ToC
- 前言
- 准备环境
- 开始?
ass_read_fileparse_memoryprocess_textprocess_lineprocess_info_lineprocess_styles_lineprocess_styleprocess_events_lineprocess_event_tailprocess_fonts_line- 结语
- 参考
前言
事先说明,这次阅读会跳过一些没有意义的函数,不会像上次 kara-templater 那样面面俱到了。因为 kara-templater 是 lua,而 libass 是 C。对于 lua 而言,很多东西已经极度简化了,因此都看不会显得特别多余;但对于 C 而言,有些东西讲了就有点啰嗦了,比如一些和系统相关、内存分配相关的细节等等,这个系列就跳过了(
准备环境
首先我们来看如何配置 libass 的环境。因为我们并不是要参与实际开发,因此我们希望配置的是能够使编辑器能够激活 IntelliSense 的环境。
我们知道libass 使用的是 GNU Automake,而这个工具链目前并没有被 CLion 兼容[1],因此我们要在别的方向上想办法。幸运的是,我们找到了 CLion 兼容 Makefile 的方案[2][3],这使得我们可以通过兼容 Make 的方式达到自动补全的目的。
以下为具体操作步骤:
1. 将仓库克隆到本地
git clone https://github.com/libass/libass.git
2. 运行仓库根目录下的 autogen.sh
chmod +x ./autogen.sh # 或许需要
./autogen.sh
3. 配置
./configure
经过这一步,在下一步进入的目录中,我们就有 Makefile 了。
4. 进入源码目录(./libass)
cd libass
5. 安装兼容工具
按照上面两篇文章的介绍,我们需要安装 compiledb:
pip install compiledb # You may need sudo
6. 生成 compile_commands.json
compiledb -n make
7. 使用 CLion 打开 **libass/libass** 目录
这里值得注意的是,要打开的目录是 libass 仓库下的 libass 子目录,也就是之前我们执行进入的目录,而不是仓库的根目录。在导入的时候应该也有提示,这个子目录能够被 CLion 识别(指图标):
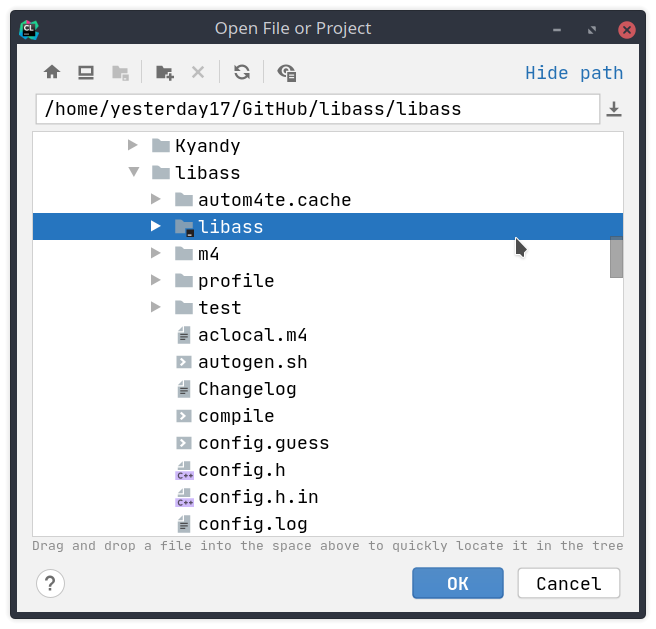
至此,我们的开发(阅读)环境就搭建完成了。
如果需要验证是否搭建成功的话,我们可以试一下外部库的跳转。来到 ass_render.c 的第 52 行,这里出现了 FT_Init_FreeType 这个函数。这个函数定义于 freetype.h 中,属于 freetype2 的内容,在 ArchLinux Packages 中也能看到[4]:
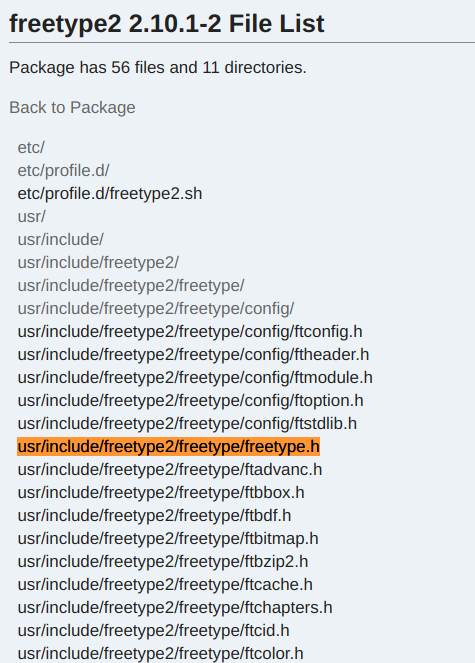
如果这个函数能够成功识别,代表 CLion 已经能够完全实现这个仓库的 IntelliSense 了。
开始?
我们知道libass 作为一个 lib 看上去并没有明显的入口,这时候就需要 test 登场了。
在 clone 下来的仓库里,我们看到有一个 test 目录,里面只有一个 test.c(如果你按照上述的步骤配置了的话,应该还有一些 Makefile):

我们打开来看:
int main(int argc, char *argv[])
{
const int frame_w = 1280;
const int frame_h = 720;
if (argc < 4) {
printf("usage: %s <image file> <subtitle file> <time>\n", argv[0]);
exit(1);
}
char *imgfile = argv[1];
char *subfile = argv[2];
double tm = strtod(argv[3], 0);
print_font_providers(ass_library);
init(frame_w, frame_h);
ASS_Track *track = ass_read_file(ass_library, subfile, NULL);
if (!track) {
printf("track init failed!\n");
return 1;
}
ASS_Image *img =
ass_render_frame(ass_renderer, track, (int) (tm * 1000), NULL);
image_t *frame = gen_image(frame_w, frame_h);
blend(frame, img);
ass_free_track(track);
ass_renderer_done(ass_renderer);
ass_library_done(ass_library);
write_png(imgfile, frame);
free(frame->buffer);
free(frame);
return 0;
}
这个例子是使用 libass 和 libpng 将某一帧渲染为 PNG 图片的示例。main 函数从第 192 行开始,而对我们来说重要的是第 208 行,也就是上面高亮的一行。我们想要的入口就在这儿了。
ass_read_file
/**
* \brief Read subtitles from file.
* \param library libass library object
* \param fname file name
* \param codepage recode buffer contents from given codepage
* \return newly allocated track
*/
ASS_Track *ass_read_file(ASS_Library *library, char *fname,
char *codepage)
{
char *buf;
ASS_Track *track;
size_t bufsize;
buf = read_file_recode(library, fname, codepage, &bufsize);
if (!buf)
return 0;
track = parse_memory(library, buf);
free(buf);
if (!track)
return 0;
track->name = strdup(fname);
ass_msg(library, MSGL_INFO,
"Added subtitle file: '%s' (%d styles, %d events)",
fname, track->n_styles, track->n_events);
return track;
}
先从整个函数的参数看起吧。首先是 ASS_Library *library,这个是负责维护全局状态的存在,最典型的例子就是字体;然后是 char *fname,顾名思义是文件名;最后是 char *codepage,这个初看有点不明所以,但其实对应是 iconv_open 中的第二个参数[5],对应文件的打开编码,负责将 codename 编码的文件转化为 UTF-8,当且仅当设置中启用了 iconv 时才生效。
当然了,这些全部都是细节,包括下面的 ass_msg 之类的,并没有了解的意义(除非我们希望贡献代码)。我们看到整个函数最重要的一行,也就是高亮的一行。
可以发现,在这一行之前,函数读入了字幕文件;在这一行之后,函数就纯粹地记录了文件名、日志之后就返回了。我们跟进去看。
parse_memory
/*
* \param buf pointer to subtitle text in utf-8
*/
static ASS_Track *parse_memory(ASS_Library *library, char *buf)
{
ASS_Track *track;
int i;
track = ass_new_track(library);
// process header
process_text(track, buf);
// external SSA/ASS subs does not have ReadOrder field
for (i = 0; i < track->n_events; ++i)
track->events[i].ReadOrder = i;
if (track->track_type == TRACK_TYPE_UNKNOWN) {
ass_free_track(track);
return 0;
}
ass_process_force_style(track);
return track;
}
我们知道,这里所指的 parse_menory 中的 memory 对应的其实就是读入的 ass 文件在内存中的表示,因此这个函数的本质就是解析字幕文件并生成 ASS_Track。
同样是只看重点,我们这里变换一下顺序。先看高亮的第二行,也就是第 1124 行。我们可以发现,libass 规定了一个 ReadOrder 属性。这个属性和 Event 的下标是一一对应的,其实就是相当于行号的存在。
然后是高亮的第三行,也就是第 1131 行。这里提供的功能实际是一些全局属性的覆盖,从 library 中覆盖解析文件的结果。由于这里的实现和高亮第一行本质上并没有什么区别,因此这里也就跳过了。我们来着重看高亮三行的第一行。
最后,我们看到高亮三行中的第一行,它是整个解析过程的核心,也是这篇的核心。
process_text
static int process_text(ASS_Track *track, char *str)
{
char *p = str;
while (1) {
char *q;
while (1) {
if ((*p == '\r') || (*p == '\n'))
++p;
else if (p[0] == '\xef' && p[1] == '\xbb' && p[2] == '\xbf')
p += 3; // U+FFFE (BOM)
else
break;
}
for (q = p; ((*q != '\0') && (*q != '\r') && (*q != '\n')); ++q) {
};
if (q == p)
break;
if (*q != '\0')
*(q++) = '\0';
process_line(track, p);
if (*q == '\0')
break;
p = q;
}
// there is no explicit end-of-font marker in ssa/ass
if (track->parser_priv->fontname)
decode_font(track);
return 0;
}
我们看到,从第 806 行开始的这个循环其实就是整个函数的核心。第 808-815 行过滤了所有的换行和 EF BB BF,最后这个是 UTF-8 的字节顺序标记[6],因为有些编辑器会生成这三个字节,因此同样也需要过滤。
接下来的 816-817 行的空循环负责的是寻找这一行的结尾。现在我们已经确定了 p 是这一行的开头,而中间只要没有 \n、\r 和 \0,就代表这一行没有结束(其中 \0 代表的是文件结束,因为 ASS 是文本文件)。
当 p、q 相同时,代表已经到达了文件的末尾。这里需要我们注意的是:p 一定不是 \r 或 \n,因此当 p == q 时,代表的就是 q == '\0',而文本文件中的 \0 就代表着文件的结束。
下一步是将当前 q 代表的位置为 \0,这里同样有值得注意的地方:当符合判断条件时,q 一定是 \r 或 \n。因此将 q 置为 \0,这样一来,读取这行内容的时候就可以以该行的末尾作为字符串的末尾了。最后将 q 自增,并在下面赋给原本的 p,开启下一轮循环,即下一行的解析。
最后,也就是第 829 行,负责的是可能存在的最后一个字体文件的解析。我们知道ASS 是支持内嵌二进制文件的,而 libass 唯一支持的就是字体。由于字体行的特殊性(下面也会提到),最后我们无法确定一行字体是不是被解析完了。又因为 ASS 没有标识文件结束的符号,因此在这里我们进行一次显式字体处理的尝试。如果 fontname 存在,也就是说还有没有处理的字体,就尝试进行一次字体解析。
process_line
/**
* \brief Parse a header line
* \param track track
* \param str string to parse, zero-terminated
*/
static int process_line(ASS_Track *track, char *str)
{
if (!ass_strncasecmp(str, "[Script Info]", 13)) {
track->parser_priv->state = PST_INFO;
} else if (!ass_strncasecmp(str, "[V4 Styles]", 11)) {
track->parser_priv->state = PST_STYLES;
track->track_type = TRACK_TYPE_SSA;
} else if (!ass_strncasecmp(str, "[V4+ Styles]", 12)) {
track->parser_priv->state = PST_STYLES;
track->track_type = TRACK_TYPE_ASS;
} else if (!ass_strncasecmp(str, "[Events]", 8)) {
track->parser_priv->state = PST_EVENTS;
} else if (!ass_strncasecmp(str, "[Fonts]", 7)) {
track->parser_priv->state = PST_FONTS;
} else {
switch (track->parser_priv->state) {
case PST_INFO:
process_info_line(track, str);
break;
case PST_STYLES:
process_styles_line(track, str);
break;
case PST_EVENTS:
process_events_line(track, str);
break;
case PST_FONTS:
process_fonts_line(track, str);
break;
default:
break;
}
}
return 0;
}
这里其实就是一个简单的状态分类和判断,说它是状态机甚至有点高看它了(
这里用到了一个简单的小函数:ass_strncasecmp,它的用途是比较两个字符串,忽略大小写,比较的长度就是第三个参数。
这里的 parser_priv 其实有点误导的感觉,但其实也没什么毛病。按照我的理解,这里应该是 current_parser 的意思(
这里有点意思的是关于 [V4 Styles] 和 [V4+ Styles] 的判断,匹配到任意一个的时候,它就会将 track 的 track_type 覆盖一遍。因此对于究竟是 SSA 还是 ASS,看的是谁笑到最后(
接下来我们一个一个看。
process_info_line
static int process_info_line(ASS_Track *track, char *str)
{
if (!strncmp(str, "PlayResX:", 9)) {
track->PlayResX = atoi(str + 9);
} else if (!strncmp(str, "PlayResY:", 9)) {
track->PlayResY = atoi(str + 9);
} else if (!strncmp(str, "Timer:", 6)) {
track->Timer = ass_atof(str + 6);
} else if (!strncmp(str, "WrapStyle:", 10)) {
track->WrapStyle = atoi(str + 10);
} else if (!strncmp(str, "ScaledBorderAndShadow:", 22)) {
track->ScaledBorderAndShadow = parse_bool(str + 22);
} else if (!strncmp(str, "Kerning:", 8)) {
track->Kerning = parse_bool(str + 8);
} else if (!strncmp(str, "YCbCr Matrix:", 13)) {
track->YCbCrMatrix = parse_ycbcr_matrix(str + 13);
} else if (!strncmp(str, "Language:", 9)) {
char *p = str + 9;
while (*p && ass_isspace(*p)) p++;
free(track->Language);
track->Language = strndup(p, 2);
}
return 0;
}
顾名思义,这里解析的是 [Script Info] 的内容。对于 libass 而言,需要的只有下面这些:
PlayResX:视频宽度PlayResY:视频高度Timer:时间轴计时器。但libass并没有用到这个参数。WrapStyle:字幕过长时的换行方式ScaledBorderAndShadow:字幕边框宽度和阴影深度是否要随着视频分辨率的改变而缩放Kerning:字距调整。对于某些特殊语言进行的字距优化。YCbCr Matrix:色彩空间。Language:字幕的语言。针对某些特殊语言,libass有特殊的shaper,简单理解为渲染优化即可。此处接收ISO 639-1格式[7]的双字母语言代号。
当解析完成后,所有的这些数据都会被存储到 track 中。
process_styles_line
static int process_styles_line(ASS_Track *track, char *str)
{
if (!strncmp(str, "Format:", 7)) {
char *p = str + 7;
skip_spaces(&p);
free(track->style_format);
track->style_format = strdup(p);
ass_msg(track->library, MSGL_DBG2, "Style format: %s",
track->style_format);
} else if (!strncmp(str, "Style:", 6)) {
char *p = str + 6;
skip_spaces(&p);
process_style(track, p);
}
return 0;
}
这里分了两种情况进行解析:Format 行和 Style 行。对于 Format 行,它将 Format: 之后所有的字符都复制到了 style_format 中;对于 Style 行,我们接着往下看:
process_style
对于 ASS 格式的文件,我们必须清楚的一点就是它的本质。
ASS 的本质其实就是 CSV,在清楚了这一点之后我们才能明白 Format 行和 Style 行,包括之后的行之间存在列的对应关系。
在了解了这个大前提之后,我们再来看 Style 行的处理。
默认:格式行
首先就是函数的开始:
/**
* \brief Parse the Style line
* \param track track
* \param str string to parse, zero-terminated
* Allocates a new style struct.
*/
static int process_style(ASS_Track *track, char *str)
{
char *token;
char *tname;
char *p = str;
char *format;
char *q; // format scanning pointer
int sid;
ASS_Style *style;
ASS_Style *target;
if (!track->style_format) {
// no style format header
// probably an ancient script version
if (track->track_type == TRACK_TYPE_SSA)
track->style_format =
strdup
("Name, Fontname, Fontsize, PrimaryColour, SecondaryColour,"
"TertiaryColour, BackColour, Bold, Italic, BorderStyle, Outline,"
"Shadow, Alignment, MarginL, MarginR, MarginV, AlphaLevel, Encoding");
else
track->style_format =
strdup
("Name, Fontname, Fontsize, PrimaryColour, SecondaryColour,"
"OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut,"
"ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow,"
"Alignment, MarginL, MarginR, MarginV, Encoding");
}
q = format = strdup(track->style_format);
// Add default style first
if (track->n_styles == 0) {
// will be used if track does not contain a default style (or even does not contain styles at all)
int sid = ass_alloc_style(track);
set_default_style(&track->styles[sid]);
track->default_style = sid;
}
ass_msg(track->library, MSGL_V, "[%p] Style: %s", track, str);
这里处理的是最基本的初始化,以及不存在 Format 行的特殊情况。可以看到,为了之后的解析,Format 行是必须要有的,因此这里就规定了一个默认值。
注意高亮的几行。现在我们有了这几个局部变量:
p:Style行去掉Style:之后的字符串。q:Format行字符串的复制。
带着这两个重要的局部变量,我们接着往下看。
宏定义:简化匹配过程
在 Format 与内容行匹配对应的过程中,广泛使用到的就是宏定义了。这里就简单介绍一下后面用到的宏好了。
值得注意的是,这些宏都是在循环中使用的。
NEXT
#define NEXT(str,token) \
token = next_token(&str); \
if (!token) break;
NEXT 的功能是从字符串中读出一个 token。token 是以 ,(英文逗号)或 \0 结尾的,去除了首尾空格的字符串。当读不出 token 时,直接 break 跳出循环。
PARSE_START、PARSE_END
#define PARSE_START if (0) {
#define PARSE_END }
PARSE_START 的本质是开始了一个 if 语句。但由于我们无法知道之后究竟会满足哪一个分支,因此这里以一个必假的分支选择语句开场,真正的选择判断交给其他宏来完成。
有始就有终,为了让代码更加易读,我们又追加了 PARSE_END 来替代闭合大括号。
ANYVAL
#define ANYVAL(name,func) \
} else if (ass_strcasecmp(tname, #name) == 0) { \
target->name = func(token);
这里定义了一个供其他宏使用的宏,在 tname 与名称相同时,调用对应的 func 处理 token。
STARREDSTARVAL
#define STARREDSTRVAL(name) \
} else if (ass_strcasecmp(tname, #name) == 0) { \
if (target->name != NULL) free(target->name); \
while (*token == '*') ++token; \
target->name = strdup(token);
这里使用的是一种特殊的字符串匹配方案:忽略首部的星号(*)。具体为什么要忽略星号我暂且蒙在鼓里,但是从测试的结果来看,忽略星号对 libass 和 VSFilterMod 都是存在的。也就是说,这是一个相对“规范”的现象,只是我没有找到原因罢了。
如果有知道原因的读者
STRVAL
#define STRVAL(name) \
} else if (ass_strcasecmp(tname, #name) == 0) { \
if (target->name != NULL) free(target->name); \
target->name = strdup(token);
这就是上面去掉 * 忽略的产物了。非常简单,就不多说了。
COLORVAL
#define COLORVAL(name) ANYVAL(name,parse_color_header)
可以看到,这里的本质是 parse_color_header。这个函数属于工具函数(位于 ass_utils.c 内),所以我们这里就不展开了。只要知道它返回了一个 uint32_t 的颜色就可以了。
FPVAL、INTVAL、
#define FPVAL(name) ANYVAL(name,ass_atof)
这就顾名思义了,FP 也就是浮点数,对应的是读取浮点数内容。
#define INTVAL(name) ANYVAL(name,atoi)
当然了,INT 也是同理。
开始:正式解析
sid = ass_alloc_style(track);
style = track->styles + sid;
target = style;
// fill style with some default values
style->ScaleX = 100.;
style->ScaleY = 100.;
while (1) {
NEXT(q, tname);
NEXT(p, token);
PARSE_START
STARREDSTRVAL(Name)
if (strcmp(target->Name, "Default") == 0)
track->default_style = sid;
STRVAL(FontName)
COLORVAL(PrimaryColour)
COLORVAL(SecondaryColour)
COLORVAL(OutlineColour) // TertiaryColor
COLORVAL(BackColour)
// SSA uses BackColour for both outline and shadow
// this will destroy SSA's TertiaryColour, but i'm not going to use it anyway
if (track->track_type == TRACK_TYPE_SSA)
target->OutlineColour = target->BackColour;
FPVAL(FontSize)
INTVAL(Bold)
INTVAL(Italic)
INTVAL(Underline)
INTVAL(StrikeOut)
FPVAL(Spacing)
FPVAL(Angle)
INTVAL(BorderStyle)
INTVAL(Alignment)
if (track->track_type == TRACK_TYPE_ASS)
target->Alignment = numpad2align(target->Alignment);
// VSFilter compatibility
else if (target->Alignment == 8)
target->Alignment = 3;
else if (target->Alignment == 4)
target->Alignment = 11;
INTVAL(MarginL)
INTVAL(MarginR)
INTVAL(MarginV)
INTVAL(Encoding)
FPVAL(ScaleX)
FPVAL(ScaleY)
FPVAL(Outline)
FPVAL(Shadow)
PARSE_END
}
在了解了上面定义的这些宏之后,接下来的匹配过程也就非常清楚了。相比与简单的宏调用,唯一增加的就是默认样式的选定、SSA 的兼容以及小键盘对齐格式到数字对齐格式的变换。
这里读者如果有兴趣可以去读一读 numpad2align 这个函数,它提供了我们现在使用的小键盘对齐格式到真正被用于渲染的对齐之间的数字转换,简单来说就是将人类容易记住的格式转化为位运算的格式。
最后:规整与统一
style->ScaleX = FFMAX(style->ScaleX, 0.) / 100.;
style->ScaleY = FFMAX(style->ScaleY, 0.) / 100.;
style->Spacing = FFMAX(style->Spacing, 0.);
style->Outline = FFMAX(style->Outline, 0.);
style->Shadow = FFMAX(style->Shadow, 0.);
style->Bold = !!style->Bold;
style->Italic = !!style->Italic;
style->Underline = !!style->Underline;
style->StrikeOut = !!style->StrikeOut;
if (!style->Name)
style->Name = strdup("Default");
if (!style->FontName)
style->FontName = strdup("Arial");
free(format);
return 0;
}
最后的步骤就是将数值规范了。首先是 Scale,其真正需要用到的并不是百分制的数字,而是浮点数,因此在这里进行转化;其次是字距之类的属性,其需要的数值一定是大于等于 0 的,因此在这里通过 FFMAX 宏,也就是取 max 的操作进行修正;最后是样式名称和字体名称,当二者不存在时,我们需要指定一个。默认样式名称我们就指定 Default,而默认字体则为 Arial。
最后,还记得我们上面的 format 吗?format 是通过 strdup 函数生成的,因此这里我们也需要释放这一段内存。
至此,整个过程完美结束,返回 0。
process_events_line
static int process_events_line(ASS_Track *track, char *str)
{
if (!strncmp(str, "Format:", 7)) {
char *p = str + 7;
skip_spaces(&p);
free(track->event_format);
track->event_format = strdup(p);
ass_msg(track->library, MSGL_DBG2, "Event format: %s", track->event_format);
} else if (!strncmp(str, "Dialogue:", 9)) {
// This should never be reached for embedded subtitles.
// They have slightly different format and are parsed in ass_process_chunk,
// called directly from demuxer
int eid;
ASS_Event *event;
str += 9;
skip_spaces(&str);
eid = ass_alloc_event(track);
event = track->events + eid;
// We can't parse events with event_format
if (!track->event_format)
event_format_fallback(track);
process_event_tail(track, event, str, 0);
} else {
ass_msg(track->library, MSGL_V, "Not understood: '%.30s'", str);
}
return 0;
}
有了之前解析 Style 行的经验,这次可以算是轻车熟路了。首先仍然是 Format 行,这里略过;然后是 Dialogue 行,在一切都准备妥当之后,我们调用了 process_event_tail。
这里有件有趣的事情:看第 653 行的注释,其实这里应该是 without 而不是 with(笑)
最后,对于即不是 Format 又不是 Dialogue 的行,其被 libass 忽略。最常见的这种行也就是我们熟悉的 Comment 行了吧(
好,来看 process_event_tail。
process_event_tail
准备:开始之前
/**
* \brief Parse the tail of Dialogue line
* \param track track
* \param event parsed data goes here
* \param str string to parse, zero-terminated
* \param n_ignored number of format options to skip at the beginning
*/
static int process_event_tail(ASS_Track *track, ASS_Event *event,
char *str, int n_ignored)
{
char *token;
char *tname;
char *p = str;
int i;
ASS_Event *target = event;
char *format = strdup(track->event_format);
char *q = format; // format scanning pointer
if (track->n_styles == 0) {
// add "Default" style to the end
// will be used if track does not contain a default style (or even does not contain styles at all)
int sid = ass_alloc_style(track);
set_default_style(&track->styles[sid]);
track->default_style = sid;
}
for (i = 0; i < n_ignored; ++i) {
NEXT(q, tname);
}
到这里为止都是初始化的过程。我们规定了没有样式时的默认样式,并且根据传入的 n_ignored 参数跳过了 n 个 token。
宏定义:补充内容
ALIAS
#define ALIAS(alias,name) \
if (ass_strcasecmp(tname, #alias) == 0) {tname = #name;}
ALIAS 的作用是将 alias 替换成 name 的值。也就是说,经过 ALIAS 后,如果 tname 与 alias 一致,那么 tname 就会被替换成 name。
TIMEVAL
#define TIMEVAL(name) \
} else if (ass_strcasecmp(tname, #name) == 0) { \
target->name = string2timecode(track->library, token);
顾名思义,这是解析时间信息的。时间信息的基本格式是 h:m:s.ms,最终胡ibei解析成 long long 类型的 timestamp。
开始:正式解析
while (1) {
NEXT(q, tname);
if (ass_strcasecmp(tname, "Text") == 0) {
char *last;
event->Text = strdup(p);
if (*event->Text != 0) {
last = event->Text + strlen(event->Text) - 1;
if (last >= event->Text && *last == '\r')
*last = 0;
}
event->Duration -= event->Start;
free(format);
return 0; // "Text" is always the last
}
NEXT(p, token);
ALIAS(End, Duration) // temporarily store end timecode in event->Duration
PARSE_START
INTVAL(Layer)
STYLEVAL(Style)
STRVAL(Name)
STRVAL(Effect)
INTVAL(MarginL)
INTVAL(MarginR)
INTVAL(MarginV)
TIMEVAL(Start)
TIMEVAL(Duration)
PARSE_END
}
接下来就是 Dialogue 行的正式解析了。首先,我们需要知道,Text 一定是一个 Dialogue 行的结尾。因此,在这个前提下,我们就需要对 Text 进行特别处理,也就是高亮的 344 行。这里,我们计算出 Duration,并且返回 0,表示该行解析成功。
当这一列不是 Text 时,我们就需要和 Style 一样解析了。这里我们用到了 ALIAS 宏,将 End 信息暂时存储在 Duration 里,这样我们就可以在最后通过直接减去 Start 来获取 Duration 的真实值了。之后的解析也就和 Style 的解析没什么区别了。
结束:返回
free(format);
return 1;
}
如果函数进行到了这里,不难发现,我们完全没有找到 Text 列的存在。因此这样的行是不完整的,我们返回 1 表示解析出现了问题。
至此,Dialogue 行解析完成。Event 部分也就解析完了。
process_fonts_line
static int process_fonts_line(ASS_Track *track, char *str)
{
int len;
if (!strncmp(str, "fontname:", 9)) {
char *p = str + 9;
skip_spaces(&p);
if (track->parser_priv->fontname) {
decode_font(track);
}
track->parser_priv->fontname = strdup(p);
ass_msg(track->library, MSGL_V, "Fontname: %s",
track->parser_priv->fontname);
return 0;
}
if (!track->parser_priv->fontname) {
ass_msg(track->library, MSGL_V, "Not understood: '%s'", str);
return 0;
}
len = strlen(str);
if (track->parser_priv->fontdata_used + len >
track->parser_priv->fontdata_size) {
track->parser_priv->fontdata_size += FFMAX(len, 100 * 1024);
track->parser_priv->fontdata =
realloc(track->parser_priv->fontdata,
track->parser_priv->fontdata_size);
}
memcpy(track->parser_priv->fontdata + track->parser_priv->fontdata_used,
str, len);
track->parser_priv->fontdata_used += len;
return 0;
}
最后是字体解析的过程。和其他行不同,字体本质上是经过编码的二进制数据,因此需要特殊处理。
字体部分没什么好讲的,看看就好(笑)
结语
到这篇文章为止,我们初步了解了 libass 中解析字幕文件的过程,而 ASS 文件也已经被整理成格式规整的内存中数据了。
接下来就是解析标签、渲染之类的过程了,但那就是下一篇文章的故事了(笑)
本文写的仓促,纵使经过复数次检查但还是很有可能有所疏漏,还请
最后,在 2021-01-20 补充一点,本文写作时的 commit 如 [8] 所示,因此读者如果想要对照着源码阅读,请找到正确的分支(
参考
- https://youtrack.jetbrains.com/issue/CPP-193
- https://blog.jetbrains.com/clion/2018/08/working-with-makefiles-in-clion-using-compilation-db/
- https://www.jetbrains.com/help/clion/managing-makefile-projects.html
- https://www.archlinux.org/packages/extra/x86_64/freetype2/files/
- https://www.gnu.org/software/libiconv/documentation/libiconv-1.13/iconv_open.3.html
- https://en.wikipedia.org/wiki/Byte_order_mark
- https://zh.wikipedia.org/wiki/ISO_639-1%E4%BB%A3%E7%A0%81%E8%A1%A8
- https://github.com/libass/libass/tree/e5140624ff739c3157929bc5e1a1007cdc9cdaa8