非常感谢我的导师张梦豪教授与他的研究生张觉学长,我得以第一次接触科研。
学长给我的第一个任务是建立起基础知识架构以及阅读NSDI_26_CAVER这篇论文。这篇文章记录我的收获。
张觉学长抛给了我以下的问题:
网络七层协议每层都大概在干什么(主要看网络层与传输层)
TCP/IP技术 以及RDMA技术的基本内容与对比,RDMA与TCP/IP相比,新增了什么约束,获得了什么收益?
RoCEv2是什么?
无损网络:PFC or 信用流控,是什么约束导致我们要引入无损网络,无损网络会带来什么问题?了解Go-Back-N,选择性重传,乱序重排的概念
拥塞控制(congestion control)和负载均衡(load balance)在做什么?
数据中心内部网络通信,与广域网之间的网络通信,有什么不同?数据中心网络一个典型的拓扑是什么样的?
逐流负载均衡和逐包负载均衡的概念,为什么要区分出这两种概念?
ECMP/逐包喷洒是什么?
交换机内部,入队列/出队列的概念,报文在里面大概怎么流转的?
这里面有的概念我接触过,有的听说过,有的还是新名词。我将逐个学习。
知识架构构建
网络七层协议与TCP/IP
计算机网络通信是分层设计的,OSI(Open System Interconnect)模型将网络通信分为七层,即应用层,表示层,会话层,传输层,网络层,数据链路层,物理层。每一层对上方的层次提供封装好的标准接口。
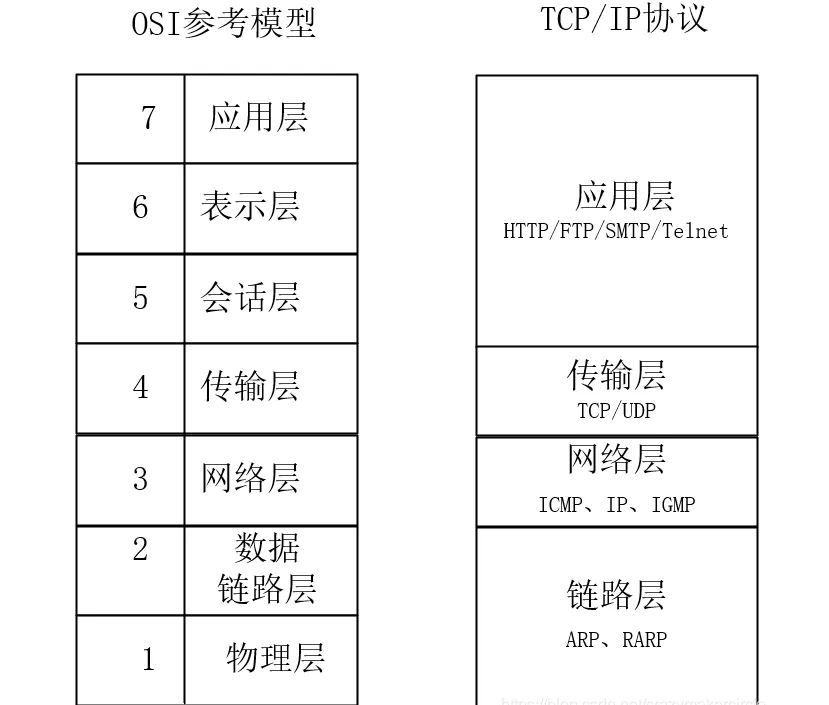
显然我之前的接触更多是在7层应用层以及5层的会话层(SSL加密),对于4层传输层的知识限于TCP与UDP的区别。
我现在需要研究的是第四层第三层的传输层与网络层。
传输层为应用程序提供端到端的数据传输服务,负责数据的分段、传输控制、错误恢复和流量控制。它主要使用 TCP(传输控制协议)和 UDP(用户数据报协议)来实现这些功能。
这层的功能包括是否选择差错恢复协议还是无差错恢复协议,及在同一主机上对不同应用的数据流的输入进行复用,还包括对收到的顺序不对的数据包的重新排序功能。示例:TCP,UDP。这一层的数据单元也称作数据包(packets)。但是,当谈论TCP等具体的协议时又有特殊的叫法,TCP的数据单元称为段 (segments)而UDP协议的数据单元称为“数据报(datagrams)”。
网络层(Network Layer):网络层负责数据包的路由和转发,以及网络中的寻址和拥塞控制。它选择最佳的路径来传输数据包,以确保它们能够从源主机到目标主机进行传输。
我在BGP线路优化与DN42那里听说过一点,我一直觉得能在通信相对底层的这个位置还能做到基于很多复杂策略的路径选择还是很神秘的。我要研究的CAVER: Enhancing RDMA Load Balancing by Hunting Less-Congested Paths应该也主要是在这方面做工作吧。在服务器上我会通过BBR调整传输速率来使传输带宽最大、传输延迟最低。而这篇论文看标题应该是通过测试多条链路,寻找最不拥塞的进行负载均衡。
关于TCP/IP,发现CSDN上这篇文章讲的很全面
RDMA
听过DMA (Direct Memory Access),允许外设(如网卡)不经过CPU直接访问内存,那这个加的R也就是remote的意思了。也就是使用智能网卡,一台主机可以绕过本机的CPU与内存直接使用远程的内存。
显然这对于网卡与网络的要求会很高,对于内存布局也有要求。
RDMA的优势在于:
CPU Offload(CPU Bypass)
无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU(这里面可能有歧义,应该还会通知CPU的)。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。Kernel Bypass
内核旁路指的是,应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。Zero Copy
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,在TCP/IP通信中,数据在主机之间的传输需要频繁进行拷贝操作(UserSpace Buffer、Socket Buffer、NIC Buffer),这些操作无疑增加了传输延迟。而RDMA具有零拷贝的特点。RDMA技术非常重要的一点是,每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。异步接口
在RDMA中,提供的所有接口都是异步的通信接口,这样在编程的时候,可以更加便利的实现计算和通信的分离。
RDMA通信协议
目前,有三种支持RDMA的通信技术:
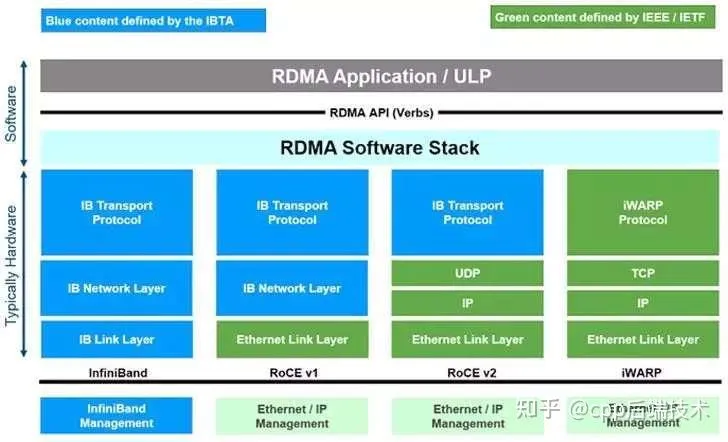
- IB(InfiniBand)
- 以太网RoCE(RDMA over Converged Ethernet)
- 以太网iWARP(internet Wide Area RDMA Protocal)。
这三种技术都可以使用同一套API来使用,但它们有着不同的物理层和链路层。
1. Ethernet(以太网)
是什么
一种二层网络技术标准(IEEE 802.3),定义了:
- 帧格式
- MAC 地址
- 介质访问方式
- 物理速率(1G / 10G / 100G / 400G …)
关键点
- 本质是 L2
- 默认是 尽力而为(Best Effort)
- 允许丢包
- 不保证延迟和带宽
在 RDMA 中
- iWARP / RoCE 都是跑在以太网上
- 但原生以太网并不适合 RDMA
这三者本质上都是 RDMA 技术体系,区别主要体现在底层网络、协议栈位置、对网络环境的要求以及部署复杂度。可以从「是不是专用网络」「是否依赖 TCP」「对以太网的约束」这几个维度来理解。
1. IB(InfiniBand)
定位
原生 RDMA 网络,从物理层到传输层都是为 RDMA 设计的。
关键特征
- 专用网络(非以太网)
- 自有协议栈(IB Link / Network / Transport)
- 硬件级可靠传输
- 极低延迟、极高带宽
- 不使用 TCP/IP
技术要点
- 可靠性由 IB 传输层保证(ACK、重传等都在 NIC 内完成)
- 支持 RC / UC / UD 等多种 Queue Pair 类型
- 网络天然无丢包设计
优缺点
优点
- 延迟最低
- 吞吐最高
- 语义最“纯粹”的 RDMA
缺点
- 成本高(交换机、网卡都专用)
- 与以太网生态不兼容
- 运维复杂
典型场景
- HPC(高性能计算)
- 超算集群
- 高端 AI 训练集群
2. RoCE(RDMA over Converged Ethernet)
定位
在以太网上跑的 RDMA,但仍然使用 IB 的传输语义。
分类(很重要)
- RoCE v1:二层(不可路由)
- RoCE v2:UDP/IP(三层,可路由)
关键特征
- 使用以太网物理层
- 不使用 TCP
- 对网络环境要求高(必须“近似无丢包”)
技术要点
- 传输层仍是 IB Transport
- RoCE v2 用 UDP + IP 封装
- 依赖 DCQCN / PFC / ECN 等机制避免丢包
优缺点
优点
- 使用以太网,成本低于 IB
- 延迟接近 IB
- 易与现有数据中心融合
缺点
- 对网络配置极其敏感
- PFC 可能引发拥塞扩散(Head-of-Line Blocking)
- 运维难度高
典型场景
- 云厂商数据中心
- AI 训练/推理集群
- 存储网络(如 NVMe-oF over RoCE)
3. iWARP(Internet Wide Area RDMA Protocol)
定位
跑在 TCP/IP 之上的 RDMA
关键特征
- 基于 TCP
- 完全兼容普通以太网
- 不需要无丢包网络
协议栈
1 | RDMA |
技术要点
- 可靠性、拥塞控制交给 TCP
- RDMA NIC 仍然支持零拷贝、内核旁路
- 延迟比 RoCE / IB 高
优缺点
优点
- 网络部署最简单
- 可跨三层网络、广域网
- 无需 PFC / ECN
缺点
- TCP 带来额外延迟
- 高速场景下吞吐不如 RoCE / IB
- 市场支持度低(主流厂商偏向 RoCE)
典型场景
- 跨机房
- 广域网 RDMA
- 对网络改造受限的环境
4. 核心差异对比表
| 维度 | InfiniBand | RoCE | iWARP |
|---|---|---|---|
| 底层网络 | 专用 IB | 以太网 | 以太网 |
| 是否 TCP | 否 | 否 | 是 |
| 是否需无丢包 | 是(天然) | 是(需配置) | 否 |
| 可路由性 | 是 | v1 否 / v2 是 | 是 |
| 延迟 | 最低 | 很低 | 较高 |
| 运维复杂度 | 高 | 很高 | 低 |
| 成本 | 最高 | 中 | 低 |
| 主流程度 | HPC 主流 | 数据中心主流 | 较小众 |
以上内容由AI生成,阅读过程中我看到了RoCE中的Converged Ethernet(融合以太网)的概念,不太理解,所以又让AI为我解释,最后可以归纳为在以太网上“融合”多种对网络质量要求很高的流量,让以太网接近无丢包,这样才符合RoCE对于网络的要求。
关于RDMA的细节,我主要学习了这篇文章
我将这一部分与AI的对话保存在了 https://chats.pengs.top/NSDI_26_CAVER/IB-RoCE-iWARP.html
RoCEv2
一、基础网络层面
广播域 / VLAN
- 广播域:二层广播可达的范围
- VLAN:人为划分的广播域边界
- 路由器 / 三层设备:切断广播域
- 问题:RoCEv1 是二层协议 → 只能在一个广播域内
RoCEv2 的动机
- 把 RDMA 从 L2 提升到 L3(IP/UDP)
- 解决不可路由、规模受限的问题
- 代价:进入“普通 IP 网络”,但不使用 TCP 的安全垫
二、RDMA / RoCE 核心语义
RDMA
绕过内核、零拷贝、NIC 直访内存
需要:
- 内存注册(pin)
- rkey / lkey
- 严格权限
QP(Queue Pair)
- Send Queue + Receive Queue
- RC 模式下:≈ 一条可靠连接
RC(Reliable Connection)
- 保证:不丢、不乱、不重
- 支持 one-sided(RDMA Read / Write / Atomic)
- 可靠性由 NIC 硬件实现
- 不具备 TCP 的拥塞控制能力
三、丢包与可靠性问题
QP 超时重传
丢包 / ACK 延迟 → NIC 重传
超过重试阈值 → QP 进入 ERROR
QP ERROR:
- 连接直接失效
- 必须重建
结论:
RC 极度厌恶丢包
四、为“避免丢包”引入的机制
PAUSE 帧(802.3x)
- 二层控制帧
- 暂停整个端口
- 粒度太粗
PFC(802.1Qbb)
- PAUSE 的升级版
- 按优先级暂停
- RDMA 单独优先级
- 目标:lossless Ethernet
ECN(IP 层)
- 不丢包
- 在拥塞时标记 IP 包
- 提前告知拥塞
DCQCN
- RoCEv2 的拥塞控制
- 基于 ECN
- NIC 内调节发送速率
分工总结:
- PFC:防止队列溢出
- ECN:感知拥塞
- DCQCN:降速
五、由 PFC 引出的系统性问题
Head-of-Line Blocking
- 同一优先级只有一个 FIFO 队列
- 队头被 Pause → 后续包全堵
- 尾延迟显著上升
拥塞传播
- 一个节点拥塞
- PFC Pause 反向逐跳传播
- 整条路径被冻结
死锁风险
- 多跳 + 环路
- 设备互相等待 Resume
- 网络进入永久停滞状态
因果链:
1 | PFC |
六、为什么说 RoCEv2 “牺牲了网络部署复杂度”
TCP 的哲学
- 丢包是常态
- 端系统自适应
- 网络可以很“粗糙”
RoCEv2 的哲学
- 丢包是灾难
- 可靠性在 NIC
- 网络必须高度可控
结果:
必须精细配置:
- PFC
- ECN 阈值
- DCQCN 参数
- QoS / 拓扑
运维难度显著上升
一句话总结:
RoCEv2 用“网络复杂性”换“极致性能”
七、终极对照(一句话版)
- RoCEv1:简单、不可路由
- RoCEv2:可扩展、难运维
- RC:快,但脆
- PFC:救命,但有副作用
- ECN / DCQCN:试图把系统拉回稳定区间
无损网络 PFC 信用流控 重传
核心问题
数据中心里,短时拥塞很常见;对 RDMA 这类对丢包/恢复很敏感的业务来说,丢包会把尾延迟放大。
于是出现两条路线:
- 尽量不丢(lossless / 近似无损):用链路层/交换机机制把包“按住”
- 允许丢但要优雅恢复(lossy + 拥塞控制 + 重传):让端侧更好地适应
流量为什么会突然堵住
微突发(microburst)
极短时间(微秒~毫秒级)内到达某个端口的瞬时速率 超过端口线速,队列一下被灌满。
典型诱因:
- 多个发送端“同步”地放量(应用层同步点、RPC fan-in)
- 交换机出端口速率瓶颈(多入一出)
- 发送端 pacing 不足、突发聚合
多发一收(incast)
多个发送端同时给一个接收端/同一出端口发,接收端口或交换机出端口成为瓶颈,常伴随微突发,是 microburst 的常见场景来源之一。
“无损网络”是什么,为啥要它
无损网络(lossless class)
不是全网“绝对不丢”,而是:对某个业务优先级(priority)尽量避免因队列溢出而丢包,让它走“快路径”,避免进入“重传/超时”的慢路径。
为什么 RDMA 更在意丢包
- 可靠/有序语义(比如 RC)下,丢包会触发恢复流程
- 端侧恢复(超时、重传、乱序处理)会明显放大尾延迟
- 数据中心微突发频繁 → 丢包并不罕见 → 性能不稳定
关键机制:流控与拥塞控制
PAUSE(以太网暂停帧)
最早的链路层暂停:让对端“别发了”。通常是整口暂停,粒度粗。
PFC(Priority Flow Control)
PAUSE 的升级版:按优先级暂停(某个 priority 暂停,别的还能发)。
特点:逐跳(hop-by-hop),靠阈值触发(队列快满就 pause,上游停发)。
信用流控(credit-based flow control)
更“精确”的逐跳流控:下游给上游发“还能收多少”的信用,上游按信用发。
在 IB 很典型;以太网生态里更多见的是 PFC。
(我感觉和令牌桶很像)
ECN(Explicit Congestion Notification)
拥塞标记而不是丢包:交换机在队列超过阈值时给包打标记,接收端把标记反馈给发送端,让发送端降速。
DCQCN(RoCE 常见)
一种结合 ECN 标记 + 端侧速率调节 的拥塞控制方案,用来减少队列增长、降低触发 PFC 的概率,避免“全网暂停”。
直觉:PFC 是“刹车”,ECN/DCQCN 是“提前松油门”。
无损网络带来的典型问题
HOL Blocking(队头阻塞)
同一队列/同一优先级里,前面的流被堵住,会把后面本来没问题的也一起拖住。
拥塞扩散(congestion spreading)
下游 pause 上游,上游排队又 pause 更上游,拥塞从局部扩散成更大范围的停顿。
死锁风险(deadlock)
多方向流互相占着缓冲,大家又被 PFC 暂停,可能形成循环等待(网络“僵住”)。
所以无损网络通常需要:队列隔离、合理阈值、拥塞控制(ECN/DCQCN)、以及小心的拓扑/路由与缓冲规划。
可靠传输的三个经典概念
Go-Back-N(回退 N 帧)
丢一个包,后面一串一起重传;实现简单但浪费带宽、延迟抖动大。
选择性重传(Selective Repeat / SACK 思想)
只重传丢的;需要乱序缓存与更复杂的确认信息。
乱序重排(reordering & reassembly)
包可能乱序到达,接收端需要缓存并按序交付;缓存不足会退化(丢/等待),缓存过大有成本与时延抖动。
有关这个主题的对话在 https://chats.pengs.top/NSDI_26_CAVER/Lossless-Network-and-Flow-Control.html
拥塞控制 负载均衡
这一部分其实还算熟悉
1) 拥塞控制在做什么
目标
当很多流同时争用同一段网络资源(交换机端口、链路带宽、缓冲区)时,避免:
- 队列越堆越长(时延/尾延迟飙升)
- 丢包/重传(吞吐下降、抖动)
- 拥塞扩散(congestion spreading):某处排队把上游也“拖慢”
一句话:让发送端“别把网打爆”,并在接近爆点时就主动降速。
关键思想
拥塞信号:网络用某种方式告诉端系统“我这儿要堵了”
- 丢包(最传统,但代价大)
- 显式标记(ECN)
- 速率/信用反馈(如某些数据中心机制)
端侧动作:发送端调速
- 调整窗口/速率(AIMD、基于速率的控制)
- 快速收敛到公平/稳定的点
经典例子
- TCP 拥塞控制:通过丢包/延迟/ECN 推断拥塞,调整 cwnd(窗口),实现“加性增、乘性减”等。
- 数据中心(尤其 RoCEv2):尽量不丢包,因为丢包+重传会导致尾延迟很差;因此常用 ECN 标记 + 端侧算法(例如 DCQCN/Timely/HPCC 类思路),做到“早反馈、早降速”。
前面学到的 PFC/PAUSE 更像“止血带”(链路级暂停,避免丢包),但它本身不是拥塞控制:它不解决“谁该降多少速”,还可能带来 HOL blocking 和死锁风险。真正的拥塞控制是“端到端(或至少端系统参与)的调速逻辑”。
2) 负载均衡在做什么
目标
当网络里有多条可用路径/多台后端可选时,让流量分散,避免:
- 某条链路/某台机器过载,而其他资源闲着
- 热点(hot spot)导致局部队列很长、抖动大
一句话:把“该走哪条路 / 发给哪台机器”的选择做得更均匀,减少热点。
两类常见负载均衡
A. 网络路径负载均衡(routing / ECMP 相关)
ECMP:多条等价路径,按哈希把“流”分配到某条路径上(通常按 5-tuple)。
- 优点:简单、无状态、交换机好实现
- 缺点:可能哈希不均匀,出现“碰撞”导致某条路径热、别的冷;对短流/突发也不灵
更激进的方案(思路上):按包/按小片段动态选路、或基于实时拥塞信息选路(更能躲开热点,但会带来乱序、实现复杂、对传输层要求更高)
B. 服务端负载均衡(L4/L7,把请求分配到后端实例)
- 典型就是把请求分到不同后端(轮询、最少连接、基于延迟/队列的策略等)。
- 这里的瓶颈不一定是链路,可能是 CPU、锁、磁盘、队列、连接数等。
3) 它俩的关系:互补但不等价
- 负载均衡解决“尽量别形成热点”,偏“路径/目的地选择问题”。
- 拥塞控制解决“热点已经形成或不可避免时,怎么稳定地共享资源”,偏“调速问题”。
只做负载均衡、不做拥塞控制:
- 热点仍可能出现(突发、哈希碰撞、业务相关性),队列会爆 → 丢包/延迟飙升。
只做拥塞控制、不做负载均衡:
- 网络会趋于稳定,但可能长期把很多流挤在同一条路径上,整体利用率/时延不如把流量分散开。
4) 放到你在学的 RoCEv2 / 数据中心语境里怎么理解
RoCEv2 追求低延迟和低 CPU 开销,但对丢包很敏感(重传会放大尾延迟)。
所以常见组合是:
- ECN:交换机队列到阈值就标记
- 端侧拥塞控制:收到标记就降速(例如 DCQCN 思路)
- 路径负载均衡(ECMP/更动态的选路):减少热点概率
- PFC:在某些部署里用于尽量避免丢包,但要小心 HOL/死锁/拥塞扩散
数据中心中的逐流 ECMP与逐包喷洒
数据中心内部网络通信(DCN):在同机房/园区内的高带宽、低时延、可控拓扑网络通信。
广域网(WAN):跨城市/跨国家的长距离网络通信,时延高且路径与中间设备更不可控。
数据中心拓扑(Leaf-Spine/Clos):一种用 Leaf(接入)与 Spine(骨干)构成的多路径结构,靠水平扩展提升带宽与规模。
Leaf(叶子交换机):连接服务器/机架并上联 Spine 的接入层交换机。
Spine(脊交换机):只连接各个 Leaf、提供骨干转发与多路径的汇聚层交换机。
ToR(Top-of-Rack):机架顶交换机,通常就是该机架的 Leaf/接入交换机。
Border/Edge(出口/边界设备):连接数据中心与外部网络(互联网、专线、其他机房)的路由/安全/策略边界。
BGP:一种路由协议,数据中心常用它在 underlay 或 EVPN 控制面中分发路由/主机可达信息。
IS-IS:一种链路状态路由协议,可用于数据中心 underlay 来计算最短路径并支持 ECMP。
eBGP:BGP 的“外部邻居”模式,数据中心常用 eBGP Clos 让拓扑与故障域更清晰。
iBGP:BGP 的“内部邻居”模式,通常在同一 AS 内分发路由(数据中心也可能用)。
路由可达性(reachability):网络中“能否找到到达目的地的下一跳”的能力,由路由协议提供。
ECMP(等价多路径):当存在多条等价下一跳时,用哈希把流量分摊到多条路径上的转发机制。
5-tuple(五元组):源/目的 IP、源/目的端口、协议等字段组合,常作为 ECMP 哈希的“流标识”。
流(flow):一组共享同一组关键头字段(如五元组)的数据包集合,通常被网络按同一条路径处理。
逐流负载均衡(per-flow LB):把同一条流固定映射到一条路径以避免乱序,但可能出现热点不均匀。
逐包负载均衡/逐包喷洒(per-packet spraying):把同一条流的包分散到多条路径以追求均匀,但更容易乱序。
Flowlet(按流突发切换):在流的突发间隙切换路径以兼顾均匀性与较低乱序风险的折中方案。
乱序(reordering):同一流的数据包因走不同路径时延不同而到达顺序被打乱的现象。
负载偏斜(hash imbalance):ECMP 哈希导致大量流或大象流集中在少数路径上而形成拥塞热点的现象。
尾延迟(tail latency):延迟分布的高分位(如 p99/p999)表现,常由拥塞、排队和重传放大。
MPLS:用标签转发并支持 VPN/流量工程的承载技术,常见于运营商和广域网。
SR(Segment Routing):把路径意图编码成段列表以实现更灵活的流量工程(如 SR-MPLS/SRv6)。
专线:具有明确带宽与 SLA 的专用链路服务,常用于站点/数据中心互联(DCI)。
Underlay(底层网络):物理三层 IP 网络(Leaf-Spine + 路由协议 + ECMP),负责真实转发与可达性。
Overlay(叠加网络):在 underlay 之上用隧道虚拟出的网络,用于多租户隔离与大二层等语义。
VXLAN:把二层帧封装进 UDP/IP 的隧道技术,用 VNI 扩展租户规模。
EVPN:通常基于 BGP 的控制平面,用于分发 MAC/IP/VTEP 等信息来管理 VXLAN。
VTEP:VXLAN 隧道端点,负责对二层帧进行 VXLAN 封装与解封装(常在 Leaf 上)。
MTU:链路能承载的最大帧/包大小,封装(如 VXLAN)会吃掉 MTU 并影响性能与丢包风险。
IPAM:IP 地址规划、分配与回收的管理系统/流程,用于大规模网络避免冲突与混乱。
服务发现(Service Discovery):让客户端找到服务实例地址的机制(如 DNS/Consul/K8s Service)。
Anycast:多个节点共享同一 IP,由路由把流量送到“最近/最优”的节点以实现就近接入与高可用。
新知识很多,以上是涉及的部分概念,对话链接在这里:https://chats.pengs.top/NSDI_26_CAVER/DCN-WAN-ECMP.html
交换机内部
入队列(Ingress queueing):在入方向或共享缓存处对报文进行暂存排队,以等待内部资源或出口可用。
出队列(Egress queueing):在出端口按业务类/优先级排队,等待链路发送时隙并由调度器选择发出。
PHY:完成电/光信号与比特流之间的物理层转换。
MAC:负责以太网帧的收发、基本校验与链路层封装。
FCS/CRC:用于检测帧在传输过程中是否发生比特错误的校验字段/算法。
Parser(解析器):从报文头部提取字段以支撑后续分类、查表与处理。
Classifier(分类器):根据字段(如 VLAN、DSCP、端口等)把报文归入不同业务类/队列与策略。
元数据(metadata):交换机内部携带的“旁路信息”,记录报文应走的端口、优先级、策略动作等。
VLAN:用二层标签把同一物理网络划分成逻辑隔离的广播域。
VRF:在同一设备上隔离多套路由表,实现多租户/多网络实例。
二层交换(L2 switching):依据目的 MAC 查 MAC 表决定转发端口(未知则泛洪)。
MAC 表(转发表):记录 MAC 地址到端口的映射,用于二层转发决策。
泛洪(flooding):目的 MAC 未知或广播/多播时,将帧复制并发送到多个端口。
三层交换(L3 switching):依据目的 IP 查路由表选择下一跳与出端口并执行必要的头部改写。
路由表(routing table):记录前缀到下一跳/出接口的映射,用于三层转发。
邻接表/邻居表(adjacency/neighbor):缓存下一跳解析结果(如下一跳 MAC),减少逐包解析开销。
下一跳(next hop):三层转发时下一段链路要把包交付的邻居节点。
TTL-1:路由转发会将 IP TTL 减一以限制包在网络中无限循环。
镜像(mirroring):把特定流量复制一份发送到监控端口/采集系统用于分析。
ACL:按规则匹配报文并执行允许/拒绝/计数等动作的访问控制列表。
计数器(counters):统计丢包、队列深度、字节/包量等运行指标以便运维与调优。
准入控制(admission):决定报文是否允许进入缓冲/队列(不满足资源或策略则丢弃/标记)。
Policing(限速执法):对超出配置速率的流量进行丢弃或降级标记,以强制速率上限。
整形(shaping):通过排队延迟把突发流量平滑到目标速率,通常不直接丢包。
缓存/Buffer:用于暂存报文以吸收突发和速率不匹配导致的拥塞。
优先级/业务类(priority/class):把流量分层以提供差异化延迟、带宽与丢包策略。
CoS/TC:用来表达二层/内部的业务类别或流量类别,从而映射到不同队列与策略。
交换结构(Switching Fabric):负责把入端口的数据搬运到目标出端口的内部互连与仲裁系统。
共享内存(shared memory):所有端口共享一块物理缓存池以提高缓存利用率。
共享缓存(shared buffer):以共享内存形式为多个端口/队列动态分配缓存空间。
输入队列架构(input-queued):报文先在入端口排队,再争用交换结构转到对应出口。
输出队列架构(output-queued):报文理想化地直接进入出端口队列并由出口调度发送。
完全输出队列(ideal output-queued):要求交换机能以多写口/极高内部带宽把所有到达报文立刻写入目标出口队列。
读论文
额,还是新开一篇文章吧。这里已经有很多知识了,有很多是我看到ChatGPT回答里有我不知道的关键词,于是往下挖挖出来的。
希望这些知识能让我论文读起来不要太艰难
p.s. 好忙啊,最近要读论文,去新加坡,做航小伴,回来还准备组NAS。不过虽然忙,都是我感兴趣的,好耶!