试需求是手工测试;
- 第四象限里的测试需求是通过工具和框架来执行,追求 0 代码。
四象限的策略你不必死记硬背,因为这些只是表象,底层逻辑还是 ROI,学会了分析思路你自己也可以推导结论。
举例来说,第一象限里的算法和接口测试,因为它们验证的是关键功能,所以回归测试高,自动化测试收益就大。而技术性强,意味着这类测试不会因业务变化受太大影响,所以开发、维护的成本就低。因此,第一象限的测试需求可以 100% 自动化。至于其他象限的情况,你可以自己试着推演一下,同样符合 ROI 的规律。
在哪个层面做自动化测试?
确定了测试方式,我们还要进一步考虑,这些测试需求的自动化测试是应该在哪个层面实现呢?在单元测试、接口测试还是 UI 自动化测试?
在专栏的第二讲里,我们学习过 3KU 测试矩阵和 3KU 测试金字塔,那就可以把它们应用到 FoodCome 的自动化测试设计了。
排除掉前面表格里提到的手工测试项,我们把其余内容填入到 3KU 测试矩阵里。
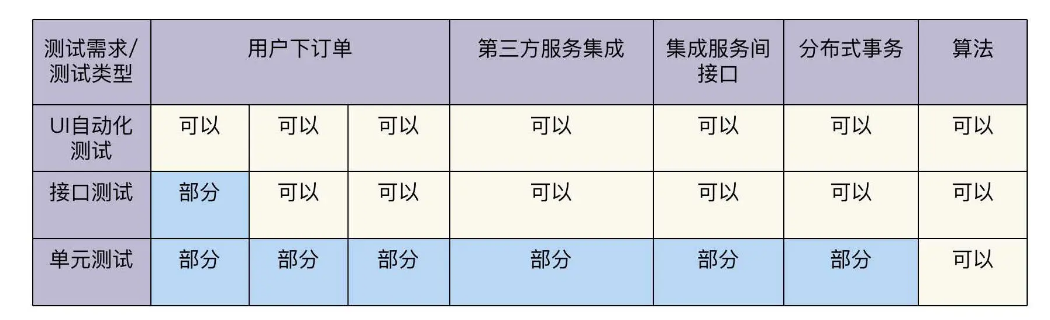
按照自动化测试寻求最大 ROI 实施层面原则,我们把上面的表格,转换成 ROI 自动化测试金字塔。
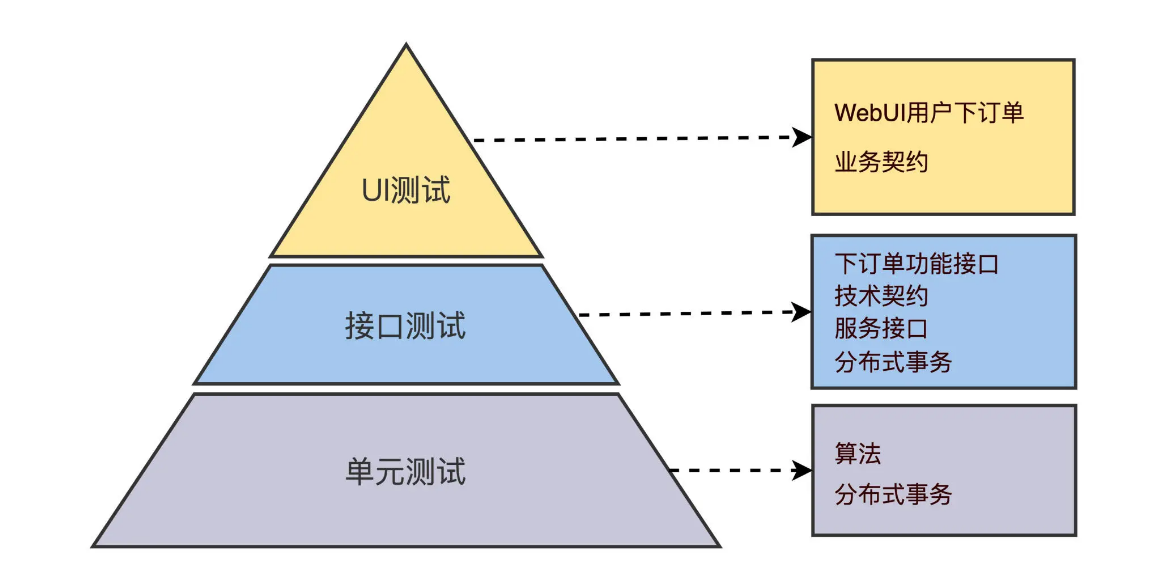
什么工具做自动化测试?
选择对了工具和框架,会让自动化测试事半功倍。这个“选对”的意思,就是工具必须适合你的项目、你的团队。
- 在工作量较小的 UI 测试,工具的稳定性最重要,其次追求效率
- 在工作量大的单元测试和接口测试,要选择成熟和支持模块化开发的工具
运行自动化测试
在自动化测试方案里,除了做不做自动化测试,以及在哪个层面做。我们还要考虑清楚另外一个事,就是自动化测试开发出来后,它们在什么时候运行。
我们再说ROI 的时候,经常提到一个自动化测试的收益,其重要因子之一就是它的运行次数。所以,设计 ROI 高的自动化测试的运行场景是很关键的,而软件部署管线 Deployment Pipeline 就是重要的自动化测试运行场景之一。
那 Deployment Pipleline 是怎么设计的呢?先从概念说起,在 2010 年,Jez Humble 出版了《持续交付》一书,这里提出了部署管线的概念:
“部署管线是代码从开发人员的个人电脑到生产环境的自动化过程”。
为什么会叫管线呢?因为部署管线由一系列测试的阶段组成,每个阶段首尾相接,这就形成了一条流水线一样的管道。
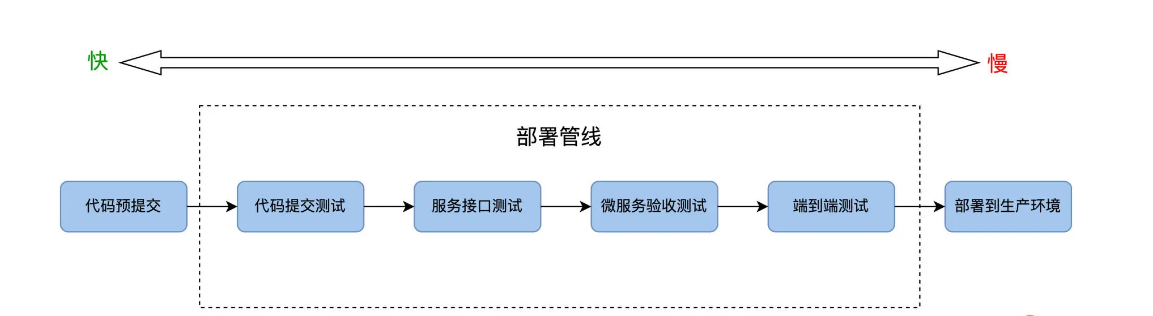
我们把 FoodCome 的自动化测试任务,填充到部署管线的各个阶段里去,如下图所示:
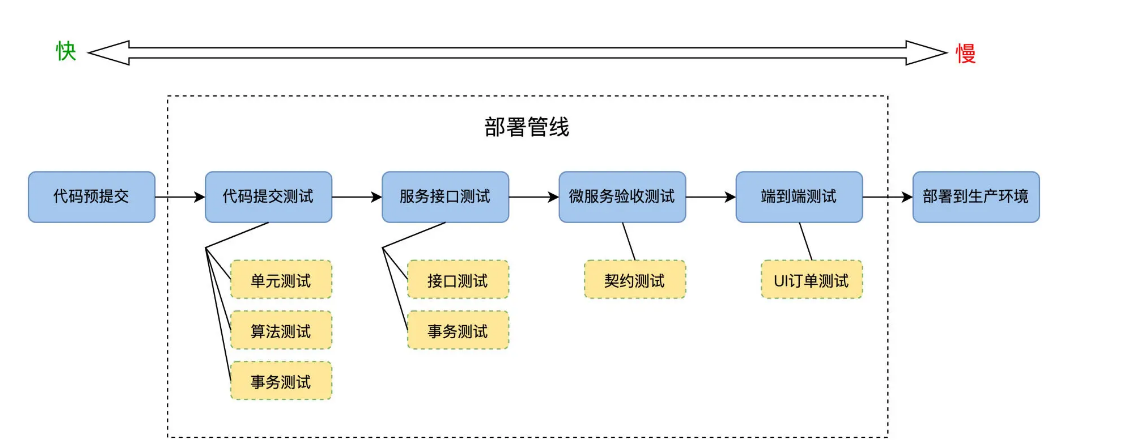
沿着部署管线发布的方向,也就是从左向右,自动化测试的运行速度由快变慢,而 ROI 也是由高到低。越靠近代码,活动越频繁,ROI 就越高,而每一个关卡都会有失败的,最后能成功到达可部署生产环境的会是很少一部分,十次代码变更能有二次到生产环境。
这对于 Actions 中的设计也是很巧妙的,到底是并行执行,还是依次执行。
单元测试
单元测试是最基本的测试,是 ROI 最顶部的测试,投入产出比最高
现在 Order 服务的开发想要测试自己写的这些代码是否预期运转,他最先想到的办法可能是,把 Order 服务构建完运行起来,向它发送 HTTP Request “POST /api/v1/orders” , 然后检查返回的 Response 内容,看是不是订单已经如期生成。
这个方法当然也能达到测试目标,但是你已经学习过了 3KU 原则,就可以问开发人员一个问题 “同样的验证目标,能不能在 ROI 更高的单元测试阶段实现?”
制定单元测试策略
比如,对于一个订单系统(Order)来说。
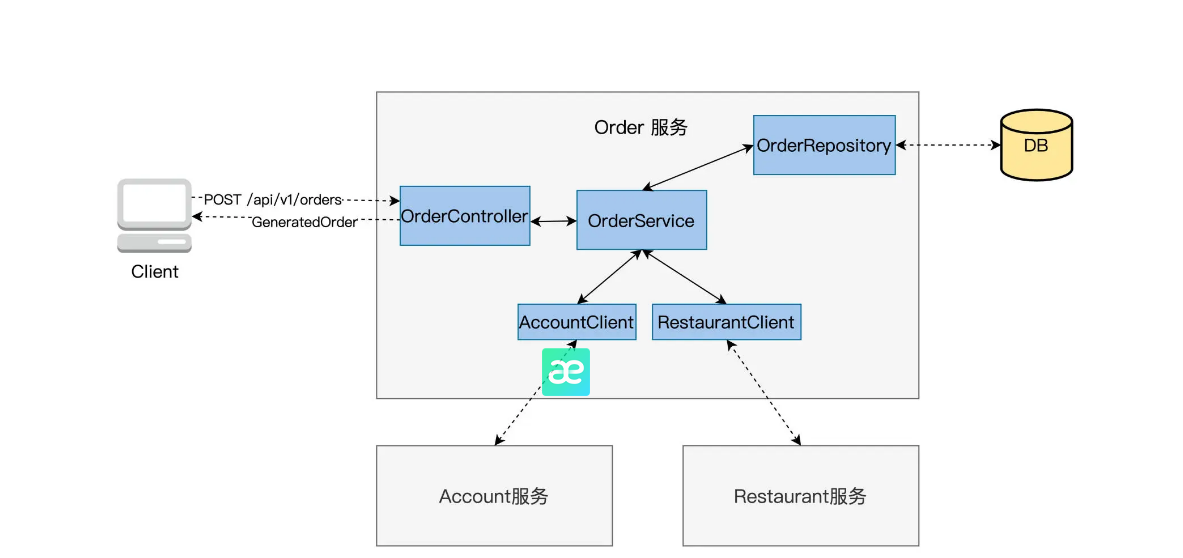
我们先看图里的蓝色色块,通过这五个 Class 就能实现 Order 服务。
它们是这样分工的:OrderController 接收 Client 发来的 POST /api/v1/orders" request, 交传给 OrderService createOrder 方法处理,再把生成的订单信息封装成 Response 返还给 Client;
OrderService 是主要的业务逻辑类,它的 createOrder 完成了一个订单创建的所有工作,计算价格、优惠扣减,调用 AccountClient 做支付验证,调用 RestaurantClient 做餐馆库存查验。订单生成后,就交给 OrderRepository 去写 DB 生成订单记录。
OrderRepository 实现了和 Order 自带的数据库交互,读写操作。
知道了这些,还无法马上动工写单元测试代码,我们还需要考虑清楚后面这几件事。
需要写多少个 Test Class?
这里我需要交代一个背景知识,那就是单元测试里的“单元”是什么?
如果你问不同的开发人员,可能会得到非常不一样的答案。在过程语言里,比如 C、脚本语言,单元应该就是一个函数,单元测试就是调用这个函数,验证它的输出。而面向对象语言,C++ 或者 Java,单元是一个 Production Class。
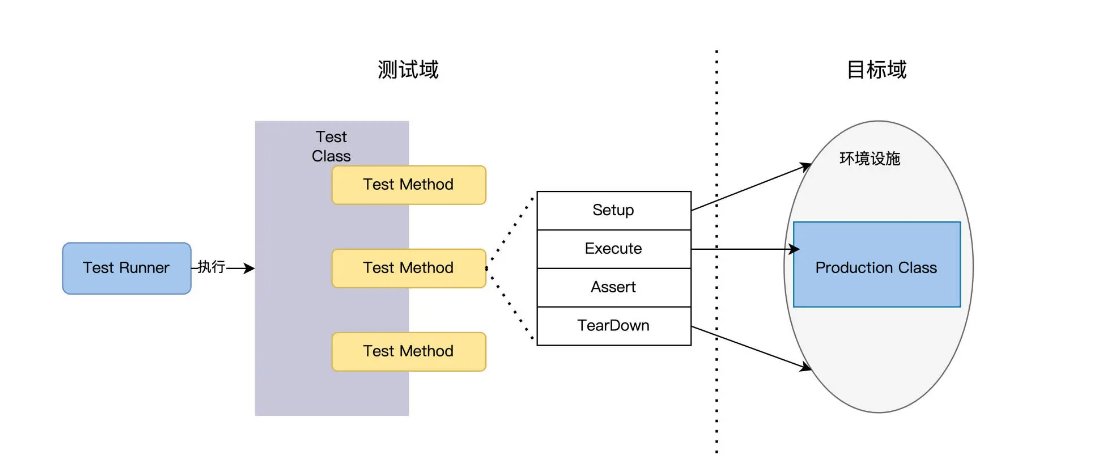
FoodCome 系统是 Java 面向对象语言开发的,包含 5 个 Production Class,做单元测试,我们把规则设得简单一点,开发一个 Test Class 去测试一个 Production Class,保持一对一的关系。
如下图所示,一个 Test Class 有多个 Test Method。每个 Method 会 Setup 建立 Production Class 的上下文环境,Execute 调用 Production Class 的 Method,Assert 验证输出,TearDown 销毁上下文。
孤立型还是社交型?
package main
import (
"testing"
"github.com/stretchr/testify/mock"
"github.com/stretchr/testify/assert"
)
// 定义模拟对象
type MockOrderRepository struct {
mock.Mock
}
type MockAccountClient struct {
mock.Mock
}
type MockRestaurantClient struct {
mock.Mock
}
func TestOrderService(t *testing.T) {
// 初始化 mock 对象
orderRepository := new(MockOrderRepository)
accountClient := new(MockAccountClient)
restaurantClient := new(MockRestaurantClient)
// 创建 OrderService 实例
orderService := NewOrderService(orderRepository, accountClient, restaurantClient)
// 定义测试用例的输入和期望输出
orderDetails := &OrderDetails{
// ... 初始化订单详情 ...
}
// 定义 mock 对象的期望行为
// 例如:
// accountClient.On("SomeMethod", someInput).Return(someOutput)
// 执行测试用例
err := orderService.CreateOrder(orderDetails)
// 断言测试结果
assert.Nil(t, err, "Error should be nil")
// 验证 mock 对象的期望行为是否都被调用
orderRepository.AssertExpectations(t)
accountClient.AssertExpectations(t)
restaurantClient.AssertExpectations(t)
}
注意: 这里我们使用了 github.com/stretchr/testify/assert 和 github.com/stretchr/testify/mock 这两个包来辅助我们进行断言和模拟对象的操作。你需要使用 Go 的包管理工具(如 Go Modules)来获取这两个依赖。
在这个基本例子中,你可以:
- 使用
Mock结构体来模拟OrderService依赖的服务。 - 使用
On和Return方法来定义模拟对象的期望行为。 - 使用
AssertExpectations方法来检查模拟对象的期望行为是否都被调用。 - 使用
assert函数来进行断言检查。
在 Go 语言的单元测试中,我们可以通过表格驱动测试(table-driven tests)来实现类似于 JUnit @DataProvider 的功能。这样,我们可以用一组测试用例来测试一个函数,而不必为每个测试用例都写一个单独的测试函数。这也是 Go 测试中非常常见的一种模式。
接下来的 Go 代码示例展示了如何使用表格驱动测试来测试一个名为 determineFinalPrice 的函数(假设这个函数属于一个名为 OrderService 的结构体,并接收一个名为 OrderDetails 的参数,返回一个最终价格)。另外,考虑到你提到的优惠券和价格计算的复杂性,这些测试用例可能会包括各种各样的输入和预期输出。具体的测试逻辑和断言可能需要你根据实际的业务逻辑进行调整。
以下是用 Go 语言实现的单元测试示例:
package main
import (
"testing"
"github.com/stretchr/testify/assert"
)
type OrderDetails struct {
// ... 具体的字段和类型 ...
}
type OrderService struct {
// ... 其他依赖和字段 ...
}
func (os *OrderService) determineFinalPrice(details *OrderDetails) float64 {
// ... 实现价格计算的逻辑 ...
}
func TestDetermineFinalPrice(t *testing.T) {
// 初始化 OrderService 实例(如果有依赖,可能需要使用 mock 对象)
orderService := &OrderService{
// ... 初始化字段和依赖 ...
}
// 定义一组测试用例
tests := []struct {
name string // 测试用例的名称
input OrderDetails // 输入数据
expectedPrice float64 // 预期的价格
}{
{
name: "test case 1",
input: OrderDetails{
// ... 初始化测试数据 ...
},
expectedPrice: 100.0,
},
{
name: "test case 2",
input: OrderDetails{
// ... 初始化测试数据 ...
},
expectedPrice: 200.0,
},
// ... 更多测试用例 ...
}
// 遍历并运行测试用例
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
actualPrice := orderService.determineFinalPrice(&tt.input)
assert.Equal(t, tt.expectedPrice, actualPrice)
})
}
}
在上述代码中:
- 我们定义了一个测试用例的切片(
tests),每个测试用例包括名称、输入数据和预期输出。 - 我们使用
t.Run()函数来为每个测试用例执行一个子测试,这样我们可以清晰地看到每个测试用例的运行结果。 - 我们使用
assert.Equal()函数来断言实际输出和预期输出是否相等。
你可能需要根据你的实际业务逻辑来调整 OrderDetails 结构体的定义、determineFinalPrice 函数的。
提高单元测试 ROI
既然单元测试又好又快,那么我们不妨把一些费力气的测试工作挪到这一层。哪些测试比较麻烦呢?
线上购物的场景就很典型,你在网购时一定用过优惠券,这些优惠券的使用条件十分复杂:要知道在什么时间、什么商品会有多大折扣,而且优惠券还存在叠加使用的情况,又有了各种规则,能把人搞晕。但用户可以晕,平台却不能晕,用了优惠券,最终结果还要非常精准地保证盈利,不能亏。
要是在 UI 层面测试优惠券,你需要重复运行大量的测试数据,来产生不同的优惠条件,这个代价是高昂的。
放在单元测试里,这个 TestCase 就好理解了。负责价格计算的是 OrderService 里的 determineFinalPrice 方法,在 determineFinalPrice 里需要考虑和计算各种优惠条件和规则,再输出一个最终价格。
Go 语言中如何写好单元测试
如何写好单元测试?
首先,学会写测试用例。比如如何测试单个函数/方法;比如如何做基准测试;比如如何写出简洁精炼的测试代码;再比如遇到数据库访问等的方法调用时,如何 mock。
然后,写可测试的代码。高内聚,低耦合是软件工程的原则,同样,对测试而言,函数/方法写法不同,测试难度也是不一样的。职责单一,参数类型简单,与其他函数耦合度低的函数往往更容易测试。我们经常会说,“这种代码没法测试”,这种时候,就得思考函数的写法可不可以改得更好一些。为了代码可测试而重构是值得的。
而且值得注意的是,Go 语言比较推荐将单元测试的测试文件和源代码文件放在一起。
测试文件以 _test.go 结尾。比如,当前 package 有 calc.go 一个文件,我们想测试 calc.go 中的 Add 和 Mul 函数,那么应该新建 calc_test.go 作为测试文件。
example/
|--calc.go
|--calc_test.go
假如 calc.go 的代码如下:
package main
func Add(a int, b int) int {
return a + b
}
func Mul(a int, b int) int {
return a * b
}
那么 calc_test.go 中的测试用例可以这么写:
package main
import "testing"
func TestAdd(t *testing.T) {
if ans := Add(1, 2); ans != 3 {
t.Errorf("1 + 2 expected be 3, but %d got", ans)
}
if ans := Add(-10, -20); ans != -30 {
t.Errorf("-10 + -20 expected be -30, but %d got", ans)
}
}
- 测试用例名称一般命名为
Test加上待测试的方法名。 - 测试用的参数有且只有一个,在这里是
t *testing.T。 - 基准测试(benchmark)的参数是
*testing.B,TestMain 的参数是*testing.M类型。
运行 go test,该 package 下所有的测试用例都会被执行。
$ go test
ok example 0.009s
或 go test -v,-v 参数会显示每个用例的测试结果,另外 -cover 参数可以查看覆盖率。
$ go test -v
=== RUN TestAdd
--- PASS: TestAdd (0.00s)
=== RUN TestMul
--- PASS: TestMul (0.00s)
PASS
ok example 0.007s
如果只想运行其中的一个用例,例如 TestAdd,可以用 -run 参数指定,该参数支持通配符 *,和部分正则表达式,例如 ^、$。
$ go test -run TestAdd -v
=== RUN TestAdd
--- PASS: TestAdd (0.00s)
PASS
ok example 0.007s
子测试(Subtests)
子测试是 Go 语言内置支持的,可以在某个测试用例中,根据测试场景使用 t.Run创建不同的子测试用例:
在 Go 语言的测试中,子测试(subtests)是一种能够将一个大的测试分解成几个小的测试单元的策略。这种方法允许我们在一个测试函数中定义多个逻辑上的独立测试用例,并且可以单独运行和验证每个用例。每个子测试通过
t.Run函数来执行,并且具有自己的测试名(通常描述测试的目的或输入数据)和测试逻辑。
表格驱动测试(Table-Driven Tests)
当我们想要对一个函数使用多组输入数据进行测试时,子测试非常有用。我们可以定义一个包含多组输入数据和期望输出的表格(通常是一个结构体切片),然后使用一个循环来迭代表格中的每一行,并为每一行生成一个子测试。
func TestFunction(t *testing.T) { tests := []struct { name string input int expected int }{ {"case 1", 1, 2}, {"case 2", 3, 4}, // ... } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { // 测试逻辑 }) } }使用这方法,我们可以轻松地添加更多的测试用例,而无需为每个用例编写一个新的测试函数。
组织和重用测试逻辑
子测试也可以用来组织测试逻辑。我们可以将一组相关的测试用例组合在一起,并在共享一些设置(setup)和拆卸(teardown)代码的同时,保持每个测试用例的独立。
func TestProcess(t *testing.T) { // 一些设置代码... t.Run("Subtest1", func(t *testing.T) { // 测试逻辑 1 }) t.Run("Subtest2", func(t *testing.T) { // 测试逻辑 2 }) // 一些拆卸代码... }这里的 “Subtest1” 和 “Subtest2” 就是子测试,它们共享外部
TestProcess的设置和拆卸代码,但执行自己的测试逻辑。并行测试
子测试还允许我们轻松地将测试并行化。通过在子测试中调用
t.Parallel(),我们可以让测试并发地运行,这在执行一组耗时的集成测试时非常有用。func TestParallel(t *testing.T) { tests := []struct { name string // ... }{ {"case 1"}, {"case 2"}, // ... } for _, tt := range tests { tt := tt // capture range variable t.Run(tt.name, func(t *testing.T) { t.Parallel() // marks T as capable of running in parallel // 测试逻辑 }) } }
// calc_test.go
func TestMul(t *testing.T) {
t.Run("pos", func(t *testing.T) {
if Mul(2, 3) != 6 {
t.Fatal("fail")
}
})
t.Run("neg", func(t *testing.T) {
if Mul(2, -3) != -6 {
t.Fatal("fail")
}
})
}
- 之前的例子测试失败时使用
t.Error/t.Errorf,这个例子中使用t.Fatal/t.Fatalf,区别在于前者遇错不停,还会继续执行其他的测试用例,后者遇错即停。
运行某个测试用例的子测试:
$ go test -run TestMul/pos -v
=== RUN TestMul
=== RUN TestMul/pos
--- PASS: TestMul (0.00s)
--- PASS: TestMul/pos (0.00s)
PASS
ok example 0.008s
对于多个子测试的场景,更推荐如下的写法(table-driven tests):
// calc_test.go
func TestMul(t *testing.T) {
cases := []struct {
Name string
A, B, Expected int
}{
{"pos", 2, 3, 6},
{"neg", 2, -3, -6},
{"zero", 2, 0, 0},
}
for _, c := range cases {
t.Run(c.Name, func(t *testing.T) {
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
})
}
}
所有用例的数据组织在切片 cases 中,看起来就像一张表,借助循环创建子测试。这样写的好处有:
- 新增用例非常简单,只需给 cases 新增一条测试数据即可。
- 测试代码可读性好,直观地能够看到每个子测试的参数和期待的返回值。
- 用例失败时,报错信息的格式比较统一,测试报告易于阅读。
帮助函数(helpers)
对一些重复的逻辑,抽取出来作为公共的帮助函数(helpers),可以增加测试代码的可读性和可维护性。 借助帮助函数,可以让测试用例的主逻辑看起来更清晰。
例如,我们可以将创建子测试的逻辑抽取出来:
// calc_test.go
package main
import "testing"
type calcCase struct{ A, B, Expected int }
func createMulTestCase(t *testing.T, c *calcCase) {
// t.Helper()
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
}
func TestMul(t *testing.T) {
createMulTestCase(t, &calcCase{2, 3, 6})
createMulTestCase(t, &calcCase{2, -3, -6})
createMulTestCase(t, &calcCase{2, 0, 1}) // wrong case
}
在这里,我们故意创建了一个错误的测试用例,运行 go test,用例失败,会报告错误发生的文件和行号信息:
$ go test
--- FAIL: TestMul (0.00s)
calc_test.go:11: 2 * 0 expected 1, but 0 got
FAIL
exit status 1
FAIL example 0.007s
可以看到,错误发生在第11行,也就是帮助函数 createMulTestCase 内部。18, 19, 20行都调用了该方法,我们第一时间并不能够确定是哪一行发生了错误。有些帮助函数还可能在不同的函数中被调用,报错信息都在同一处,不方便问题定位。因此,Go 语言在 1.9 版本中引入了 t.Helper(),用于标注该函数是帮助函数,报错时将输出帮助函数调用者的信息,而不是帮助函数的内部信息。
修改 createMulTestCase,调用 t.Helper()
func createMulTestCase(c *calcCase, t *testing.T) {
t.Helper()
t.Run(c.Name, func(t *testing.T) {
if ans := Mul(c.A, c.B); ans != c.Expected {
t.Fatalf("%d * %d expected %d, but %d got",
c.A, c.B, c.Expected, ans)
}
})
}
运行 go test,报错信息如下,可以非常清晰地知道,错误发生在第 20 行。
$ go test
--- FAIL: TestMul (0.00s)
calc_test.go:20: 2 * 0 expected 1, but 0 got
FAIL
exit status 1
FAIL example 0.006s
关于 helper 函数的 2 个建议:
- 不要返回错误, 帮助函数内部直接使用
t.Error或t.Fatal即可,在用例主逻辑中不会因为太多的错误处理代码,影响可读性。 - 调用
t.Helper()让报错信息更准确,有助于定位。
setup 和 teardown
如果在同一个测试文件中,每一个测试用例运行前后的逻辑是相同的,一般会写在 setup 和 teardown 函数中。例如执行前需要实例化待测试的对象,如果这个对象比较复杂,很适合将这一部分逻辑提取出来;执行后,可能会做一些资源回收类的工作,例如关闭网络连接,释放文件等。标准库 testing 提供了这样的机制:
func setup() {
fmt.Println("Before all tests")
}
func teardown() {
fmt.Println("After all tests")
}
func Test1(t *testing.T) {
fmt.Println("I'm test1")
}
func Test2(t *testing.T) {
fmt.Println("I'm test2")
}
func TestMain(m *testing.M) {
setup()
code := m.Run()
teardown()
os.Exit(code)
}
- 在这个测试文件中,包含有2个测试用例,
Test1和Test2。 - 如果测试文件中包含函数
TestMain,那么生成的测试将调用 TestMain(m),而不是直接运行测试。 - 调用
m.Run()触发所有测试用例的执行,并使用os.Exit()处理返回的状态码,如果不为0,说明有用例失败。 - 因此可以在调用
m.Run()前后做一些额外的准备(setup)和回收(teardown)工作。
执行 go test,将会输出
$ go test
Before all tests
I'm test1
I'm test2
PASS
After all tests
ok example 0.006s
TCP/HTTP
假设需要测试某个 API 接口的 handler 能够正常工作,例如 helloHandler
func helloHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hello world"))
}
那我们可以创建真实的网络连接进行测试:
// test code
import (
"io/ioutil"
"net"
"net/http"
"testing"
)
func handleError(t *testing.T, err error) {
t.Helper()
if err != nil {
t.Fatal("failed", err)
}
}
func TestConn(t *testing.T) {
ln, err := net.Listen("tcp", "127.0.0.1:0")
handleError(t, err)
defer ln.Close()
http.HandleFunc("/hello", helloHandler)
go http.Serve(ln, nil)
resp, err := http.Get("http://" + ln.Addr().String() + "/hello")
handleError(t, err)
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
handleError(t, err)
if string(body) != "hello world" {
t.Fatal("expected hello world, but got", string(body))
}
}
net.Listen("tcp", "127.0.0.1:0"):监听一个未被占用的端口,并返回 Listener。- 调用
http.Serve(ln, nil)启动 http 服务。 - 使用
http.Get发起一个 Get 请求,检查返回值是否正确。 - 尽量不对
http和net库使用 mock,这样可以覆盖较为真实的场景。
httptest
针对 http 开发的场景,使用标准库 net/http/httptest 进行测试更为高效。
上述的测试用例改写如下:
// test code
import (
"io/ioutil"
"net/http"
"net/http/httptest"
"testing"
)
func TestConn(t *testing.T) {
req := httptest.NewRequest("GET", "http://example.com/foo", nil)
w := httptest.NewRecorder()
helloHandler(w, req)
bytes, _ := ioutil.ReadAll(w.Result().Body)
if string(bytes) != "hello world" {
t.Fatal("expected hello world, but got", string(bytes))
}
}
使用 httptest 模拟请求对象(req)和响应对象(w),达到了相同的目的。
Benchmark 基准测试
基准测试用例的定义如下:
func BenchmarkName(b *testing.B){
// ...
}
- 函数名必须以
Benchmark开头,后面一般跟待测试的函数名 - 参数为
b *testing.B。 - 执行基准测试时,需要添加
-bench参数。
例如:
func BenchmarkHello(b *testing.B) {
for i := 0; i < b.N; i++ {
fmt.Sprintf("hello")
}
}
$ go test -benchmem -bench .
...
BenchmarkHello-16 15991854 71.6 ns/op 5 B/op 1 allocs/op
...
基准测试报告每一列值对应的含义如下:
type BenchmarkResult struct {
N int // 迭代次数
T time.Duration // 基准测试花费的时间
Bytes int64 // 一次迭代处理的字节数
MemAllocs uint64 // 总的分配内存的次数
MemBytes uint64 // 总的分配内存的字节数
}
如果在运行前基准测试需要一些耗时的配置,则可以使用 b.ResetTimer() 先重置定时器,例如:
func BenchmarkHello(b *testing.B) {
... // 耗时操作
b.ResetTimer()
for i := 0; i < b.N; i++ {
fmt.Sprintf("hello")
}
}
使用 RunParallel 测试并发性能
func BenchmarkParallel(b *testing.B) {
templ := template.Must(template.New("test").Parse("Hello, {{.}}!"))
b.RunParallel(func(pb *testing.PB) {
var buf bytes.Buffer
for pb.Next() {
// 所有 goroutine 一起,循环一共执行 b.N 次
buf.Reset()
templ.Execute(&buf, "World")
}
})
}
测试如下:
$ go test -benchmem -bench .
...
BenchmarkParallel-16 3325430 375 ns/op 272 B/op 8 allocs/op